Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文介绍了如何使用 Azure 机器学习设计器中的“训练 Pytorch 模型”组件来训练 DenseNet 之类的 PyTorch 模型。 训练在你定义模型并设置其参数后进行,并且需要带标签的数据。
目前,“训练 PyTorch 模型”组件支持单节点训练和分布式训练。
如何使用“训练 PyTorch 模型”
将“训练 PyTorch 模型”组件添加到管道。 可以在“模型训练”类别下找到此组件。 展开“训练”,然后将“训练 PyTorch 模型”组件拖到你的管道中。
注释
对于大型数据集,最好是在“GPU”类型的计算上运行“训练 PyTorch 模型”组件,否则管道会出现故障 。 可以通过设置“使用其他计算目标”,在组件的右窗格中为特定组件选择计算。
在左侧输入中,附加未训练的模型。 将训练数据集和验证数据集附加到“训练 PyTorch 模型”的中间和右侧输入中。
对于未经训练的模型,其必须为与 DenseNet 类似的 PyTorch 模型;否则将引发“InvalidModelDirectoryError”错误。
对于数据集,训练数据集必须是已标记的图像目录。 请参阅“转换为图像目录”以了解如何获取标记的图像目录。 如果未标记,将引发“NotLabeledDatasetError”。
训练数据集和验证数据集具有相同的标签类别,否则将引发 InvalidDatasetError。
对于“时期”,指定要训练的时期数。 每个时期将循环访问整个数据集,默认循环访问 5 次。
对于“批大小”,指定在一个批次中训练的实例数,默认为 16 个。
对于“学习率预热步数”,应指定要预热训练的回合数,以防该值默认为 0 时,初始学习率略微太大而无法开始收敛。
对于“学习率”,应指定学习速率值,其中默认值为 0.001。 学习率可控制每次在 sgd 等优化器中对模型进行测试和纠正时使用的步长。
设置的学习率越小,模型测试就越频繁,而且可能会陷入局部停滞。 设置的学习率越大,收敛速度就越快,而且有可能会超过实际最小值。
注释
如果训练损失在训练期间变为 Nan,则可能是因学习率太大所致,此时降低学习率或许会有所帮助。 在分布式训练中,为了保持梯度稳定下降,实际学习率将由
lr * torch.distributed.get_world_size()计算,因为进程组的批尺寸为单一进程的进程总数。 应用多项式学习率衰减可帮助构建一个性能更好的模型。对于“随机种子”,可以选择键入一个整数值,将其用作种子。 如果需要跨作业确保试验的可再现性,建议使用种子。
对于“耐性”,请指定在验证损失不连续减少时提前停止训练的时期数。 默认为 3。
对于“打印频率”,应指定每个训练回合中迭代的训练日志打印频率,默认值为 10。
提交管道。 如果数据集较大,这将需要一段时间,建议使用 GPU 计算。
分布式训练
在分布式训练中,用于训练模型的工作负载会在多个微型处理器之间进行拆分和共享,这些处理器称为工作器节点。 这些工作器节点并行工作以加速模型训练。 目前,设计器支持适用于“训练 PyTorch 模型”组件的分布式训练。
训练时间
借助分布式训练,你可以通过训练 PyTorch 模型在 ImageNet(1,000 个类别、1,200,000 张图像)等大型数据集上进行训练。 下表显示了使用不同设备在 ImageNet 上从头开始对 Resnet50 进行 50 个回合训练的训练时间及表现。
| 设备 | 训练时间 | 训练吞吐量 | Top-1 验证准确率 | Top-5 验证准确率 |
|---|---|---|---|---|
| 16 V100 GPU | 6 小时 22 分钟 | 大约 3,200 张图像/秒 | 68.83% | 88.84% |
| 8 V100 GPU | 12 小时 21 分钟 | 大约 1,670 张图像/秒 | 68.84% | 88.74% |
单击此组件的“指标”选项卡,然后查看训练指标图,如“每秒训练图数”和“排名第 1 的准确率”。

如何启用分布式训练
若要为“训练 PyTorch 模型”组件启用分布式训练,可以在组件右侧窗格的“作业设置”中进行设置。 分布式训练仅支持 Azure 机器学习计算群集 。
注释
激活分布式训练需要多个 GPU,因为使用 NCCL 后端的“训练 PyTorch 模型”组件时需要 cuda。
选择此组件并打开右侧面板。 展开“作业设置”部分。
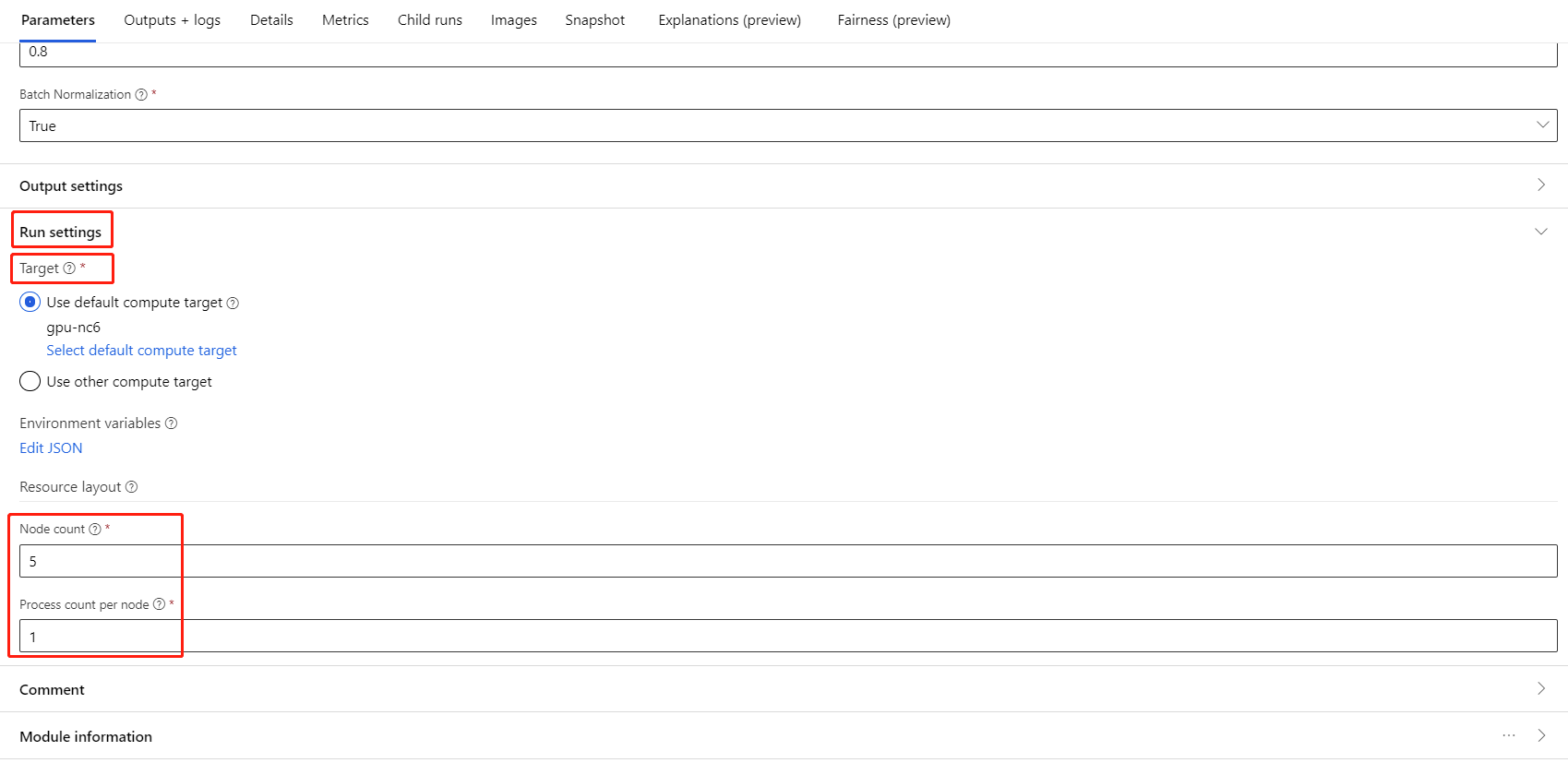
确保已为计算目标选择 Azure 机器学习计算。
在“资源布局”部分,需要设置以下值:
节点计数:计算目标中用于训练的节点数。 该值应小于或等于计算群集的最大节点数。 默认值为 1,代表单节点作业。
每个节点的进程计数:每个节点触发的进程数。 该值应小于或等于计算的处理单位。 默认值为 1,代表单进程作业。
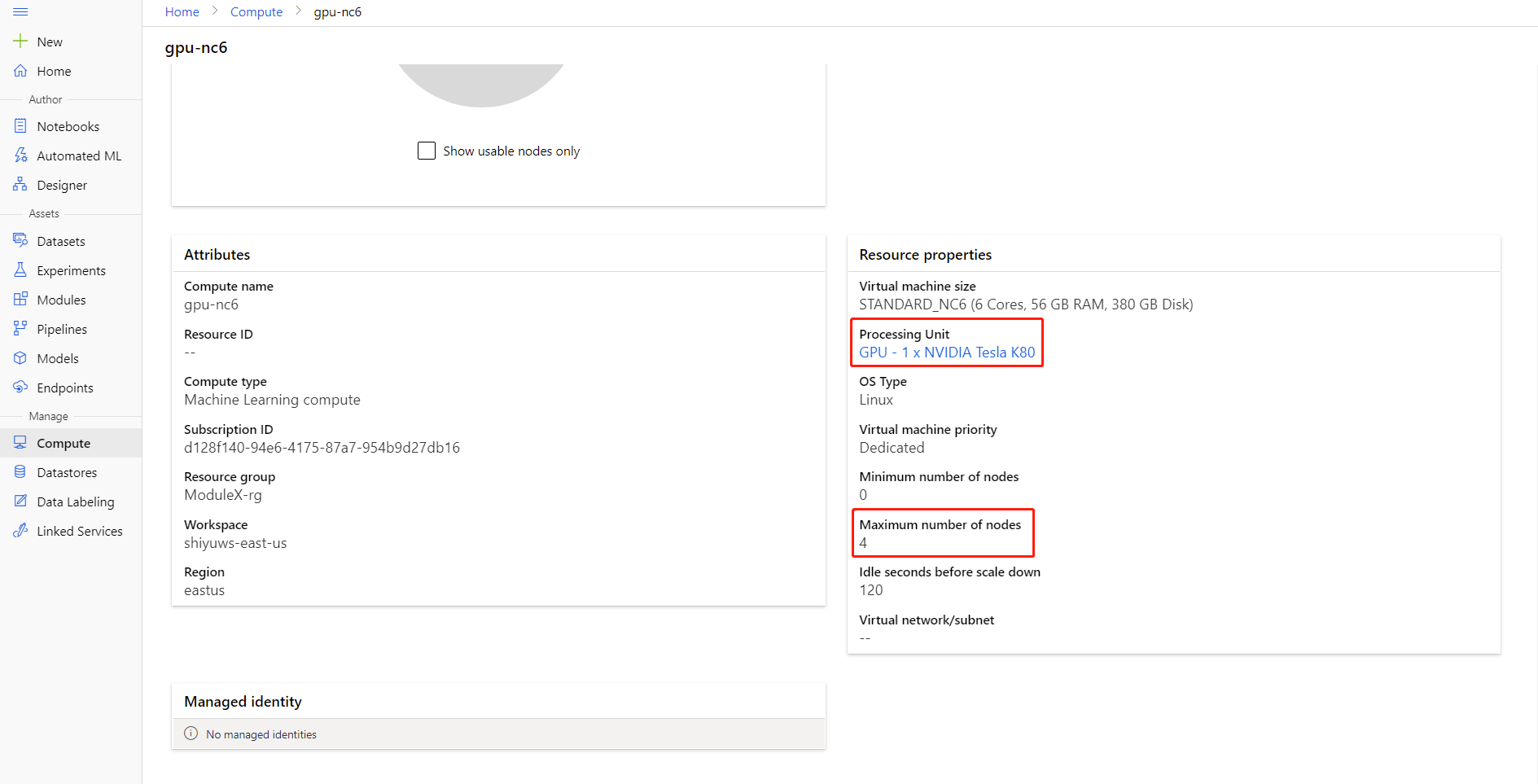
通过单击计算名称进入“计算详情”页,便可检查计算的“最大节点数”和“处理单位”。


此处 可详细了解 Azure 机器学习分布式训练的相关信息。
分布式训练故障排除
如果为此组件启用分布式训练,则每个进程都会生成驱动程序日志。
70_driver_log_0 适用于主进程。 在右侧窗格的“输出 + 日志”选项卡下,即可查看驱动程序日志中每个进程的详细错误信息。

如果启用分布式训练的组件发生故障,但未生成任何 70_driver 日志,则可查看 70_mpi_log 以了解错误详情。
下方示例显示了一则常见错误,即每个节点的进程计数大于计算的处理单位 。

有关组件故障排除的更多详细信息,可参阅此文。
结果
管道作业完成后,若要使用模型进行评分,请将训练 PyTorch 模型连接到为图像模型评分,以预测新输入示例的值。
技术说明
预期输入
| 名称 | 类型 | DESCRIPTION |
|---|---|---|
| 未训练的模型 | UntrainedModelDirectory | 未经训练的模型,需要 PyTorch |
| 训练数据集 | ImageDirectory | 训练数据集 |
| 验证数据集 | ImageDirectory | 每个时期用于评估的验证数据集 |
组件参数
| 名称 | 范围 | 类型 | 违约 | DESCRIPTION |
|---|---|---|---|---|
| 时期 | >0 | 整数 | 5 | 选择包含标签的列或结果列 |
| 批次大小 | >0 | 整数 | 16 | 要在一个批次中训练的实例数 |
| 学习率预热步数 | >=0 | 整数 | 0 | 预热训练的回合数 |
| 学习速率 | >=double。伊普西隆 | 漂浮 | 0.1 | “随机梯度下降”优化器的初始学习速率。 |
| 随机种子 | 任意 | 整数 | 1 | 模型使用的随机数生成器的种子。 |
| 耐性 | >0 | 整数 | 3 | 要提前停止训练的时期数 |
| 打印频率 | >0 | 整数 | 10 | 每个回合中迭代的训练日志打印频率 |
输出
| 名称 | 类型 | DESCRIPTION |
|---|---|---|
| 已训练模型 | ModelDirectory | 已训练模型 |
后续步骤
请参阅 Azure 机器学习可用的组件集。