Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Apache Ambari 是用于管理和监视 HDInsight 群集的 Web 界面。 有关 Ambari Web UI 的简介,请参阅使用 Apache Ambari Web UI 管理 HDInsight 群集。
以下部分介绍了用于优化 Apache Hive 总体性能的配置选项。
- 若要修改 Hive 配置参数,请从“服务”边栏中选择“Hive”。
- 导航到“配置”选项卡。
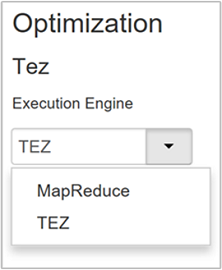
设置 Hive 执行引擎
Hive 提供两个执行引擎:Apache Hadoop MapReduce 和 Apache TEZ。 Tez 的速度比 MapReduce 更快。 HDInsight Linux 群集将 Tez 用作默认的执行引擎。 更改执行引擎:
在 Hive 的“配置”选项卡上的筛选框中,键入“执行引擎”。
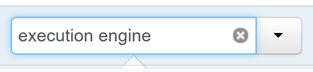
“优化”属性的默认值为 Tez。
优化映射器
Hadoop 会尝试将单个文件拆分(映射)为多个文件,以并行方式处理生成的文件。 映射器数目取决于拆分数目。 以下两个配置参数驱动 Tez 执行引擎的拆分数目:
tez.grouping.min-size:分组拆分大小的下限,默认值为 16 MB(16,777,216 字节)。tez.grouping.max-size:分组拆分大小的上限,默认值为 1 GB(1,073,741,824 字节)。
性能准则是,减小这两个参数可以改善延迟,增大这两个参数可以提高吞吐量。
例如,若要为数据大小 128 MB 设置四个映射器任务,可将每个任务的这两个参数设置为 32 MB(33,554,432 字节)。
若要修改限制参数,请导航到 Tez 服务的“配置”选项卡。 展开“常规”面板并找到
tez.grouping.max-size和tez.grouping.min-size参数。将这两个参数设置为 33,554,432 字节 (32 MB)。

这些更改会影响整个服务器中的所有 Tez 作业。 若要获取最佳结果,请选择适当的参数值。
优化化简器
Apache ORC 和 Snappy 都可提供高性能。 但是,Hive 默认提供的化简器可能太少,从而导致瓶颈。
例如,假设输入数据大小为 50 GB。 使用 Snappy 以 ORC 格式压缩这些数据后,大小为 1 GB。 Hive 估计所需的化简器数目为:(在映射器中输入的字节数 / hive.exec.reducers.bytes.per.reducer)。
如果使用默认设置,此示例的化简器数目为 4。
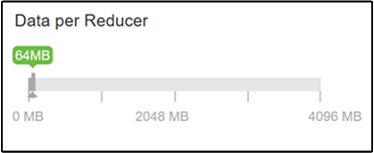
hive.exec.reducers.bytes.per.reducer 参数指定每个化简器处理的字节数。 默认值为 64 MB。 减小此值可提高并行度,并可能会改善性能。 但过度减小也可能生成过多的化简器,从而对性能产生潜在的负面影响。 此参数基于特定的数据要求、压缩设置和其他环境因素。
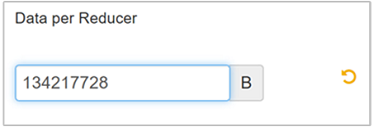
若要修改该参数,请导航到 Hive 的“配置”选项卡,然后在“设置”页上找到“每个化简器的数据”参数。
选择“编辑”并将该值修改为 128 MB(134,217,728 字节),然后按 Enter 保存。
假设输入大小为 1024 MB,每个化简器的数据为 128 MB,则有 8 个化简器 (1024/128)。
为“每个化简器的数据”参数提供错误的值可能导致生成大量的化简器,从而对查询性能产生负面影响。 若要限制化简器的最大数目,请将
hive.exec.reducers.max设置为适当的值。 默认值为 1009。
启用并行执行
一个 Hive 查询是在一个或多个阶段中执行的。 如果可以并行运行各个独立阶段,则会提高查询性能。
若要启用并行查询执行,请导航到 Hive 的“配置”选项卡并搜索
hive.exec.parallel属性。 默认值为 false。 将该值更改为 true,然后按 Enter 保存该值。若要限制并行运行的作业数,请修改
hive.exec.parallel.thread.number属性。 默认值为 8。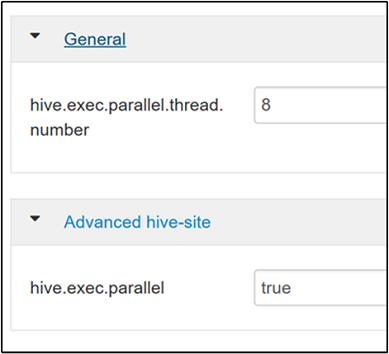
启用矢量化
Hive 逐行处理数据。 矢量化指示 Hive 以块(一个块包含 1,024 行)的方式处理数据,而不是以一次一行的方式处理数据。 矢量化只适用于 ORC 文件格式。
若要启用矢量化查询执行,请导航到 Hive 的“配置”选项卡并搜索
hive.vectorized.execution.enabled参数。 Hive 0.13.0 或更高版本的默认值为 true。若要为查询的化简端启用矢量化执行,请将
hive.vectorized.execution.reduce.enabled参数设置为 true。 默认值为 false。
启用基于成本的优化 (CBO)
默认情况下,Hive 遵循一组规则来找到一个最佳的查询执行计划。 基于成本的优化 (CBO) 会评估多个查询执行计划, 并为每个计划分配成本,然后确定执行查询的成本最低的计划。
若要启用 CBO,请导航到“Hive”>“配置”>“设置”,找到“启用基于成本的优化器”,然后将切换按钮切换到“打开”。

启用 CBO 后,可使用以下附加配置参数提高 Hive 查询性能:
hive.compute.query.using.stats如果设置为 true,则 Hive 会使用其元存储中存储的统计信息来应答类似于
count(*)的简单查询。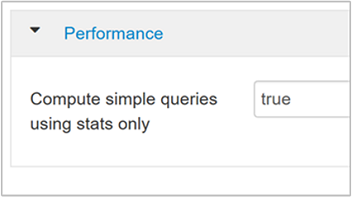
hive.stats.fetch.column.stats启用 CBO 时,会创建列统计信息。 Hive 使用元存储中存储的列统计信息来优化查询。 如果列数较多,则提取每个列的列统计信息需要花费很长时间。 如果设置为 false,则会禁用从元存储中提取列统计信息。
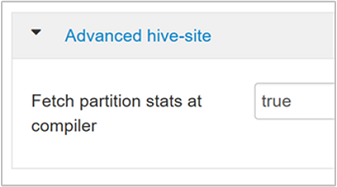
hive.stats.fetch.partition.stats行数、数据大小和文件大小等基本分区统计信息存储在元存储中。 如果设置为 true,则从元存储中提取分区统计信息。 如果设置为 false,则从文件系统中提取文件大小。 行数从行架构中提取。
启用中间压缩
映射任务将创建化简器任务使用的中间文件。 中间压缩可以缩小中间文件大小。
Hadoop 作业通常会遇到 I/O 瓶颈。 压缩数据能够加快 I/O 和总体网络传输速度。
可用的压缩类型包括:
| 格式 | 工具 | 算法 | 文件扩展名 | 是否可拆分? |
|---|---|---|---|---|
| Gzip | Gzip | DEFLATE | .gz |
否 |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
是 |
| LZO | Lzop |
LZO | .lzo |
是(如果已编制索引) |
| Snappy | 空值 | Snappy | Snappy | 否 |
一般规则是,尽量使用可拆分的压缩方法,否则会创建极少的映射器。 如果输入数据为文本,则 bzip2 是最佳选项。 对于 ORC 格式,Snappy 是最快的压缩选项。
若要启用中间压缩,请导航到 Hive 的“配置”选项卡,并将
hive.exec.compress.intermediate参数设置为 true。 默认值为 false。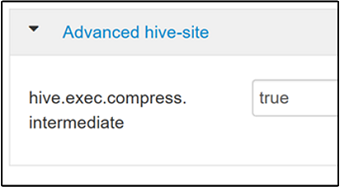
注意
若要压缩中间文件,请选择一个 CPU 开销较低的压缩编解码器,即使该编解码器不能提供较高的压缩输出。
若要设置中间压缩编解码器,请将自定义属性
mapred.map.output.compression.codec添加到hive-site.xml或mapred-site.xml文件。添加自定义设置:
a. 导航到“Hive”>“配置”>“高级”>“自定义 hive-site”。
b. 选择“自定义 hive-site”窗格底部的“添加属性…”。
c. 在“添加属性”窗口中,输入
mapred.map.output.compression.codec作为键,输入org.apache.hadoop.io.compress.SnappyCodec作为值。d. 选择 添加 。
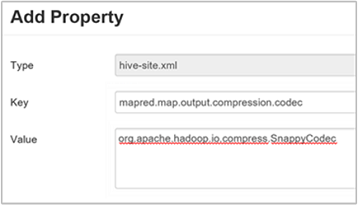
此设置将使用 Snappy 压缩来压缩中间文件。 添加该属性后,它会显示在“自定义 hive-site”窗格中。
注意
此过程会修改
$HADOOP_HOME/conf/hive-site.xml文件。
压缩最终输出
还可以压缩最终的 Hive 输出。
若要压缩最终的 Hive 输出,请导航到 Hive 的“配置”选项卡,并将
hive.exec.compress.output参数设置为 true。 默认值为 false。若要选择输出压缩编解码器,请根据上一部分的步骤 3 所述,将
mapred.output.compression.codec自定义属性添加到“自定义 hive-site”窗格。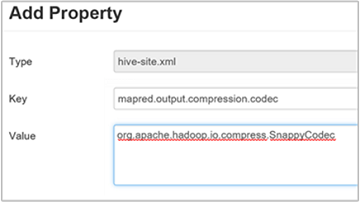
启用推理执行
推理执行会启动一定数量的重复任务,用于检测运行缓慢的任务跟踪器并将它们列入拒绝列表。 同时通过优化各个任务结果来改进作业的整体执行。
不应该对输入量较大的长时间运行的 MapReduce 任务启用推理执行。
若要启用推理执行,请导航到 Hive 的“配置”选项卡,并将
hive.mapred.reduce.tasks.speculative.execution参数设置为 true。 默认值为 false。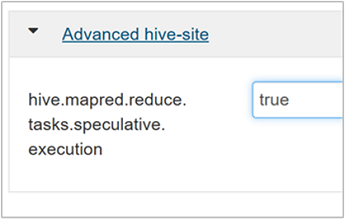
优化动态分区
Hive 允许在表中插入记录时创建动态分区,且无需预定义每个分区。 此功能非常强大。 但它可能会导致创建大量的分区, 并为每个分区创建大量文件。
要让 Hive 执行动态分区,应将
hive.exec.dynamic.partition参数值设置为 true(默认值)。将动态分区模式更改为 strict。 在 strict(严格)模式下,必须至少有一个分区是静态的。 此设置可以阻止未在 WHERE 子句中包含分区筛选器的查询,即,strict 可阻止扫描所有分区的查询。 导航到 Hive 的“配置”选项卡,并将
hive.exec.dynamic.partition.mode设置为 strict。 默认值为 nonstrict。若要限制要创建的动态分区数,请修改
hive.exec.max.dynamic.partitions参数。 默认值为 5000。若要限制每个节点的动态分区总数,请修改
hive.exec.max.dynamic.partitions.pernode。 默认值为 2000。
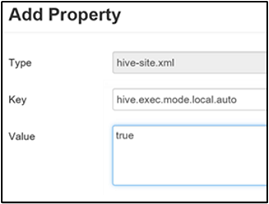
启用本地模式
通过本地模式,Hive 可以在一台计算机上或有时在一个进程中, 执行一个作业的所有任务。 如果输入数据较小, 并且查询启动任务的开销会消耗总体查询执行资源的绝大部分,则此设置可以提高查询性能。
若要启用本地模式,请根据启用中间压缩部分的步骤 3 所述,将 hive.exec.mode.local.auto 参数添加到“自定义 hive-site”面板。
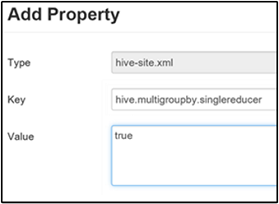
设置单个 MapReduce MultiGROUP BY
如果此属性设置为 true,则包含通用 group-by 键的 MultiGROUP BY 查询将生成单个 MapReduce 作业。
若要启用此行为,请根据启用中间压缩部分的步骤 3 所述,将 hive.multigroupby.singlereducer 参数添加到“自定义 hive-site”窗格。
其他 Hive 优化
以下部分介绍了可以设置的其他 Hive 相关优化。
联接优化
Hive 中的默认联接类型是“随机联接”。 在 Hive 中,特殊的映射器会读取输入,并向中间文件发出联接键/值对。 Hadoop 在随机阶段中排序与合并这些对。 此随机阶段的系统开销较大。 根据数据选择右联接可以显著提高性能。
| 联接类型 | 时间 | 方式 | Hive 设置 | 注释 |
|---|---|---|---|---|
| 随机联接 |
|
|
不需要过多的 Hive 设置 | 每次运行 |
| 映射联接 |
|
|
hive.auto.convert.join=true |
速度很快,但受限 |
| 排序合并存储桶 | 如果两个表:
|
每个进程:
|
hive.auto.convert.sortmerge.join=true |
高效 |
执行引擎优化
有关优化 Hive 执行引擎的其他建议:
| 设置 | 建议 | HDInsight 默认值 |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
True = 更安全,但速度更慢;false = 速度更快 | false |
tez.am.resource.memory.mb |
大多数引擎的上限为 4 GB | 自动优化 |
tez.session.am.dag.submit.timeout.secs |
300+ | 300 |
tez.am.container.idle.release-timeout-min.millis |
20000+ | 10000 |
tez.am.container.idle.release-timeout-max.millis |
40000+ | 20000 |