Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文介绍如何在 Azure 机器学习设计器中使用“基于筛选器的特征选择”组件。 此组件可帮助你标识输入数据集中预测能力最高的列。
概括而言,“特征选择”是指在指定了输出的情况下,将统计测试应用到输入的过程。 目标是确定哪些列能够更准确地预测输出。 “基于筛选器的特征选择”组件提供多种特征选择算法供用户选择。 该组件包含“皮尔逊相关”和卡方值等关联方法。
使用“基于筛选器的特征选择”组件时,需要提供一个数据集,并标识包含标签或因变量的列。 然后,指定一个用于度量特征重要性的方法。
该组件将输出包含最佳特征列(按预测能力排名)的数据集。 它还根据所选的指标输出特征的名称及其评分。
基于筛选器的特征选择是什么?
此组件之所以称为“基于筛选器”的特征选择,是因为你要使用所选的指标来查找不相关的属性。 然后从模型中筛选出多余的列。 选择适合数据的单个统计度量后,该组件将计算每个特征列的评分。 返回的列已按其特征评分排名。
选择适当的特征可能会改善分类的准确度和效率。
通常只使用具有最高评分的列来生成预测模型。 可将特征选择评分不佳的列保留在数据集中,并在生成模型时将其忽略。
如何选择特征选择指标
“基于筛选器的特征选择”组件提供各种指标用于评估每个列中的信息值。 本部分将大致介绍每个指标及其应用方式。 可以在技术说明以及有关配置每个组件的说明中,找到使用每个指标所要满足的其他要求。
皮尔逊相关
皮尔逊相关统计(或皮尔逊相关系数)在统计模型中也称为
r值。 对于任意两个变量,它会返回指示相关性强度的值。皮尔逊相关系数的计算方式是:将两个变量的协方差除以其标准偏差的积。 这两个变量的标度变化不影响该系数。
卡方
双向卡方测试是测量预期值与实际结果的接近程度的一种统计方法。 该方法假设变量是随机的,并且是从独立变量的足够样本中抽取的。 生成的卡方统计信息指示实际结果与预期(随机)结果之间的差距。
提示
如果需要对自定义特征选择方法使用不同的选项,请使用执行 R 脚本组件。
如何配置“基于筛选器的特征选择”
选择标准统计指标。 该组件计算一对列之间的关联:标签列和特征列。
将“基于筛选器的特征选择”组件添加到管道。 可以在设计器的“特征选择”类别中找到它。
连接至少包含两个列(潜在特征)的输入数据集。
为了确保分析某列并生成特征评分,请使用编辑元数据组件来设置 IsFeature 属性。
对于“特征评分方法”,请选择以下已建立的统计方法之一,以便在计算评分时使用。
方法 要求 皮尔逊相关 标签可以是文本或数字。 特征必须是数字。 卡方 标签和特征可以是文本或数字。 使用此方法来计算两个分类列的特征重要性。 提示
如果更改所选的指标,将重置所有其他选择。 因此,请务必先设置此选项。
选择“仅对特征列运行”选项,以便仅为事先已标记为特征的列生成评分。
如果清除此选项,该组件也会为不满足条件的任何列创建评分,直到达到“所需特征数”中指定的列数。
对于“目标列”,请选择“启动列选择器”,以按名称或索引选择标签列。 (索引从 1 开始。)
涉及到统计相关性的所有方法都需要一个标签列。 如果你未选择一个或多个标签列,该组件将返回设计时错误。对于“所需特征数”,请输入要作为结果返回的特征列数目:
可指定的最小特征数为 1,但我们建议增大此值。
如果指定的所需特征数大于数据集中的列数,将返回所有特征。 甚至会返回评分为零的特征。
如果指定的结果列少于特征列,则会按评分的降序将特征排名。 只返回评分最高的特征。
提交管道。
重要
如果打算在推理中使用“基于筛选器的特征选择”,则需要使用选择列转换来存储特征选择结果,并使用应用转换将特征选择转换应用到评分数据集。
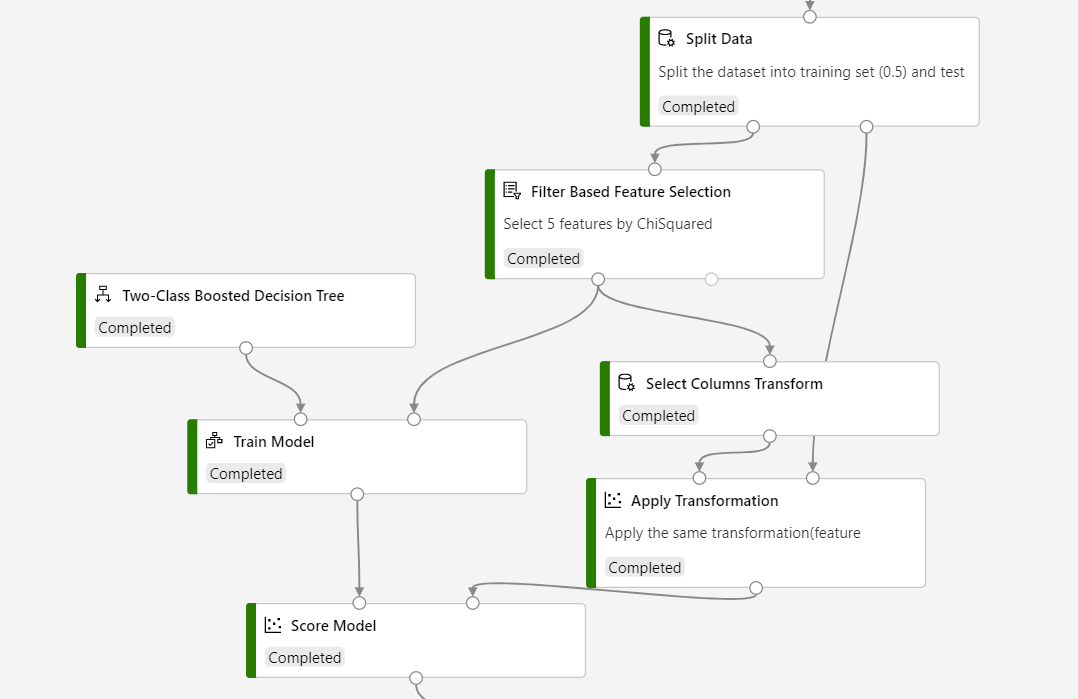
请参考下面的屏幕截图来构建管道,以确保列选择与评分过程相同。
结果
处理完成后:
若要查看已分析的特征列及其分数的完整列表,请右键单击该组件并选择“可视化”。
若要根据特征选择条件查看数据集,请右键单击该组件并选择“可视化”。
如果数据集包含的列数少于预期,请检查组件设置。 此外,请检查作为输入提供的列数据类型。 例如,如果将“所需特征数”设置为 1,则输出数据集只包含两列:标签列,以及排名最高的特征列。
技术说明
实现详细信息
如果对数字特征和分类标签使用皮尔逊相关,则特征评分的计算方式如下:
对于分类列中的每个级别,将计算数字列的条件平均值。
将条件平均列与数字列相关联。
要求
对于指定为“标签”或“评分”列的任何列,无法生成特征选择评分。
如果你尝试对评分方法不支持的数据类型的列使用评分方法,该组件将引发错误。 或者,会将零评分分配到该列。
如果某个列包含逻辑 (true/false) 值,这些值将作为
True = 1和False = 0进行处理。如果已将某个列指定为“标签”或“评分”,则该列不能是特征。
如何处理缺失值
无法将包含所有缺失值的列指定为目标(标签)列。
如果某个列包含缺失值,则该组件在计算该列的评分时,会忽略这些缺失值。
如果指定为特征列的某个列包含所有缺失值,该组件将分配零评分。
后续步骤
请参阅 Azure 机器学习可用的组件集。