Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
在本教程中,你将创建一个包含管道的Azure Data Factory,该管道将增量数据从SQL Server数据库中的多个表加载到Azure SQL Database中的数据库。
在本教程中执行以下步骤:
- 准备源和目标数据存储。
- 创建数据工厂。
- 创建自我托管的集成运行时。
- 安装 Integration Runtime。
- 创建链接服务。
- 创建源、接收器和水印数据集。
- 创建、运行和监视管道。
- 查看结果。
- 在源表中添加或更新数据。
- 重新运行和监控流水线。
- 查看最终结果。
概述
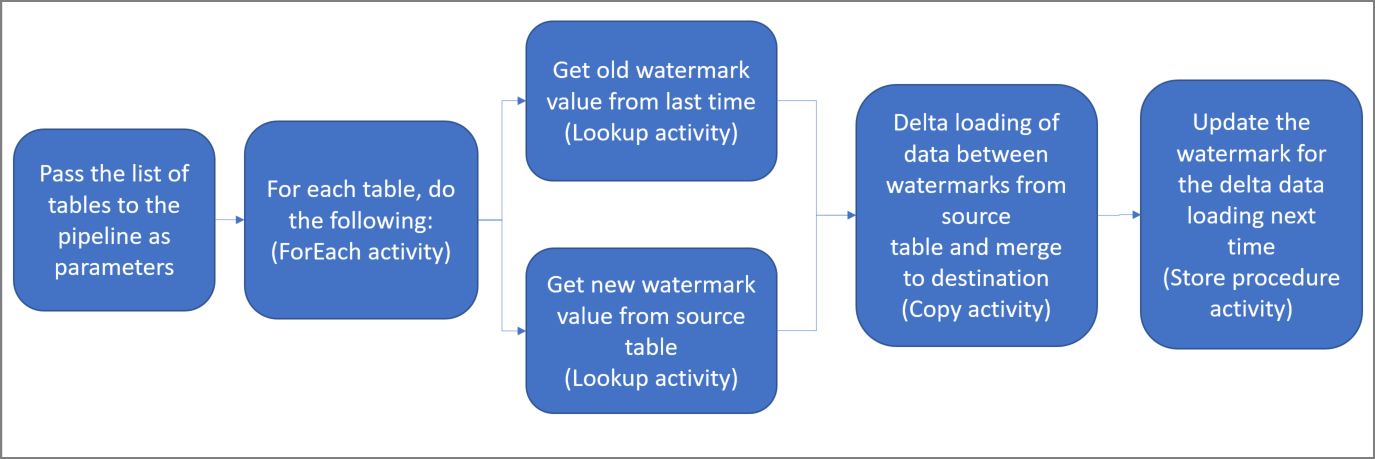
下面是创建此解决方案所要执行的重要步骤:
选择水印列。
在源数据存储中为每个表选择一个列,该列可用于确定每个运行的新记录或已更新记录。 通常,在创建或更新行时,此选定列中的数据(例如 last_modify_time 或 ID)会不断递增。 此列中的最大值用作水印。
准备用于存储水印值的数据存储。
在本教程中,你将把水印值存储在一个 SQL 数据库中。
创建包含以下活动的管道:
a。 创建一个 ForEach 活动,循环处理作为参数传递到管道的源表名称列表。 对于每个源表,它会调用以下活动,为该表执行增量加载。
b. 创建两个 Lookup 活动。 使用第一个查找活动检索最后一个水印值。 使用第二个 Lookup 活动检索新的水印值。 这些水印值将传递给Copy activity。
选项c. 创建一个复制活动,从源数据存储中复制行,其中水印列的值大于旧水印值并且小于新水印值。 然后,它会将源数据存储中的增量数据作为新文件复制到Azure Blob 存储。
d。 创建 StoredProcedure 活动,用于更新下一次运行的管道的水印值。
下面是高级解决方案示意图:
如果没有Azure订阅,请在开始前创建 trial 帐户。
先决条件
- SQL Server。 本教程使用 SQL Server 数据库作为源数据存储。
-
Azure SQL Database。 在 Azure SQL Database 中使用数据库作为接收器数据存储。 如果没有 SQL 数据库中的数据库,请参阅
在 Azure SQL Database 获取创建一个数据库的步骤。
在 SQL Server 数据库中创建源表
打开SQL Server Management Studio并连接到SQL Server数据库。
在“服务器资源管理器”中,右键单击数据库,然后选择“新建查询”。
对数据库运行以下 SQL 命令,以便创建名为
customer_table和project_table的表:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
在数据库中创建目标表
打开SQL Server Management Studio,并在Azure SQL Database中连接到数据库。
在“服务器资源管理器”中,右键单击数据库,然后选择“新建查询”。
对数据库运行以下 SQL 命令,以便创建名为
customer_table和project_table的表:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
在数据库中再创建一个表来存储高水印值
针对数据库运行以下 SQL 命令,创建一个名为
watermarktable的表来存储水印值:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );将两个源表的初始水印值插入水印表中。
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
在数据库中创建一个存储流程
运行以下命令,在数据库中创建存储过程。 此存储过程在每次管道运行后更新水印值。
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
在数据库中创建数据类型和其他存储流程
运行以下查询,在数据库中创建两个存储过程和两个数据类型。 以便将源表中的数据合并到目标表中。
为了方便入门,我们直接使用这些存储过程通过表变量来传入增量数据,然后将其合并到目标存储中。 请谨慎,系统不可预计需要在表变量中存储大量的增量行(超过 100 行)。
如果需要将大量增量行合并到目标存储中,建议先使用复制活动将所有增量数据复制到目标存储中的临时“临时”表中,然后生成自己的存储过程,而无需使用表变量将它们从“暂存”表合并到“最终”表。
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
创建数据工厂
启动 Microsoft Edge 或 Google Chrome Web 浏览器。 目前,数据工厂 UI 仅在 Microsoft Edge 和 Google Chrome Web 浏览器中受支持。
在顶部菜单中,选择“ 创建资源>数据 + 分析>数据工厂 ” :
在“新建数据工厂”页中,输入 ADFMultiIncCopyTutorialDF 作为名称。
Azure 数据工厂的名称必须全球唯一。 如果看到红色感叹号和以下错误,请更改数据工厂的名称(例如改为 yournameADFIncCopyTutorialDF),并重新尝试创建。 有关数据工厂项目命名规则,请参阅数据工厂 - 命名规则一文。
Data factory name "ADFIncCopyTutorialDF" is not available选择要在其中创建数据工厂的 Azure 订阅。
对于资源组,请执行以下步骤之一:
- 选择“使用现有资源组”,并从下拉列表选择现有的资源组。
- 选择“新建”,并输入资源组的名称。
若要了解资源组,请参阅 使用资源组来管理Azure资源。
选择数据工厂的位置。 下拉列表中仅显示支持的位置。 数据工厂使用的数据存储(Azure Storage、Azure SQL Database等)和计算(HDInsight 等)可以位于其他区域。
单击创建。
创建完成后,可以看到图中所示的“数据工厂”页。
在 Open Azure Data Factory Studio 磁贴上选择 Open,以在单独的浏览器标签页中启动 Azure Data Factory 用户界面 (UI)。
创建自托管的 Integration Runtime
将数据从专用网络(本地)中的数据存储移动到Azure数据存储时,请在本地环境中安装自承载集成运行时(IR)。 自承载 IR 在专用网络和Azure之间移动数据。
在 Azure Data Factory UI 的主页上,从最左侧的窗格中选择 Manage 选项卡。
在左窗格中选择“集成运行时”,然后选择“+ 新建” 。
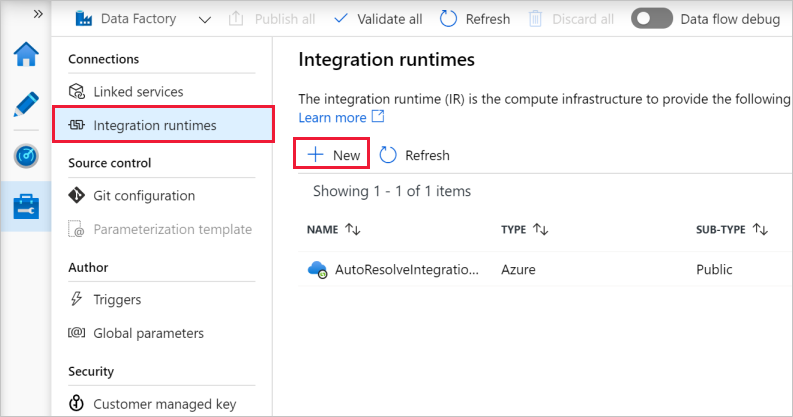
在Integration Runtime安装程序窗口中,选择执行数据移动并将活动调度到外部计算,然后单击Continue。
选择“自托管”,然后单击“继续”。
在“名称”中输入 MySelfHostedIR,然后单击“创建”。
在“选项 1: 快速安装”部分中单击“单击此处对此计算机启动快速安装” 。
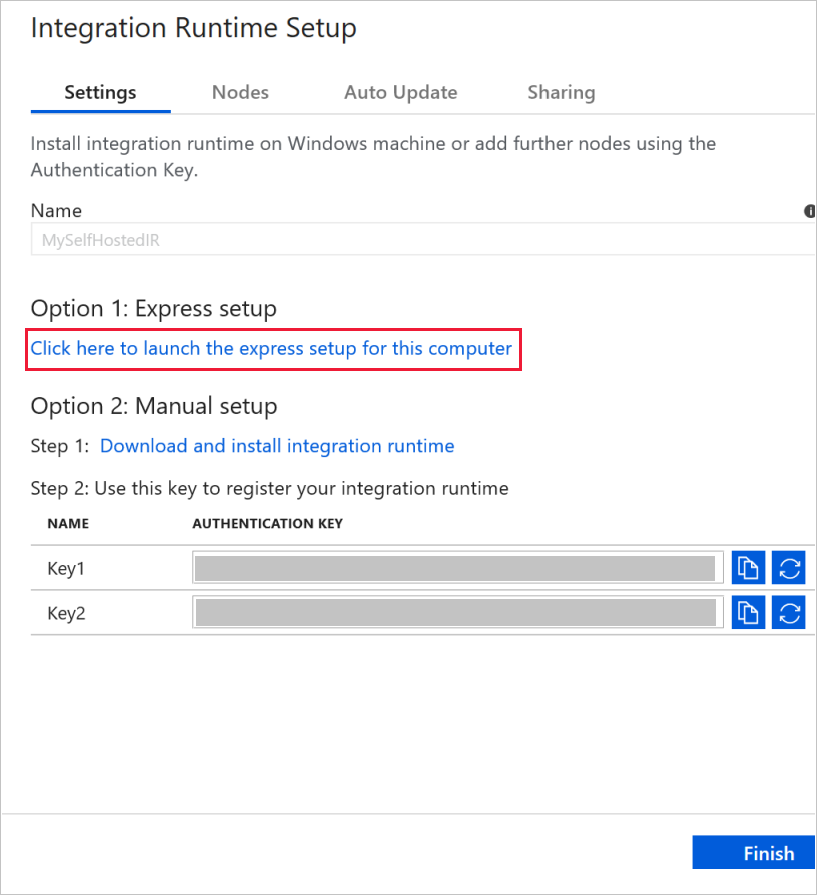
在 Integration Runtime (自托管) Express Setup 窗口中,单击Close。
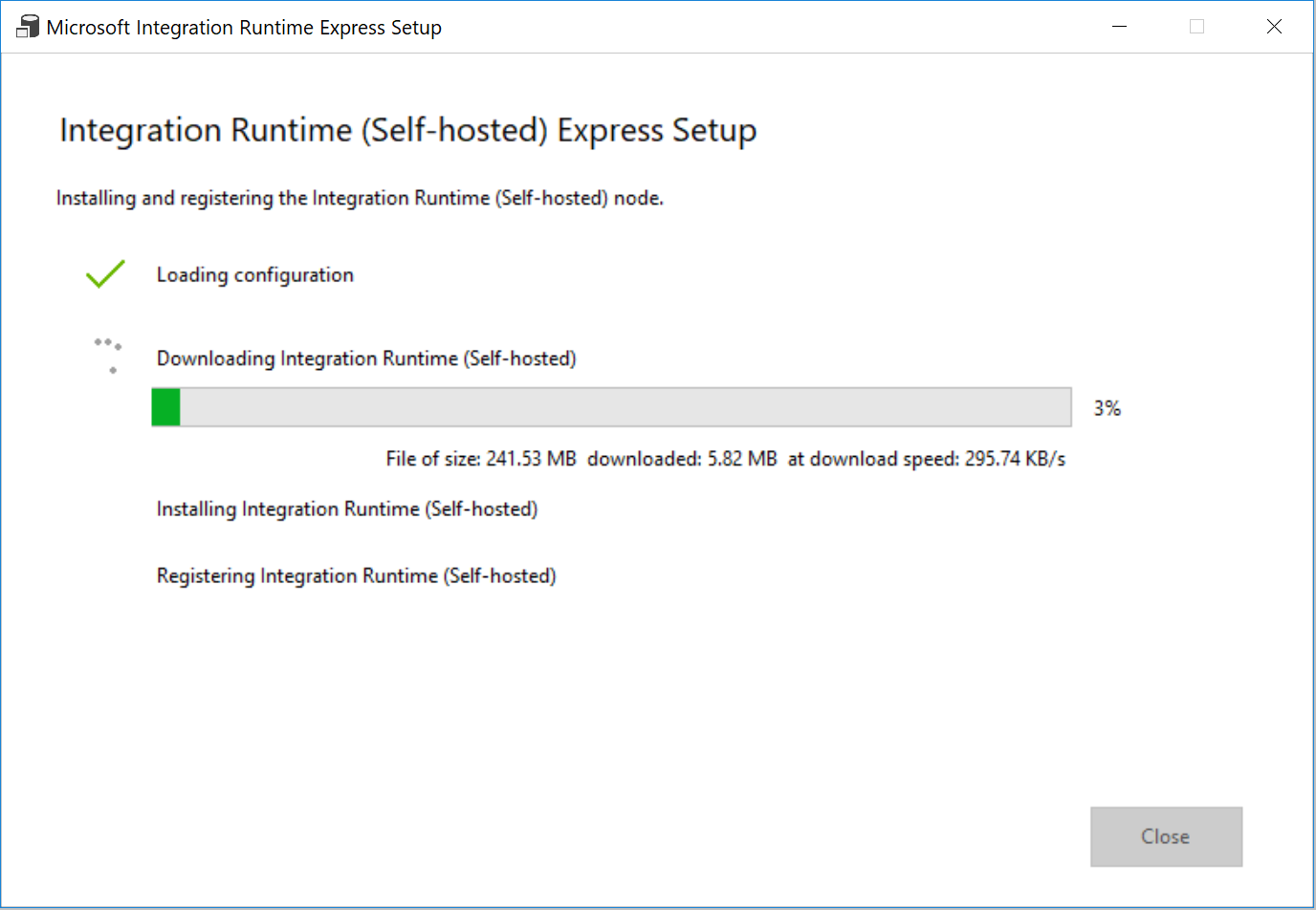
在 Web 浏览器中,在 Integration Runtime Setup 窗口中,单击 Finish。
确认在 Integration Runtime 的列表中看到 MySelfHostedIR。
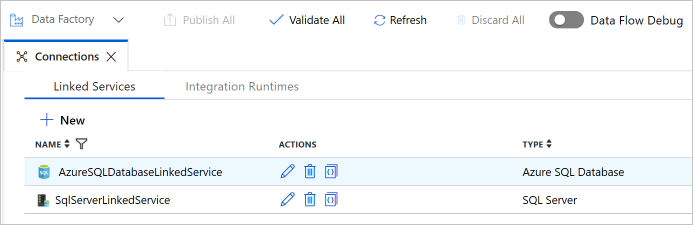
创建链接服务
可在数据工厂中创建链接服务,将数据存储和计算服务链接到数据工厂。 在本部分中,您将为您的 SQL Server 数据库和 Azure SQL 数据库中的数据库创建链接服务。
创建SQL Server链接服务
在此步骤中,将SQL Server数据库链接到数据工厂。
在“连接”窗口中从“Integration Runtime”选项卡切换到“链接服务”选项卡,然后单击“+ 新建”。
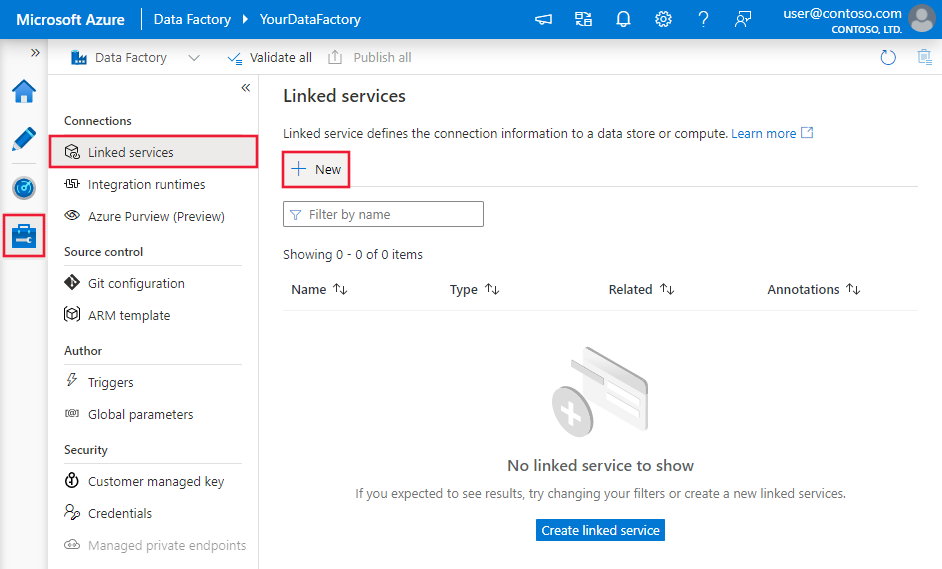
在“新建链接服务窗口中,选择SQL Server,然后单击Continue。
在“新建链接服务”窗口中执行以下步骤:
- 输入 SqlServerLinkedService 作为名称。
- 为“通过集成运行时连接”选择“MySelfHostedIR”。 这是重要步骤。 默认的 Integration Runtime 无法连接到本地数据存储。 使用前面创建的自承载集成运行时。
- 对于 Server 名称,请输入具有SQL Server数据库的计算机的名称。
- 对于 Database 名称,请在具有源数据的SQL Server中输入数据库的名称。 已按照先决条件创建一个表并将数据插入到此数据库中。
- 对于“身份验证类型”,请选择需要用于连接到数据库的身份验证的类型。
- 对于 User name,请输入有权访问 SQL Server 数据库的用户名。 如需在用户帐户或服务器名称中使用斜杠字符 (
\),请使用转义字符 (\)。 示例为mydomain\\myuser。 - 至于“密码”,请输入用户的密码。
- 若要测试数据工厂是否可以连接到SQL Server数据库,请单击测试连接。 修复任何错误,直到连接成功。
- 若要保存链接服务,请单击“完成”。
创建Azure SQL Database链接服务
在最后一步中,创建链接服务,将源SQL Server数据库链接到数据工厂。 在该步骤中,要将目标/汇集数据库连接到数据工厂。
在“连接”窗口中从“Integration Runtime”选项卡切换到“链接服务”选项卡,然后单击“+ 新建”。
在“新链接服务窗口中,选择Azure SQL Database,然后单击Continue。
在“新建链接服务”窗口中执行以下步骤:
- 对于名称字段,输入AzureSqlDatabaseLinkedService。
- 至于“服务器名称”,请从下拉列表中选择服务器的名称。
- 对于数据库名称,请选择满足先决条件的数据库,其中您创建了 customer_table 和 project_table。
- 对于“用户名”,请输入有权访问该数据库的用户的姓名。
- 至于“密码”,请输入用户的密码。
- 若要测试数据工厂是否可以连接到SQL Server数据库,请单击测试连接。 修复任何错误,直到连接成功。
- 若要保存链接服务,请单击“完成”。
确认在列表中显示两个关联服务。
创建数据集
在此步骤中,请创建多个数据集,分别表示数据源、数据目标以及用于存储水印的位置。
创建源数据集
在左窗格中单击“+ (加)”,然后单击“数据集”。
在新建数据集窗口中,选择SQL Server,单击Continue。
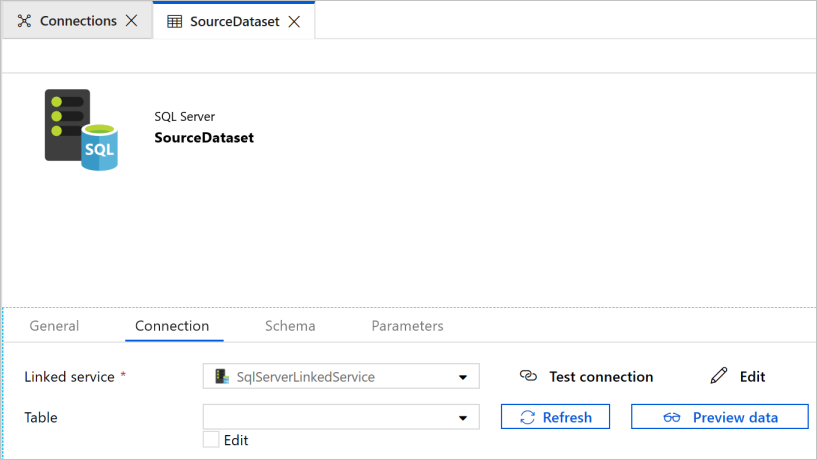
此时会在 Web 浏览器中看到打开的新选项卡,用于配置数据集。 树状视图中也会看到数据集。 在底部属性窗口的 General 选项卡中,输入 SourceDataset 作为 Name。
切换到Properties window中的 Connection 选项卡,然后选择 SqlServerLinkedService for Linked service。 您未选择此处的表。 管道中的Copy activity使用 SQL 查询来加载数据,而不是加载整个表。
创建接收器数据集
在左窗格中单击“+ (加)”,然后单击“数据集”。
在新建数据集窗口中,选择Azure SQL Database,然后单击Continue。
此时会在 Web 浏览器中看到打开的新选项卡,用于配置数据集。 树状视图中也会看到数据集。 在底部Properties window的 General 选项卡中,输入 SinkDataset for Name。
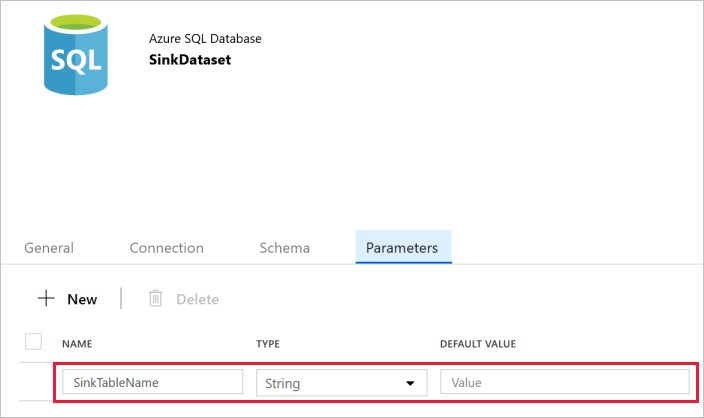
切换到Properties window中的 Parameters 选项卡,然后执行以下步骤:
在“创建/更新参数”部分单击“新建”。
输入 SinkTableName 作为名称,String 作为类型。 此数据集采用 SinkTableName 作为参数。 SinkTableName 参数由管道在运行时动态设置。 管道中的 ForEach 活动循环访问一个包含表名的列表,每一次迭代都将表名传递到此数据集。
切换到Properties window中的 Connection 选项卡,然后选择 AzureSqlDatabaseLinkedService for Linked service。 对于“表”属性,单击“添加动态内容”。
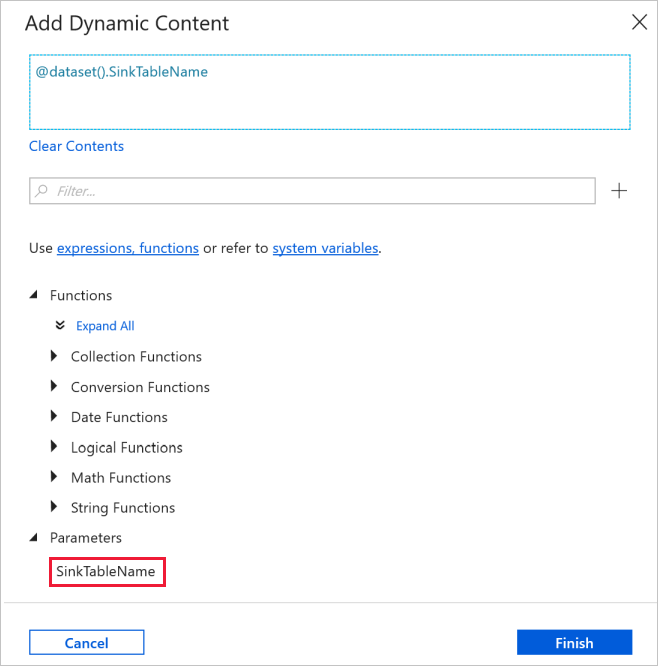
在“添加动态内容”窗口的“参数”部分中选择 SinkTableName。
单击“完成”后,可以看到表名为“@dataset().SinkTableName”。
为水印创建数据集
在此步骤中,您需创建一个数据集,用于存储高水位标值。
在左窗格中单击“+ (加)”,然后单击“数据集”。
在新建数据集窗口中,选择Azure SQL Database,然后单击Continue。
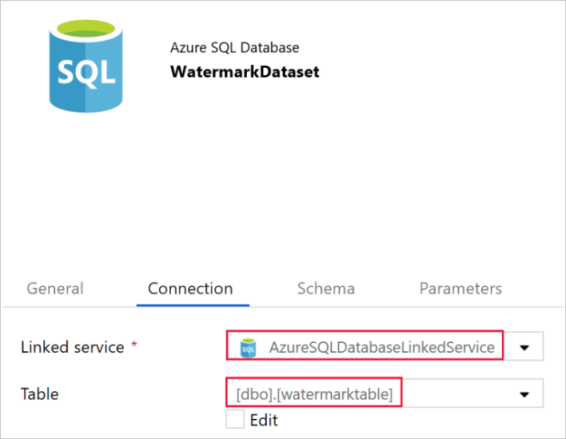
在底部Properties window的 General 选项卡中,输入 WatermarkDataset for Name。
切换到“连接”选项卡,然后执行以下步骤:
为“链接服务”选择“AzureSqlDatabaseLinkedService”。
选择[dbo].[watermarktable]作为表Table。
创建管道
此管道使用表名列表作为参数。 ForEach 活动遍历表名列表,并执行以下操作:
通过 Lookup 活动检索旧的水印值(初始值或上次迭代中使用的值)。
通过 Lookup 活动检索新的水印值(源表中水印列的最大值)。
使用Copy活动将在这两个水印值之间的数据从源数据库复制到目标数据库。
使用 StoredProcedure 活动来更新旧的水印值,以便在下一次迭代的第一步中使用。
创建管道
在左窗格中单击“+ (加)”,然后单击“管道”。
在“常规”面板的“属性”中,将 名称 指定为 IncrementalCopyPipeline。 然后通过单击右上角的“属性”图标来折叠面板。
在“参数”选项卡中,执行以下步骤:
- 单击“+ 新建”。
- 输入 tableList 作为参数名称。
- 选择数组作为参数类型。
在“活动”工具箱中展开“迭代和条件语句”,然后将 ForEach 活动拖放到管道设计器界面。 在属性窗口的“常规”选项卡中,输入 IterateSQLTables。
切换到“设置”选项卡,并在项目中输入
@pipeline().parameters.tableList。 ForEach 活动循环访问一系列表,并执行增量复制操作。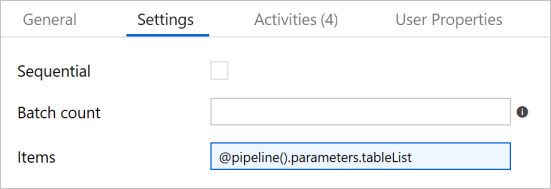
在管道中选择 ForEach 活动(如果尚未选择)。 单击“编辑(铅笔图标)”按钮。
在活动工具箱中展开常规,将查找活动拖放到管道设计器表面,然后输入LookupOldWaterMarkActivity作为名称。
在“属性”窗口中切换到“设置”选项卡,然后执行以下步骤:
选择“WatermarkDataset”作为“源数据集”。
选择查询以便使用查询。
为 Query 输入以下 SQL 查询。
select * from watermarktable where TableName = '@{item().TABLE_NAME}'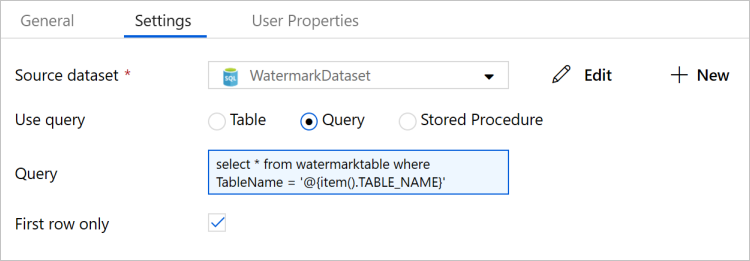
从“活动”工具箱拖放查找活动,然后输入 LookupNewWaterMarkActivity 作为名称。
切换到“设置”选项卡。
选择SourceDataset作为源数据集。
选择查询以便使用查询。
为 Query 输入以下 SQL 查询。
select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}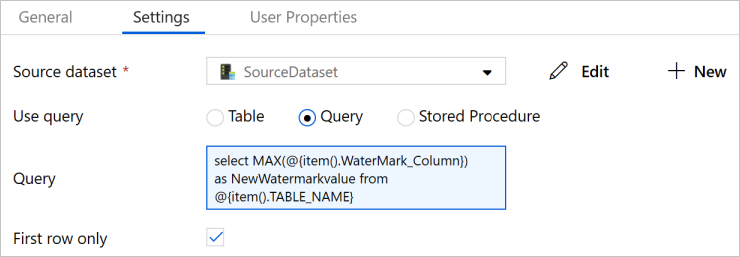
从“活动”工具箱拖放复制活动,然后输入 IncrementalCopyActivity 作为名称。
逐个地将“查找”活动连接到“复制”活动。 要连接,请从附加到查找活动的绿色框开始拖动,并放到复制活动上。 当Copy activity边框颜色更改为 blue 时释放鼠标按钮。
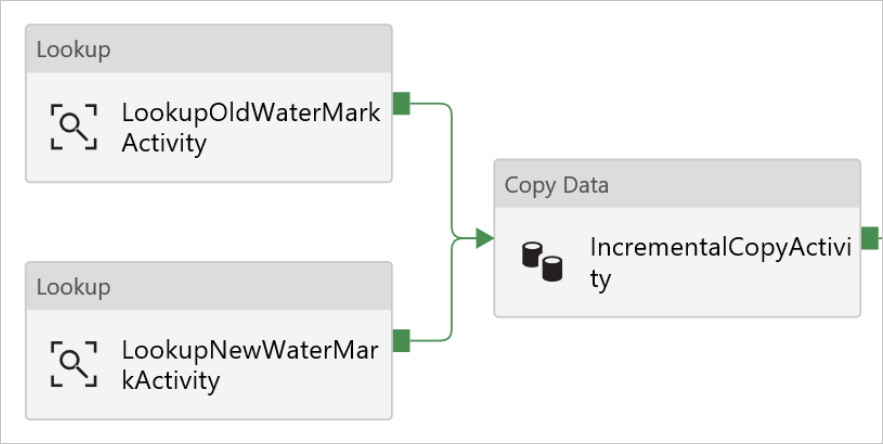
选择管道中的“复制操作”。 切换到“属性”窗口中的“源”选项卡。
选择SourceDataset作为源数据集。
选择查询以便使用查询。
为 Query 输入以下 SQL 查询。
select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'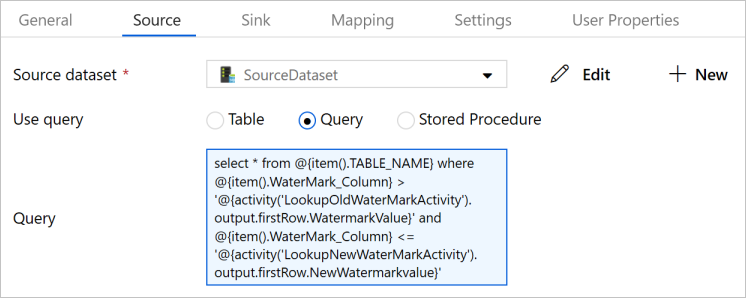
切换到“接收器”选项卡,然后选择“SinkDataset”作为“接收器数据集”。
执行以下步骤:
在“数据集”属性中,对于SinkTableName参数,输入。
对于“存储过程名称”属性,输入 。
对于“表类型”属性,请输入 。
对于“表类型参数名称”,请输入 。
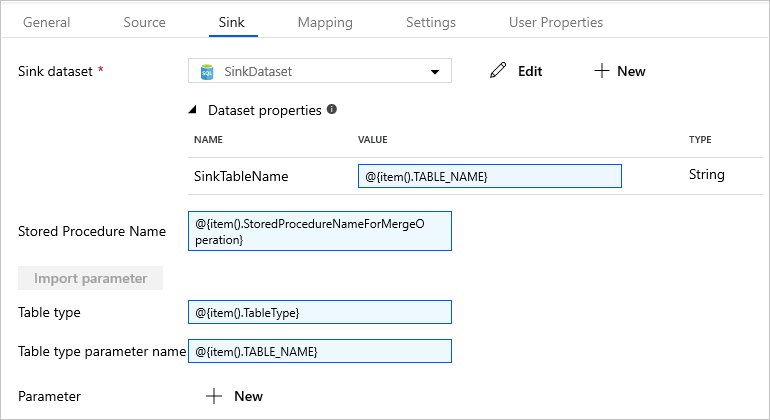
将Stored Procedure活动从Activities工具箱拖放到管道设计器画布。 将“复制”活动连接到“存储过程”活动。
在管道中选择存储过程活动,然后在属性窗口的常规选项卡中为名称输入StoredProceduretoWriteWatermarkActivity。
切换到SQL 帐户选项卡,然后在“链接服务”中选择AzureSqlDatabaseLinkedService。

切换到“存储过程”选项卡,然后执行以下步骤:
在存储过程名称中,选择
[dbo].[usp_write_watermark]。选择“导入参数”。
指定以下参数值:
名称 类型 值 上次修改时间 日期时间 @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}数据表名称 字符串 @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}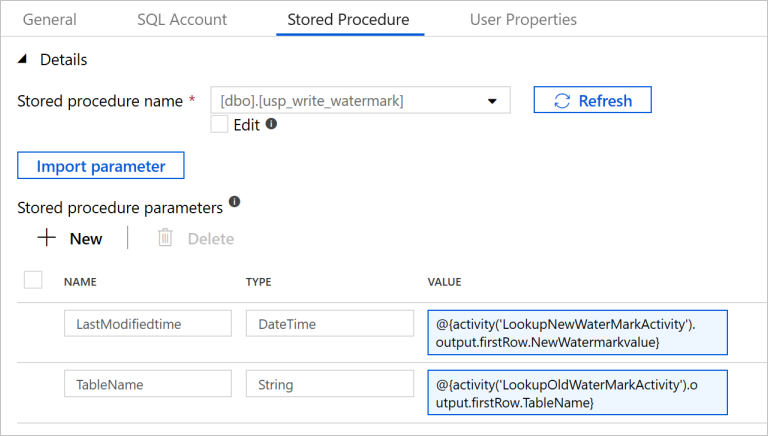
选择“全部发布”,以便将创建的实体发布到数据工厂服务。
等待“已成功发布”消息出现。 若要查看通知,请单击“显示通知”链接。 单击“X”关闭通知窗口。
运行流水线
在管道的工具栏中单击“添加触发器”,然后单击“立即触发”。
在“管道运行”窗口中,输入以下值作为 tableList 参数,然后单击“完成”。
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]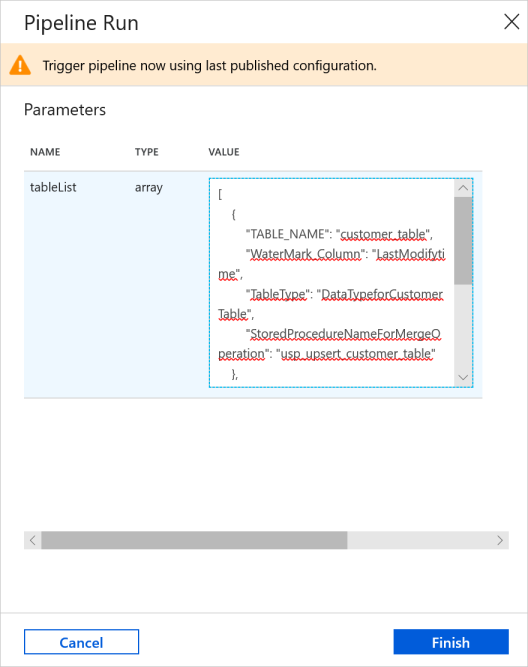
监视管道
在左侧切换到“监视”选项卡。 您可以看到手动触发器触发的管道运行。 可以使用“管道名称”列下的链接来查看活动详细信息以及重新运行该管道。
若要查看与管道运行关联的活动运行记录,请选择“管道名称”列下方的链接。 有关活动运行的详细信息,请选择“活动名称”列下的“详细信息”链接(眼镜图标) 。
选择顶部的“所有管道运行”,回到“管道运行”视图。 若要刷新视图,请选择“刷新”。
查看结果
在SQL Server Management Studio中,针对目标 SQL 数据库运行以下查询,以验证是否已将数据从源表复制到目标表:
查询
select * from customer_table
输出
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
查询
select * from project_table
输出
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
查询
select * from watermarktable
输出
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
请注意,已更新这两个表的水印值。
向源表中添加更多数据
针对源SQL Server数据库运行以下查询,以更新customer_table中的现有行。 将新行插入到 project_table 中。
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
重新运行管道
在 Web 浏览器窗口中,切换到左侧的“编辑”选项卡。
在管道的工具栏中单击“添加触发器”,然后单击“立即触发”。
在“管道运行”窗口中,输入以下值作为 tableList 参数,然后单击“完成”。
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]
再次监视管道
在左侧切换到“监视”选项卡。 您可以看到手动触发器触发的管道运行。 可以使用“管道名称”列下的链接来查看活动详细信息以及重新运行该管道。
若要查看与管道运行关联的活动运行记录,请选择“管道名称”列下方的链接。 有关活动运行的详细信息,请选择“活动名称”列下的“详细信息”链接(眼镜图标) 。
选择顶部的“所有管道运行”,回到“管道运行”视图。 若要刷新视图,请选择“刷新”。
查看最终结果
在SQL Server Management Studio中,针对目标 SQL 数据库运行以下查询,以验证是否已将更新/新数据从源表复制到目标表。
查询
select * from customer_table
输出
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
请注意编号为 3 的 PersonID 的 Name 和 LastModifytime 新值。
查询
select * from project_table
输出
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
请注意,已将 NewProject 条目添加到 project_table。
查询
select * from watermarktable
输出
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
请注意,已更新这两个表的水印值。
相关内容
已在本教程中执行了以下步骤:
- 准备源和目标数据存储。
- 创建数据工厂。
- 创建自托管集成运行时 (IR)。
- 安装 Integration Runtime。
- 创建链接服务。
- 创建源、接收器和水印数据集。
- 创建、运行和监视管道。
- 查看结果。
- 在源表中添加或更新数据。
- 重新运行和监控流水线。
- 查看最终结果。
转到以下教程,了解如何在 Azure 上使用 Spark 群集转换数据: