Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
在本教程中,请使用 Azure 数据工厂用户界面 (UI) 创建数据工厂。 此数据工厂中的管道将数据从 Azure Blob 存储复制到 Azure SQL 数据库中的数据库。 本教程中的配置模式适用于从基于文件的数据存储复制到关系数据存储。 如需可以用作源和接收器的数据存储的列表,请参阅支持的数据存储表。
注意
如果对数据工厂不熟悉,请参阅 Azure 数据工厂简介。
将在本教程中执行以下步骤:
- 创建数据工厂。
- 创建包含复制活动的管道。
- 测试性运行管道。
- 手动触发管道。
- 按计划触发管道。
- 监视管道和活动运行。
- 禁用或删除计划的触发器。
先决条件
- Azure 订阅。 如果没有 Azure 订阅,请在开始前创建一个试用 Azure 帐户。
- Azure 存储帐户。 可将 Blob 存储用作源数据存储。 如果没有存储帐户,请参阅创建 Azure 存储帐户以获取创建步骤。
- Azure SQL 数据库。 将数据库用作接收器数据存储。 如果没有 Azure SQL 数据库中的数据库,请参阅在 Azure SQL 数据库中创建数据库了解创建步骤。
创建 blob 和 SQL 表
现在,请执行以下步骤来准备本教程所需的 Blob 存储和 SQL 数据库。
创建源 blob
启动记事本。 复制以下文本,并将其另存为 emp.txt 文件:
FirstName,LastName John,Doe Jane,Doe将该文件移动到名为输入的文件夹。
在 Blob 存储中创建名为 adftutorial 的容器。 请将包含emp.txt文件的输入文件夹上传到此容器。 可以使用 Azure 门户或 Azure 存储资源管理器 等工具执行这些任务。
创建接收器 SQL 表
使用以下 SQL 脚本在数据库中创建 dbo.emp 表:
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);允许 Azure 服务访问 SQL Server。 确保 SQL Server 的“允许访问 Azure 服务”处于“打开”状态,以便数据工厂可以将数据写入 SQL Server。 若要验证并启用此设置,请转到 Azure 门户中的 SQL Server,选择“启用安全>网络>”>,选中“允许 Azure 服务和资源访问例外”下的此服务器。
创建数据工厂
在此步骤中,请先创建数据工厂,然后启动数据工厂 UI,在该数据工厂中创建一个管道。
打开 Microsoft Edge 或 Google Chrome。 目前,仅 Microsoft Edge 和 Google Chrome Web 浏览器支持数据工厂 UI。
在左侧菜单中,选择“创建资源”“Analytics”>“数据工厂”。
在“创建数据工厂”页上的“基本”选项卡下,选择要在其中创建数据工厂的 Azure 订阅 。
对于“资源组”,请执行以下步骤之一:
a。 从下拉列表中选择现有资源组。
b. 选择“新建”,并输入新资源组的名称。
若要了解资源组,请参阅使用资源组管理 Azure 资源。
在“区域”下选择数据工厂所在的位置。 数据存储可以位于数据工厂以外的区域(如果需要)。
在 “名称”下,Azure 数据工厂的名称必须 全局唯一。 如果收到有关名称值的错误消息,请为数据工厂输入另一名称。 (例如,yournameADFDemo)。 有关数据工厂项目的命名规则,请参阅数据工厂命名规则。
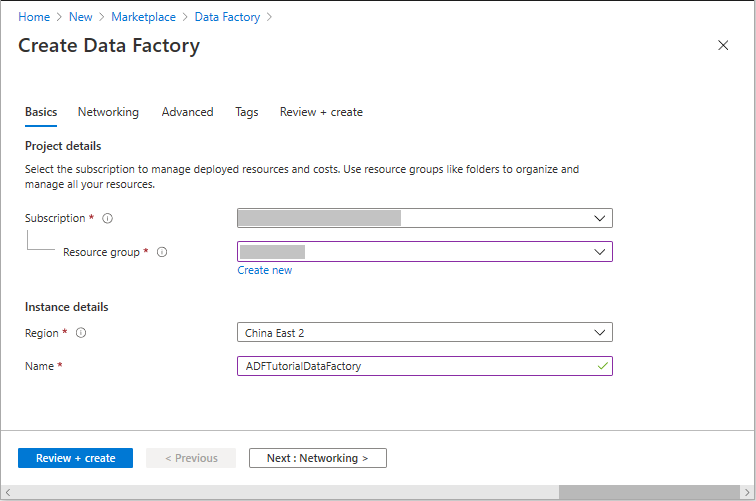
选择“查看 + 创建”,然后在通过验证后选择“创建” 。
创建完成后,通知中心内会显示通知。 选择“转到资源”导航到“数据工厂”页。
在 Azure 数据工厂工作室磁贴上选择“启动工作室”。
创建管道
本步骤在数据工厂中创建包含复制活动的管道。 复制活动将数据从 Blob 存储复制到 SQL 数据库。
在主页上,选择“协调”。
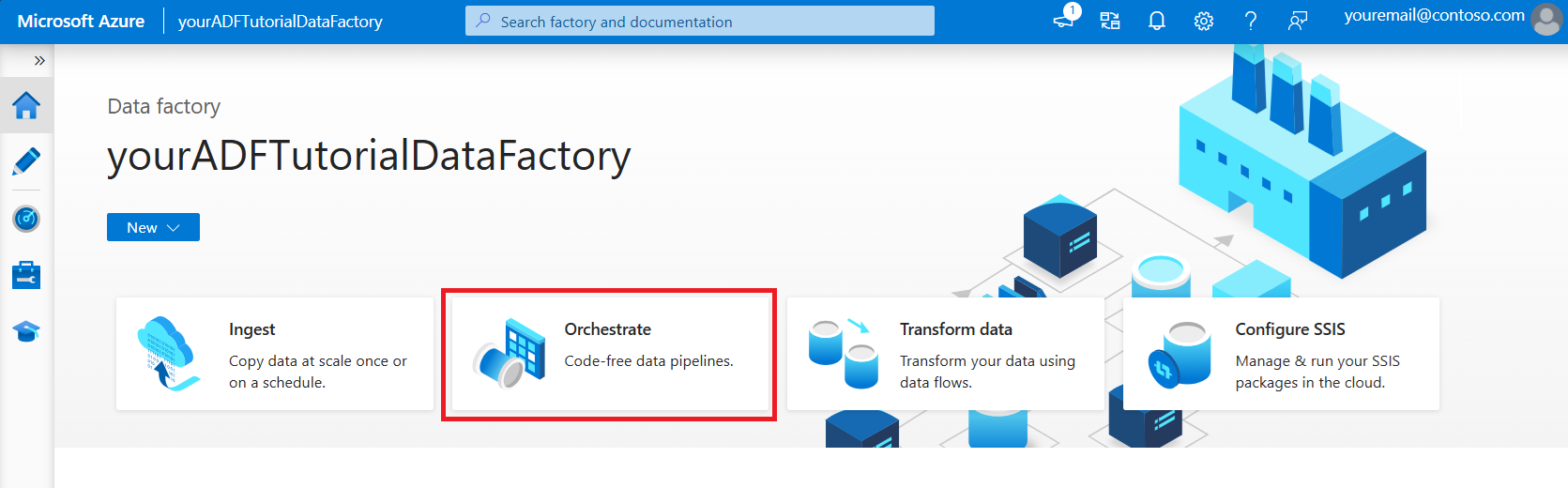
在“常规”面板的“属性”中,将名称指定为 CopyPipeline 。 然后通过单击右上角的“属性”图标来折叠面板。
在“活动”工具箱中,展开“移动和转换”类别,然后将“复制数据”活动从工具箱拖放到管道设计器图面。 指定 CopyFromBlobToSql 作为名称。
配置源
提示
在本教程中,你将 使用帐户密钥 作为源数据存储的身份验证类型,但你可以根据需要选择其他支持的身份验证方法: SAS URI、 服务主体和 托管标识 。 有关详细信息,请参阅此文中的相应部分。 为了安全地存储数据存储的机密,我们还建议使用 Azure Key Vault。 有关详细说明,请参阅此文。
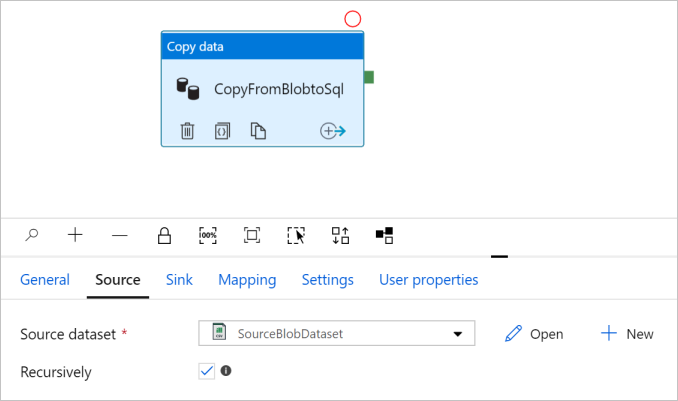
转到“源”选项卡。选择“+ 新建”创建源数据集。
在“新建数据集”对话框中选择“Azure Blob 存储”,然后选择“继续”。 源数据位于 Blob 存储中,因此选择“Azure Blob 存储”作为源数据集。
在 “选择格式 ”对话框中,选择 “带分隔符的文本”,然后选择“ 继续”。
在“设置属性”对话框中,输入 SourceBlobDataset 作为名称。 选中“第一行作为标题”复选框。 在“链接服务”文本框下,选择“+ 新建”。
在“新建链接服务(Azure Blob 存储)”窗口中,输入 AzureStorageLinkedService 作为名称,从“存储帐户名称”列表中选择你的存储帐户。 测试连接,选择“创建”以部署该链接服务。
创建链接服务后,会导航回到“设置属性”页。 在“文件路径”旁边,选择“浏览”。
导航到 adftutorial/input 文件夹,选择 emp.txt 文件,然后选择“确定”。
选择“确定” 。 将自动导航到管道页。 在“源”选项卡中,确认已选择“SourceBlobDataset”。 若要预览此页上的数据,请选择“预览数据”。
配置接收器
提示
本教程使用“SQL 身份验证”作为接收器数据存储的身份验证类型,但你可以根据需要选择其他受支持的身份验证方法:“服务主体”和“托管标识”。 有关详细信息,请参阅此文中的相应部分。 为了安全地存储数据存储的机密,我们还建议使用 Azure Key Vault。 有关详细说明,请参阅此文。
转到“接收器”选项卡,选择“+ 新建”,创建一个接收器数据集。
在“新建数据集”对话框中的搜索框内输入“SQL”来筛选连接器,选择“Azure SQL 数据库”,然后选择“继续”。
在“设置属性”对话框中,输入 OutputSqlDataset 作为名称。 从“链接服务”下拉列表中,选择“+ 新建”。 数据集必须与链接服务相关联。 链接的服务包含数据工厂在运行时用于连接到 SQL 数据库的连接字符串,并指定数据复制的位置。
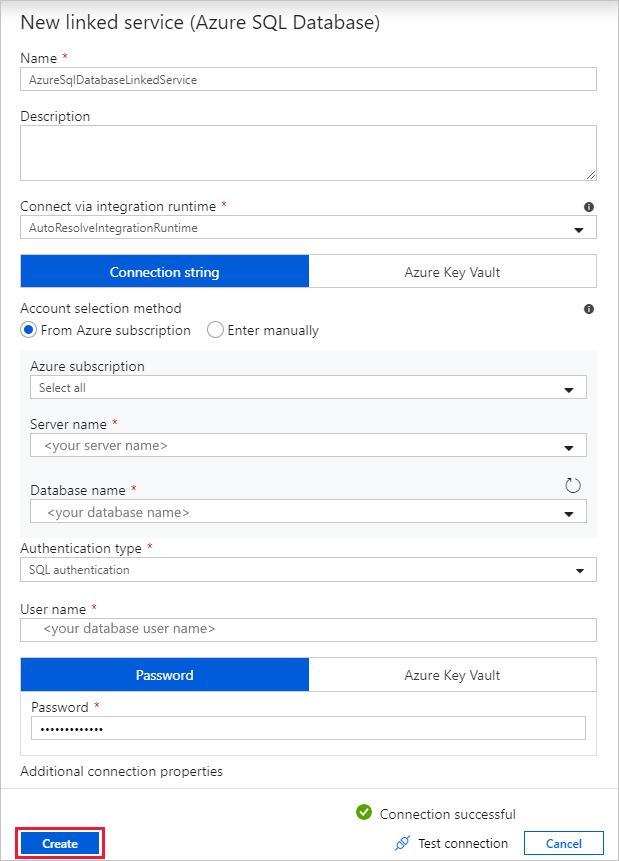
在“新建链接服务(Azure SQL 数据库)”对话框中执行以下步骤:
a。 在“名称”下输入 AzureSqlDatabaseLinkedService。
b. 在“服务器名称”下选择 SQL Server 实例。
选项c. 在“数据库名称”下选择数据库。
d。 在“用户名”下输入用户的名称。
e。 在“密码”下输入用户的密码。
f。 选择“测试连接”以测试连接。
g。 选择“创建”以部署链接服务。
将自动导航到“设置属性”对话框。 在表中,选择手动输入,然后输入[dbo].[emp]。 然后选择“确定”。
转到包含管道的选项卡。在“接收器数据集”中,确认已选中“OutputSqlDataset”。
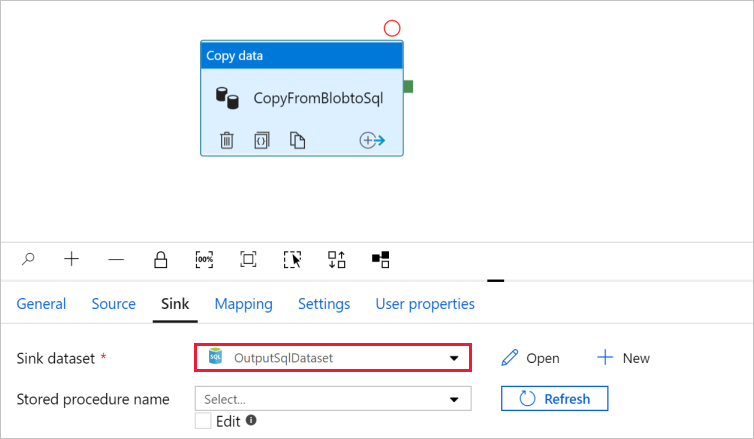
可以选择按照复制活动中的架构映射中所述将源架构映射到对应的目标架构。
验证管道
若要验证管道,请从工具栏中选择“验证” 。
可以通过单击右上角的“代码”来查看与管道关联的 JSON 代码。
调试和发布管道
可以先调试管道,然后再将项目(链接服务、数据集和管道)发布到数据工厂。
若要调试管道,请在工具栏上选择“调试”。 可以在窗口底部的“输出”选项卡中看到管道运行的状态。
在管道可以成功运行后,在顶部工具栏中选择“全部发布”。 此操作将所创建的实体(数据集和管道)发布到数据工厂。
等待直到你看到 已成功发布的 通知消息。 若要查看通知消息,请选择右上角的 “显示通知 ”(铃铃按钮)。
手动触发管道
在此步骤中,请手动触发在前面的步骤中发布的管道。
在工具栏上选择 “添加触发器 ”,然后选择“ 立即触发”。
在“管道运行”页上,选择“确定”。
转到左侧的“监视”选项卡。 此时会看到由手动触发器触发的管道运行。 可以使用“管道名称”列下的链接来查看活动详细信息以及重新运行该管道。

若要查看与管道运行关联的活动运行,请选择“管道名称”列下的“CopyPipeline”链接。 此示例中只有一个活动,因此列表中只看到一个条目。 有关复制操作的详细信息,请选择“活动名称”列下的“详细信息”链接(眼镜图标)。 选择顶部的“所有管道运行”,回到“管道运行”视图。 若要刷新视图,请选择“刷新”。

验证是否又向数据库的 emp 表添加了两行。

按计划触发管道
在此计划中,请为管道创建计划触发器。 触发器按指定的计划(例如,每小时或每天)运行管道。 此处,你要将触发器设置为每分钟运行一次,直至指定的结束日期/时间。
转到左侧位于“监视器”选项卡上方的“创作”选项卡。
转到管道,选择工具栏上的 “触发器 ”,然后选择“ 新建/编辑”。
在“ 添加触发器 ”对话框中,选择“ 选择触发器 ”,然后选择“ + 新建”。
在“新建触发器”窗口中,执行以下步骤:
a。 在“名称”下输入 RunEveryMinute。
b. 更新触发器的“开始日期”。 如果该日期早于当前日期/时间,则触发器会在所做的更改发布之后开始生效。
选项c. 在“时区”下选择下拉列表。
d。 将“重复周期”设置为“每分钟一次” 。
e。 选择“指定结束日期”复选框,将“结束时间”部分更新为晚于当前日期/时间几分钟 。 触发器只会在发布所做的更改后激活。 如果将其设置为仅数分钟后激活,而到时又不进行发布,则看不到触发器运行。
f。 对于“已激活”选项,请选择“是”。
g。 选择“确定” 。
重要
每个管道运行都有相关联的成本,因此请正确设置结束日期。
在“编辑触发器”页中查看警告,然后选择“保存”。 此示例中的管道不采用任何参数。
选择“ 全部发布 ”以发布更改。
转到左侧的“监视”选项卡,查看触发的管道运行。

若要从“管道运行”视图切换到“触发器运行”视图,请选择窗口左侧的“触发器运行”。
可以在列表中看到触发器运行。
验证是否每分钟将两个行(对于每个管道运行)插入 emp 表中,直至指定的结束时间。
禁用触发器
若要禁用你创建的每分钟触发器,请执行以下步骤:
选择左侧的 “管理 ”窗格。
在 “作者 ”下选择 “触发器”。
将鼠标悬停在创建的 RunEveryMinute 触发器上。
- 选择 “停止 ”按钮以禁用触发器运行。
- 选择“ 删除 ”按钮以禁用并删除触发器。
选择“全部发布”以保存更改。
相关内容
此示例中的管道将数据从 Blob 存储中的一个位置复制到另一个位置。 你已了解如何:
- 创建数据工厂。
- 创建包含复制活动的管道。
- 测试性运行管道。
- 手动触发管道。
- 按计划触发管道。
- 监视管道和活动运行。
- 禁用或删除计划的触发器。
若要了解如何将数据从本地复制到云,请转到以下教程:
有关将数据复制到 Azure Blob 存储和 Azure SQL 数据库或从 Azure SQL 数据库复制数据的详细信息,请参阅以下连接器指南: