Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure 事件中心是一个完全托管的实时数据流式处理平台,每秒可以引入数百万个低延迟的事件。 作为具有内置 Apache Kafka 兼容性的本机Azure服务,事件中心使你可以运行现有的 Kafka 工作负载,而无需更改代码或群集管理开销。
组织使用事件中心,为 IoT 遥测、应用程序日志记录、点击流分析、财务交易处理以及其他需要高吞吐量且可靠事件引入的方案构建数据管道。 事件中心与Azure分析服务集成,以实现实时见解和长期数据保留。
速览
| Attribute | 详细信息 |
|---|---|
| 服务类型 | 完全托管的事件流式处理平台 (PaaS) |
| 支持的协议 | Apache Kafka、AMQP 1.0、HTTPS |
| 数据保留 | 最多 7 天(标准)、90 天(高级版) |
| 定价层 | 标准版、高级版 |
| SLA | 高达 99.99% |
为什么选择Azure 事件中心?
- 零基础设施管理:完全托管服务,具有自动修补、扩展和监控功能。 没有要配置或维护的群集。
- 企业级可靠性:高达 99.99% SLA,可用性区域支持业务连续性。
- 没有复杂性的 Kafka:以更高的成本效益运行 Kafka 工作负载,同时没有运营开销。 不需要单独的 Kafka 群集。
- Seamless Azure 集成:原生与 Stream Analytics、Azure Functions、数据资源管理器 和其他许多 Azure 服务集成。
- 灵活的定价:从基于消耗的容量模型中进行选择。 根据需求从兆字节扩展到 TB。

何时使用事件中心
事件中心专为高吞吐量、低延迟的事件流式处理方案而设计。 当您需要以下情况时,请考虑使用事件中心:
| Scenario | Description |
|---|---|
| 实时分析 | 处理流数据以生成即时见解、仪表板和警报 |
| IoT 遥测引入 | 从数百万个 IoT 传感器、车辆或工业设备收集设备数据 |
| 应用程序日志记录 | 集中分布式应用程序中的日志进行监视和故障排除 |
| 点击流分析 | 跨 Web 和移动应用程序分析用户行为模式 |
| 财务交易 | 处理大量交易数据、欺诈检测信号和付款事件 |
| 事件溯源 | 使用持久有序事件存储实现事件驱动架构 |
在Azure消息传送服务之间进行选择
Azure提供多个消息传送服务。 使用本指南选择正确的服务:
| 服务 | 最适用于 | 消息模式 |
|---|---|---|
| 事件中心 | 高吞吐量事件流式处理、遥测、日志聚合 | 许多生产者、多个消费者、事件按时间排序 |
| 服务总线 | 具有事务、会话、死信的企业消息传送 | 具有消息交付保证的点对点通信或发布/订阅模型 |
| 事件网格 | 被动事件驱动的体系结构、无服务器触发器 | 基于推送的事件路由和筛选 |
有关详细指导,请参阅选择Azure消息服务。
工作原理
事件中心提供一个统一的流式处理平台,具有基于时间的保留功能,实现事件生成者与使用者的分离解耦。 两者都可以通过多个协议执行大规模数据引入和处理。

核心组件
| 组件 | Description |
|---|---|
| 生成者应用程序 | 使用 事件中心 SDK、Kafka 生成者客户端或 HTTPS 将事件发送到事件中心的应用程序 |
| 命名空间 | 一个或多个事件中心的管理容器。 在命名空间级别处理流媒体容量、网络安全和地理灾难恢复 |
| 事件中心/Kafka 主题 | 仅追加分布式日志,用于组织事件。 包含一个或多个用于并行处理的分区 |
| 分区 | 用于缩放吞吐量的事件的有序序列。 将分区视为高速公路上的通道 - 更多的分区可实现更高的吞吐量 |
| 消费者应用程序 | 通过跟踪每个分区中的位置(偏移量)来读取事件的应用程序。 可以使用 Event Hubs SDK 或 Kafka 消费者客户端 |
| 使用者组 | 事件枢纽的逻辑视图,使多个消费者应用程序能够独立读取同一流,每个应用程序都维护自己的位置。 |
事件流
- 引入:生成者应用程序将事件发送到事件中心。 事件根据分区键或轮循机制分布分配给分区。
- 存储:事件持久存储,保留期可配置(1-90 天,具体取决于层)。 Capture 功能还可以将事件写入长期存储。
- Process:消费者应用程序通过消费者组从分区读取事件。 每个消费者使用 checkpointing 来跟踪其偏移量,以实现可靠的处理。
有关详细说明,请参阅 事件中心功能。
关键功能
核心平台功能
Apache Kafka 兼容性
事件中心是一个多协议事件流式处理引擎,原生支持 Apache Kafka、AMQP 1.0 和 HTTPS。 可以将 Kafka 工作负载引入事件中心,而无需更改代码、群集管理或第三方 Kafka 服务。
事件中心构建为云原生代理引擎,提供比自管理 Kafka 群集更好的性能和成本效益。 有关详细信息,请参阅适用于 Apache Kafka 的 Azure 事件中心。
灵活的扩展
从以兆字节为单位的数据流开始,增长到 GB 或 TB。 自动膨胀功能会自动缩放吞吐量单位以满足需求。
数据管理
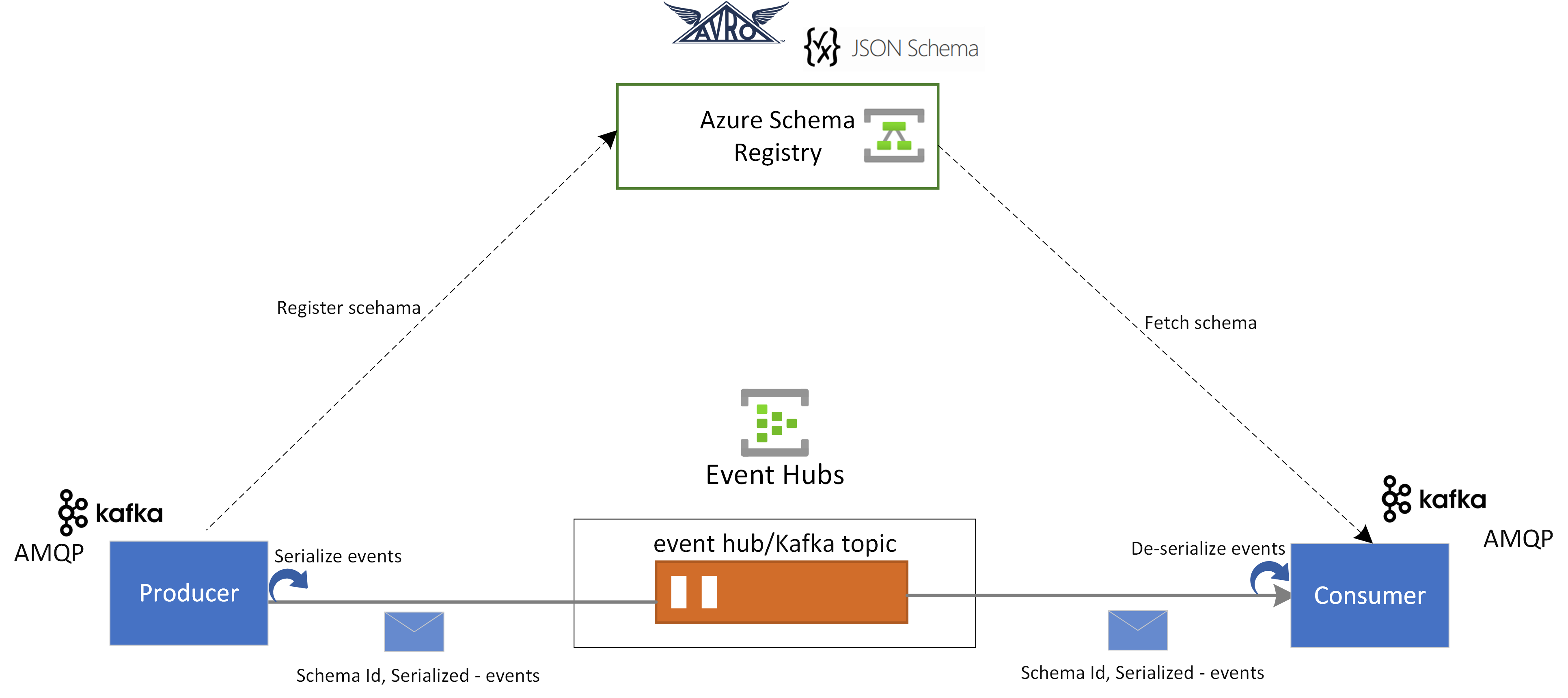
架构注册表
Azure架构注册表提供了用于管理事件流式处理应用程序的架构的集中式存储库。 它确保生成者和使用者之间的数据兼容性和一致性,支持架构演变,并使用 Avro 和 JSON 架构与 Kafka 应用程序集成。
捕获
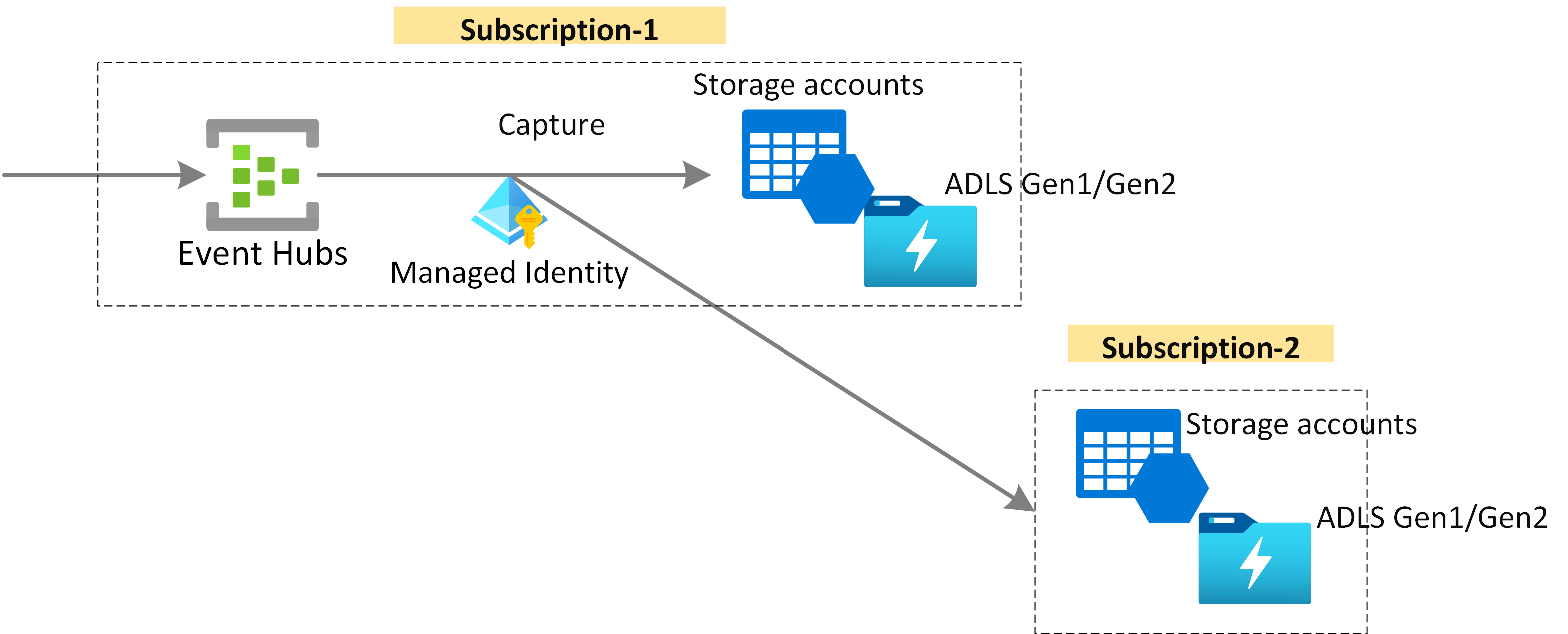
Capture您的流式数据并几乎实时地传输到 Azure Blob 存储 或 Azure Data Lake Storage,以便进行长期保留或批量分析。 捕获在用于实时处理的同一流上自动运行。
Azure集成
流分析集成
事件中心与 Azure 流分析集成,用于实时流处理。 使用内置无代码编辑器和拖放功能,或为复杂转换编写基于 SQL 的查询。

Azure 数据资源管理器集成
Azure 数据资源管理器针对大量流数据提供高性能分析。 将事件中心与数据资源管理器集成,以便进行准实时分析和探索。
**
有关详细信息,请参阅 将数据从事件中心引入到 Azure 数据资源管理器。
Azure Functions和无服务器
事件中心与 Azure Functions 集成,用于无服务器事件处理。 生态系统还支持 Azure Spring Apps、Kafka Connectors、Apache Spark 和 Apache Flink。
本地开发
事件中心模拟器提供了一种本地开发体验,用于独立于云依赖项,以隔离的方式针对服务开发和测试代码。
客户端库
事件中心为 .NET、Java、Python、JavaScript 和 Go 提供 client 库。 这些 SDK 支持 AMQP 和 Kafka 协议,使你能够选择最适合你的应用程序。
监测
监控事件中心,使用 Azure 监控指标、诊断日志和警报。 跟踪吞吐量、延迟、错误和消费者滞后,以确保最佳性能。
安全性和合规性
事件中心提供企业级安全功能:
| 功能 / 特点 | Description |
|---|---|
| 身份验证 | Microsoft Entra ID 具有基于角色的访问控制(RBAC)、共享访问签名或托管身份 |
| 网络安全 | 用于专用连接的 专用链接、VNet 服务终结点和 IP 防火墙规则 |
| 加密 | 使用Microsoft 托管或客户管理的密钥加密静态数据,TLS 1.2 用于传输中的数据 |
有关详细信息,请参阅 Event Hubs 安全基线。
高可用性和灾难恢复
事件中心提供多层可靠性:
- 可用性区域: 区域冗余 部署跨区域(高级层)跨区域分配副本
- 异地灾难恢复:Geo-DR 支持故障转移到次要区域并同步元数据
- SLA 保证:最多99.99% 可用性取决于层和配置
定价层级
有关当前定价和详细的功能比较,请参阅 Event Hubs 定价和 quotas 和限制。