Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Apache Spark 流式处理在 HDInsight Spark 群集上提供数据流式处理。 同时保证即便发生节点故障,任何输入事件也仅处理一次。 Spark 流是一个长时间运行的作业,接收各种来源(包括 Azure 事件中心)的输入数据。 此外:Azure IoT 中心、Apache Kafka、Apache Flume、X、ZeroMQ、原始 TCP 套接字或来自监视 Apache Hadoop YARN 文件系统的输入数据。 与完全由事件驱动的进程不同,Spark 流以批处理方式将输入数据放入各时段。 例如 2 秒的切片,然后使用映射、减少、联接和提取操作转化每批数据。 然后,Spark 流将转换后的数据写入文件系统、数据库、仪表板和控制台。
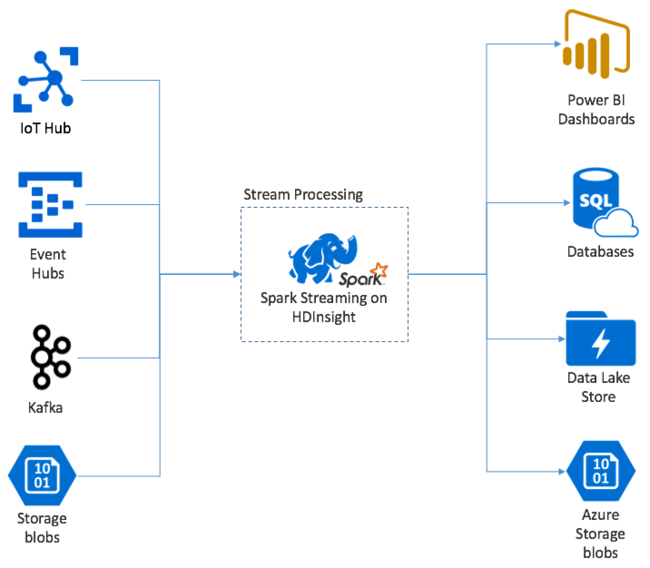
Spark 流式处理应用程序必须先等待一会,以收集事件的每个micro-batch,才能发送该批处理进行处理。 与此相反,事件驱动应用程序会立即处理每个事件。 Spark 流式处理延迟一般为几秒钟。 微批处理方法的优点是数据处理效率更高和聚合计算更简单。
引入 DStream
Spark 流式处理使用称为 DStream 的离散流表示传入数据的连续流。 DStream 可从事件中心或 Kafka 等输入源创建。 或通过对其他 DStream 应用转换来创建。
DStream 可提供基于原始事件数据的抽象层。
从单一事件开始,例如已连接调温器的温度读数。 此事件到达 Spark 流式处理应用程序后,系统将以可靠方式存储事件,即在多个节点上进行复制。 此容错功能可确保任何单个节点的故障都不会导致事件丢失。 Spark 核心使用在群集中的多个节点上分布数据的数据结构。 其中每个节点通常在内存中维护自己的数据,以获得最佳性能。 此数据结构称为弹性分布式数据集 (RDD)。
每个 RDD 表示在用户定义的时间范围(称为批处理间隔)内收集的事件。 每个批处理间隔后,将生成新的 RDD,其中包含该间隔的所有数据。 此连续 RDD 集将收集到 DStream 中。 例如,如果批处理间隔为 1 秒,则 DStream 将每秒发出一个批处理,其中包含一个 RDD(包含该秒期间引入的所有数据)。 处理 DStream 时,温度事件将出现在其中一个批处理中。 Spark 流式处理应用程序处理包含事件的批处理并最终作用于每个 RDD 中存储的数据。
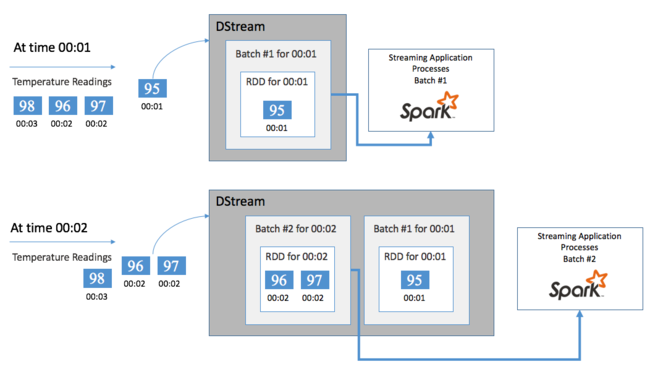
Spark 流式处理应用程序的结构
Spark 流式处理应用程序是从引入源接收数据的长时间运行的应用程序。 应用转换以处理这些数据,然后将数据推送至一个或多个目标。 Spark 流式处理应用程序的结构包含静态部分和动态部分。 静态部分定义数据的来源,要对数据执行哪些处理, 以及结果应发送到何处。 动态部分无限期运行应用程序,等待停止信号。
例如,下面的简单应用程序通过 TCP 套接字接收一行文本,并对每个字出现的次数进行计数。
定义应用程序
应用程序逻辑定义有四个步骤:
- 创建 StreamingContext。
- 从 StreamingContext 创建 DStream。
- 将转换应用于 DStream。
- 输出结果。
此定义是静态的,且在运行该应用程序前没有处理任何数据。
创建 StreamingContext
从指向群集的 SparkContext 创建 StreamingContext。 创建 StreamingContext 时,指定批处理的大小(以秒为单位),例如:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
创建 DStream
使用 StreamingContext 实例,为输入源创建输入 DStream。 在这种情况下,应用程序会监视默认附加存储中的新文件的外观。
val lines = ssc.textFileStream("/uploads/Test/")
应用转换
通过对 DStream 应用转换来实现处理。 此应用程序一次从文件接收一行文本,将每行文本拆分成字。 然后使用映射化简模式来计算每个字出现的次数。
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
输出结果
通过应用输出操作,将转换结果推送到目标系统。 在本例中,整个计算中的每个运行的结果都将打印到控制台输出中。
wordCounts.print()
运行应用程序
启动流式处理应用程序并运行,直到收到终止信号。
ssc.start()
ssc.awaitTermination()
有关 Spark 流 API 的详细信息,请参阅 Apache Spark 流式处理编程指南。
下面的示例应用程序是自包含的,因此可以在 Jupyter Notebook 内运行它。 此示例将在类 DummySource 中创建模拟数据源,该源每五秒输出计数器的值以及当前时间(以毫秒为单位)。 新 StreamingContext 对象的批处理间隔为 30 秒。 每创建一个批次时,流式处理应用程序都会检查生成的 RDD。 然后将 RDD 转换为 Spark DataFrame 并通过 DataFrame 创建一个临时表。
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
在启动上面的应用程序以后,等待约 30 秒钟。 然后,你可以定期查询 DataFrame 来查看批处理中存在的当前值集,例如,使用以下 SQL 查询:
%%sql
SELECT * FROM demo_numbers
生成的输出如下所示:
| value | time |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
存在六个值,因为 DummySource 每隔 5 秒创建一个值,且应用程序每隔 30 秒发出一个批处理。
滑动窗口
若要对某个时间段内的 DStream 执行聚合计算,例如获取最后 2 秒钟内的平均温度,可以使用 Spark 流式处理中包括的 sliding window 操作。 滑动窗口具有一个持续时间(窗口长度)和在期间计算窗口内容的时间间隔(即滑动间隔)。
滑动窗口可以重叠,例如,可以定义长度为两秒的窗口,每一秒滑动一次。 该操作意味着每次执行聚合计算时,窗口将包括上一个窗口最后一秒的数据。 以及下一秒的任何新数据。
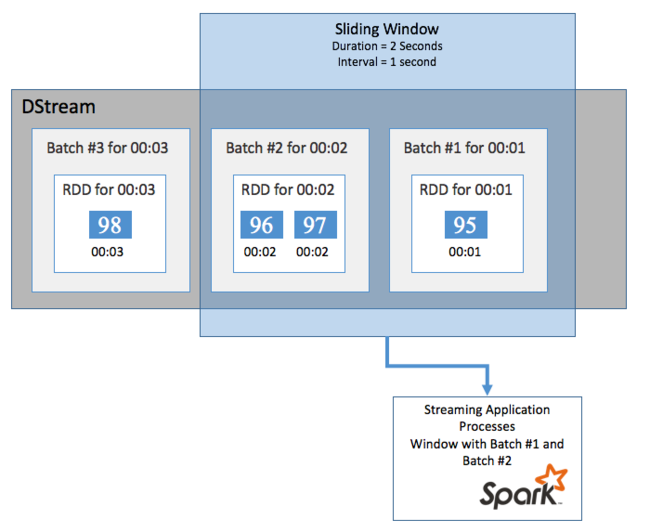
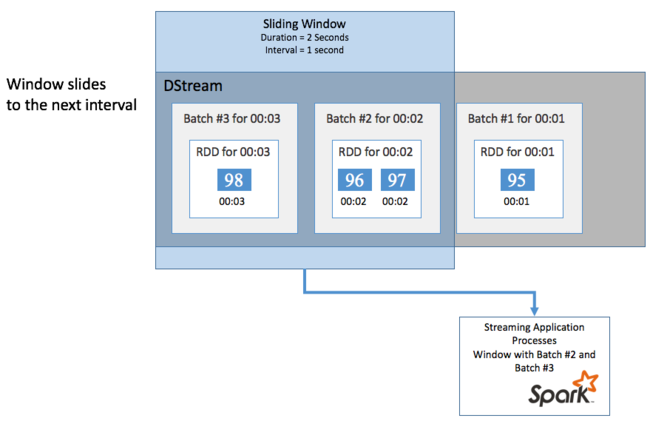
下面的示例将更新使用 DummySource 的代码,将批处理收集到持续时间为一分钟且滑动为一分钟的窗口中。
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
第一分钟后,会产生 12 个条目 - 窗口中收集到的两个批处理中各有 6 个条目。
| value | time |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
Spark 流式传输 API 中可用的滑动窗口函数包括 window、countByWindow、reduceByWindow 和 countByValueAndWindow。 有关这些函数的详细信息,请参阅 Transformations on DStreams(DStreams 的转换)。
检查点
为提供复原和容错功能,Spark 流式处理依赖检查点,确保即使出现节点故障,流处理仍可以不间断地继续。 Spark 创建持久存储(Azure 存储或 Data Lake Storage)的检查点。 这些检查点存储流式处理应用程序元数据,例如应用程序定义的配置和操作。 以及已排队但尚未处理的所有批处理。 有时,检查点还包括将数据保存在 RDD 中以便更快速地基于由 Spark 托管的 RDD 中存在的内容重新生成数据状态。
部署 Spark 流式处理应用程序
通常将 Spark 流式处理应用程序本地生成到 JAR 文件中。 然后通过将 JAR 文件复制到默认的附加存储将其部署到 HDInsight 上的 Spark。 可以使用 POST 操作,通过群集上可用的 LIVY REST API 启动该应用程序。 POST 的正文包括提供 JAR 路径的 JSON 文档。 和其 main 方法定义并运行流式处理应用程序的类的名称以及可选的作业资源要求(例如执行器、内存和核心的数量)。 以及应用程序代码所需的任何配置设置。
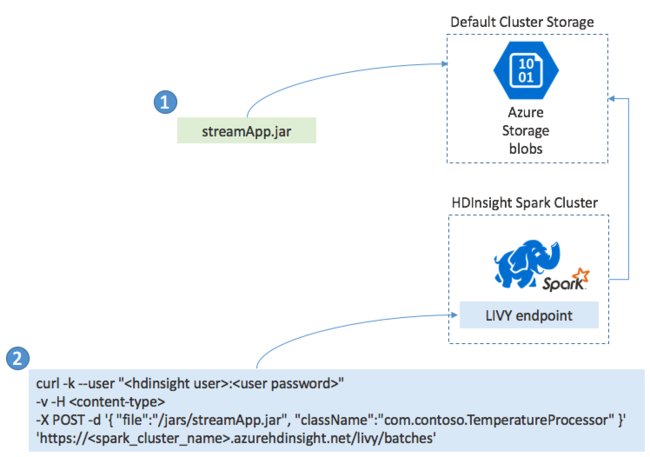
此外,可以使用 GET 请求针对 LIVY 终结点检查所有应用程序的状态。 最后,可以通过针对 LIVY 终结点发出 DELETE 请求终止正在运行的应用程序。 有关 LIVY API 的详细信息,请参阅使用 Apache LIVY 执行远程作业
后续步骤
- 在 HDInsight 中创建 Apache Spark 群集
- Apache Spark Streaming Programming Guide(Apache Spark 流式处理编程指南)
- Apache Spark 结构化流的概述