Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文讨论有关大量历史数据的训练预测模型。 有关 AutoML 中训练预测模型的说明和示例,请参阅 为时序预测设置 AutoML。
时序数据可能会很大,这可能是由于数据中的序列数量、历史观察记录数量,或两者兼而有之。 许多模型 和分层时序(或 HTS)是第一种方案的缩放解决方案,其中数据包含大量的时序。 在这些情况下,将数据分区为组并并行训练大量独立模型可以提高模型的准确性和可伸缩性。 相反,对于其他方案,一个或多个高容量模型效果更好。 分布式 DNN 训练便是针对这种情况。 本文的其余部分将回顾与这些方案相关的概念。
多模型
AutoML 中的许多模型组件使你能够并行训练和管理数百万个模型。 例如,假设你有大量商店的历史销售数据。 可以使用许多算法模型为每个商店启动 AutoML 并行训练任务,如下图所示:

在此示例中,“许多模型”训练组件将 AutoML 的模型扫描和选择独立应用于每个商店。 模型的独立性有助于可伸缩性,并且可能提高模型的准确性,尤其是在商店具有不同的销售动态时。 但是,当存在常见的销售动态时,单个模型方法可能会产生更准确的预测。 有关详细信息,请参阅 分布式 DNN 训练 部分。
你可以配置数据分区、模型的 AutoML 设置,以及许多模型训练作业的并行度。 有关示例,请参阅我们有关许多模型组件的指南部分。
分层时序预测
在业务应用程序中,时序数据通常包括构成层次结构的嵌套属性。 例如,地理属性和产品目录属性通常相互嵌套。 假设层次结构包括两个地理属性、状态和存储 ID 以及两个产品属性、类别和 SKU:

下图演示了此层次结构:

叶(SKU)级别的销售数量总和是州和总销售级别的聚合销售数量。 在预测在层次结构的任何级别上销售的数量时,分层预测方法会保留这些聚合属性。 涉及此属性的预测在层次结构方面是一致的。
AutoML 支持分层时序 (HTS) 的以下功能:
- 在层次结构的任何级别进行训练。 在某些情况下,叶级数据可能会干扰,但聚合数据可能更易于预测。
- 在层次结构的任何级别检索点预测。 如果预测级别“低于”训练级别,则模型将使用 历史平均比例 或 历史平均值的比例从训练级别分解预测。 如果预测级别“高于”训练级别,模型将根据聚合结构对训练级别预测求和。
- 对训练级别或低于训练级别的水平进行分位和概率预测的检索。 当前建模功能支持分解概率预测。
AutoML 中的 HTS 组件基于 许多模型生成,因此 HTS 共享许多模型的可缩放属性。 有关示例,请参阅我们有关 HTS 组件的指南部分。
分布式 DNN 训练(预览版)
重要
此功能目前处于公开预览状态。 此预览版在提供时没有附带服务级别协议,我们不建议将其用于生产工作负荷。 某些功能可能不受支持或者受限。
有关详细信息,请参阅适用于 Azure 预览版的补充使用条款。
包含大量历史观察或大量相关时序的数据方案可能受益于可缩放的单一模型方法。 因此,AutoML 支持对时态卷积网络 (TCN) 模型进行分布式训练和模型搜索,这些模型是时序数据的一种深度神经网络 (DNN)。 有关 AutoML 的 TCN 模型类的详细信息,请参阅 DNN 一文。
分布式 DNN 训练通过使用遵循时序边界的数据分区算法来实现可伸缩性。 下图演示了一个包含两个分区的简单示例:
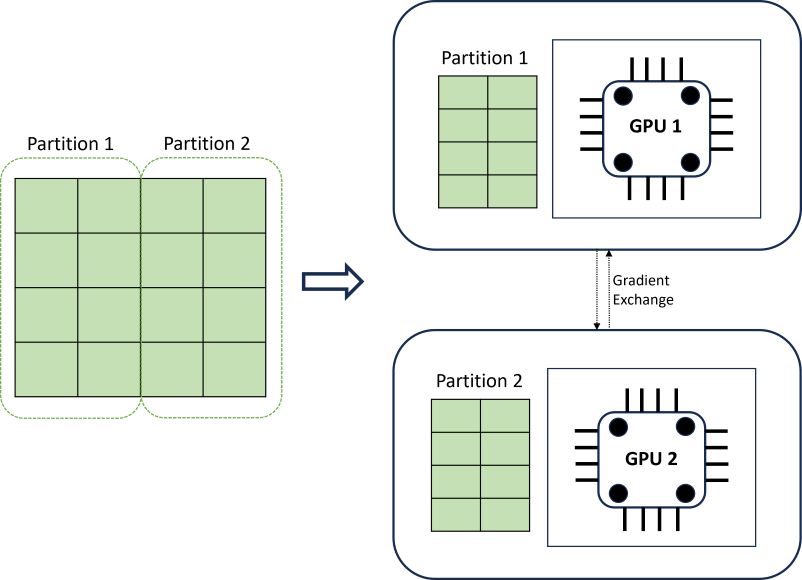
在训练期间,每个计算节点上的 DNN 数据加载程序仅加载完成反向传播迭代所需的内容; 整个数据集永远不会读入内存中。 分区将进一步在多个计算核心(通常为 GPU,可能位于多个节点上)上分布,以加速训练。 Horovod 框架跨计算节点提供协调。
后续步骤
- 详细了解如何设置 AutoML 来训练时序预测模型。
- 了解 AutoML 如何使用机器学习生成预测模型。
- 了解 AutoML 中用于预测的深度学习模型