Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
重要
本文提供有关使用 Azure Machine Learning SDK v1 的信息。 SDK v1 自 2025 年 3 月 31 日起弃用。 对它的支持将于 2026 年 6 月 30 日结束。 可以在该日期之前安装和使用 SDK v1。 使用 SDK v1 的现有工作流将在支持结束日期后继续运行。 但是,在产品发生体系结构更改时,可能会面临安全风险或中断性变更。
建议在 2026 年 6 月 30 日之前过渡到 SDK v2。 有关 SDK v2 的详细信息,请参阅 什么是 Azure Machine Learning CLI 和 Python SDK v2? 和 SDK v2 参考。
小窍门
本文介绍 v1 数据存储和数据集。 有关数据访问的建议 v2 方法,请参阅 创建和管理数据资产。
使用 数据存储 和 数据集 将 Azure Machine Learning Studio 连接到 Azure 存储服务中的数据。 数据存储安全地管理连接信息,而数据集则将数据打包成可用于机器学习工作流任务(例如训练)的对象。
先决条件
一个 Azure 订阅。 如果没有Azure订阅,请在开始前创建试用版。 试用 免费或付费版本的 Azure Machine Learning。
Azure Machine Learning工作区。 创建工作区资源。
- 创建工作区时,门户会自动将Azure Blob 存储容器和Azure 文件共享注册为数据存储库。 它分别命名它们
workspaceblobstore和workspacefilestore。 门户将workspaceblobstore设置为默认数据存储。 对于充足的 Blob 存储资源,请使用workspaceblobstore。 对于更多 blob 存储资源,您需要一个具有支持的存储类型的 Azure 存储帐户。
- 创建工作区时,门户会自动将Azure Blob 存储容器和Azure 文件共享注册为数据存储库。 它分别命名它们
了解数据存储和数据集
下表定义了数据存储和数据集,并汇总了每个数据存储和数据集的优点。
| 物体 | 说明 | 好处 |
|---|---|---|
| 数据存储 | 在 Azure与工作区关联的 Key Vault 中安全地连接到存储服务,并存储连接信息(例如订阅 ID 和令牌授权)。 | 由于信息安全存储,因此不会将身份验证凭据或原始数据源置于危险状态。 不再需要在脚本中硬编码这些值。 |
| 数据集 | 数据集的创建还会创建对数据源位置的引用,及其元数据的副本。 通过使用数据集,可以在模型训练期间访问数据、共享数据、与其他用户协作,以及使用 pandas 等开源库进行数据浏览。 | 由于数据集的计算迟缓,并且数据仍保留在其现有位置,因此在存储中保留一个数据副本。 此外,不会产生额外的存储成本,避免了对原始数据源的意外更改,ML 工作流性能提高。 |
有关数据存储和数据集在整体 Azure Machine Learning 数据访问工作流中的位置的详细信息,请参阅 安全访问数据。
创建数据存储
您可以从 支持的 Azure 存储解决方案 创建数据存储。 对于不支持的存储解决方案,为了在 ML 试验期间节省数据出口成本,必须将数据移动数据到受支持的Azure存储解决方案。 有关数据存储的详细信息,请参阅 Azure Machine Learning 数据存储。
可以创建具有基于凭据的访问或基于标识的访问的数据存储。
使用Azure Machine Learning studio创建新的数据存储。
重要
如果数据存储帐户位于虚拟网络中,则需要完成额外的配置步骤,以确保工作室可以访问数据。 若要详细了解相应的配置步骤,请参阅 网络隔离和隐私。
- 登录到 Azure Machine Learning studio。
- 在左窗格的“资产”下,选择“数据”。
- 在顶部,选择“数据存储”。
- 选择“+创建”。
- 完成表单以创建和注册新的数据存储。 表单根据所选内容智能地更新Azure存储类型和身份验证类型。 有关在何处查找填充此表单所需的身份验证凭据的详细信息,请参阅 “查找身份验证凭据”。
以下屏幕截图显示了 Azure blob 数据存储创建面板:


创建数据资产
创建数据存储后,创建一个数据集以与数据交互。 数据集将您的数据打包成一个惰性评估的可供使用的对象,用于机器学习任务,例如训练。 有关数据集的详细信息,请参阅 创建Azure Machine Learning数据集。
数据集有两种类型:FileDataset 和 TabularDataset. 当数据采用列和行的结构化格式时,例如 、.csv、.tsv 或 .parquet 文件,或者 SQL 查询结果,请使用 .json。 需要引用完整文件(如图像、文本文件或任何不适合表格结构的格式)时,请使用 FileDataset 。
以下步骤介绍如何在 Azure Machine Learning studio 中创建数据集。
注意
Azure Machine Learning studio会自动将创建的数据集注册到工作区。
在左侧导航的“资产”下,选择“数据”。 在“ 数据资产 ”选项卡上,选择“ 创建”,如以下屏幕截图所示:
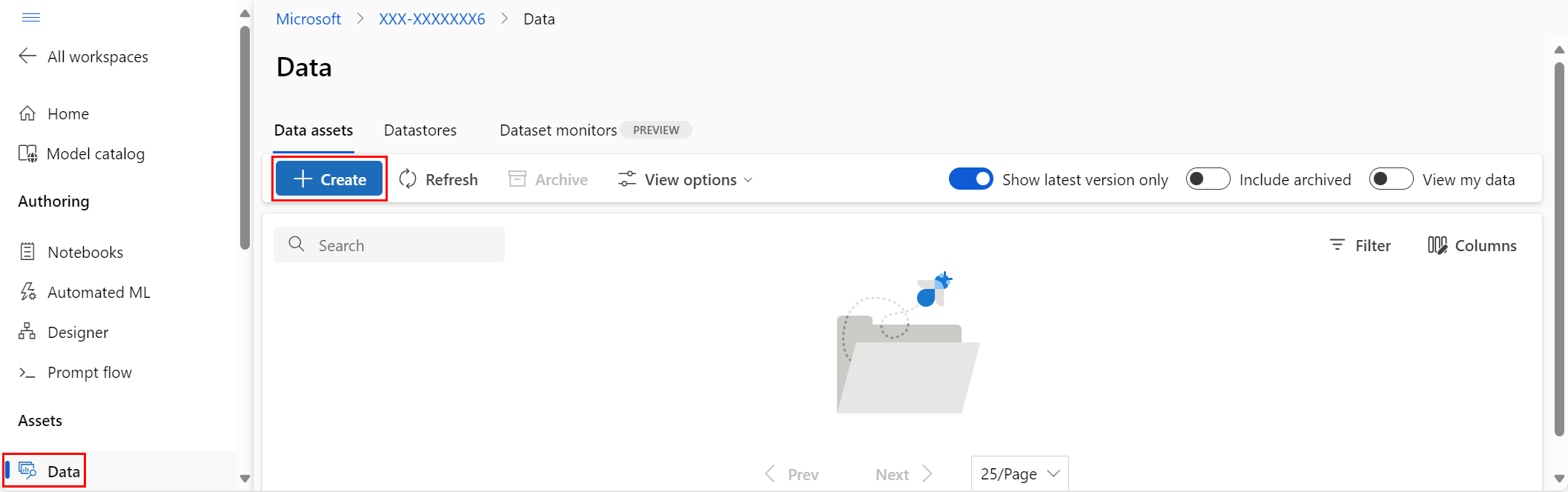
输入数据资产的名称和可选说明。 然后,在 “类型”下,选择数据集类型( 文件 或 表格),如以下屏幕截图所示:
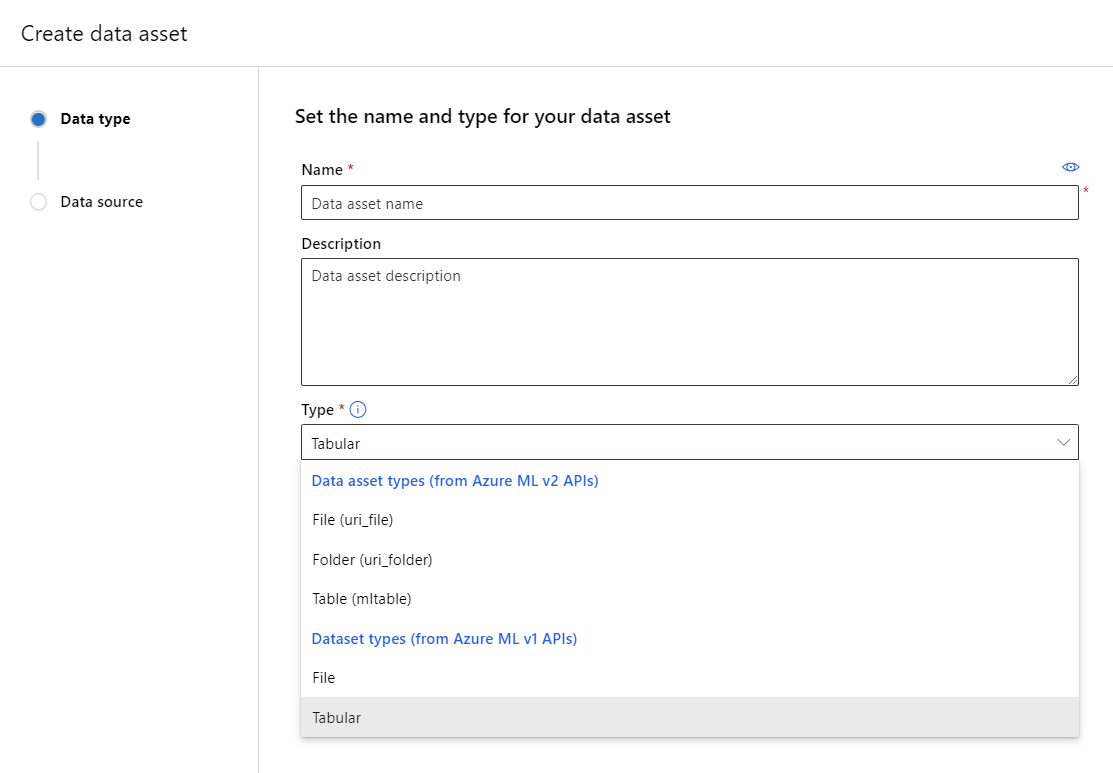
“ 数据源 ”窗格随即打开,如以下屏幕截图所示:
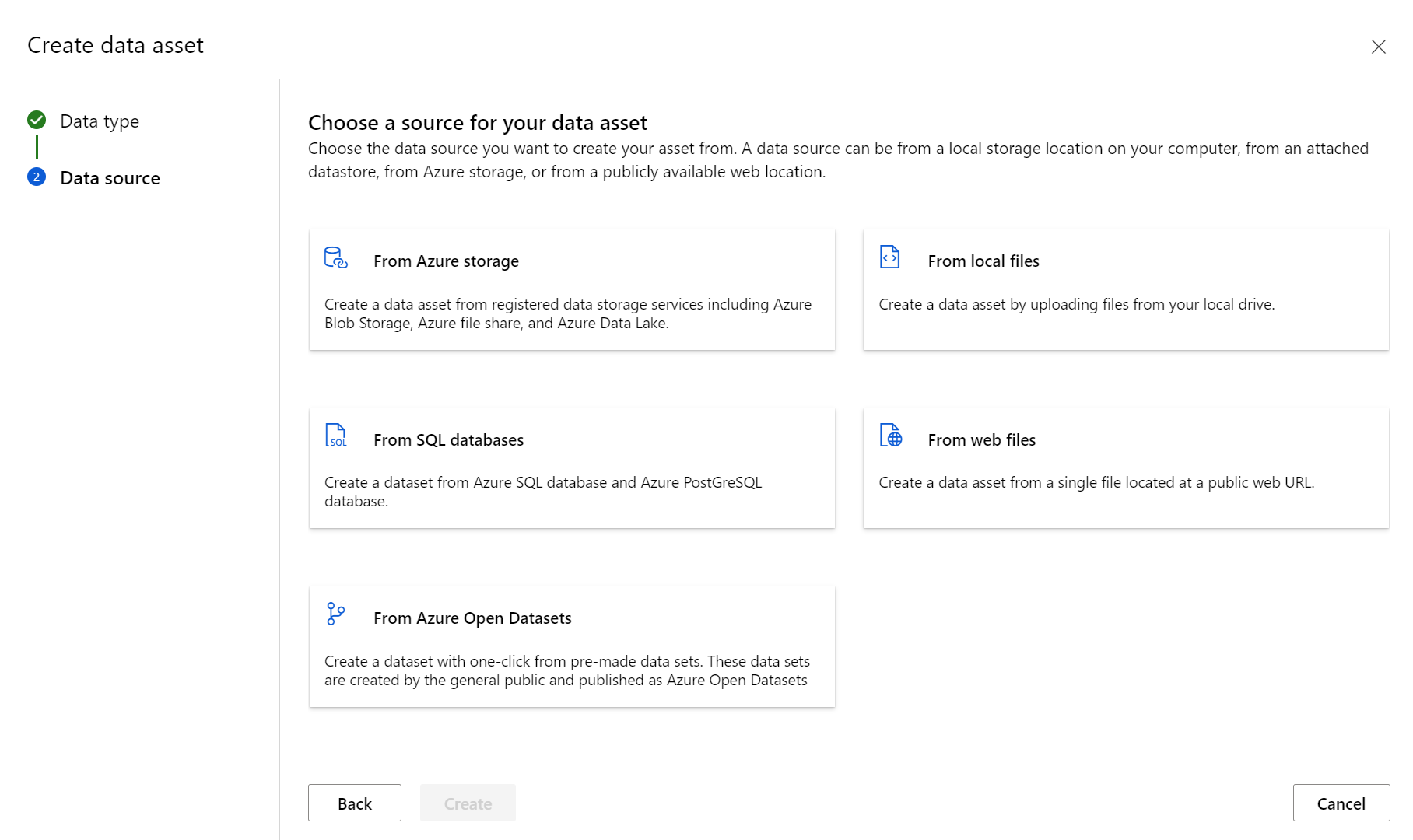


您有不同的数据源选项。 对于已存储在 Azure 中的数据,请选择 来自 Azure 存储。 若要从本地驱动器上传数据,请选择 “从本地文件”。 对于存储在公共 Web 位置的数据,请选择 “从 Web 文件”。 还可以从 SQL 数据库创建数据资产。
在文件选择步骤中,选择Azure应存储数据的位置以及要使用的数据文件。
- 如果数据位于虚拟网络中,请启用 跳过验证 。 有关详细信息,请参阅在虚拟网络中使用Azure Machine Learning studio。
按照步骤为数据资产设置数据分析设置和架构。 设置会根据文件类型进行预填充,可以在创建数据资产之前进一步配置设置。
到达 “审阅 ”步骤时,请选择最后一页上的 “创建 ”。
预览和分析数据资产
创建数据集后,验证您可以在 Azure Machine Learning Studio 中查看预览和概要:
在左侧导航中的 “资产 ”下,选择 “数据 ”,如以下屏幕截图所示:
选择要查看的数据集的名称。
选择”浏览“选项卡。
选择 “预览 ”选项卡,如以下屏幕截图所示:
选择“ 配置文件 ”选项卡,如以下屏幕截图所示:
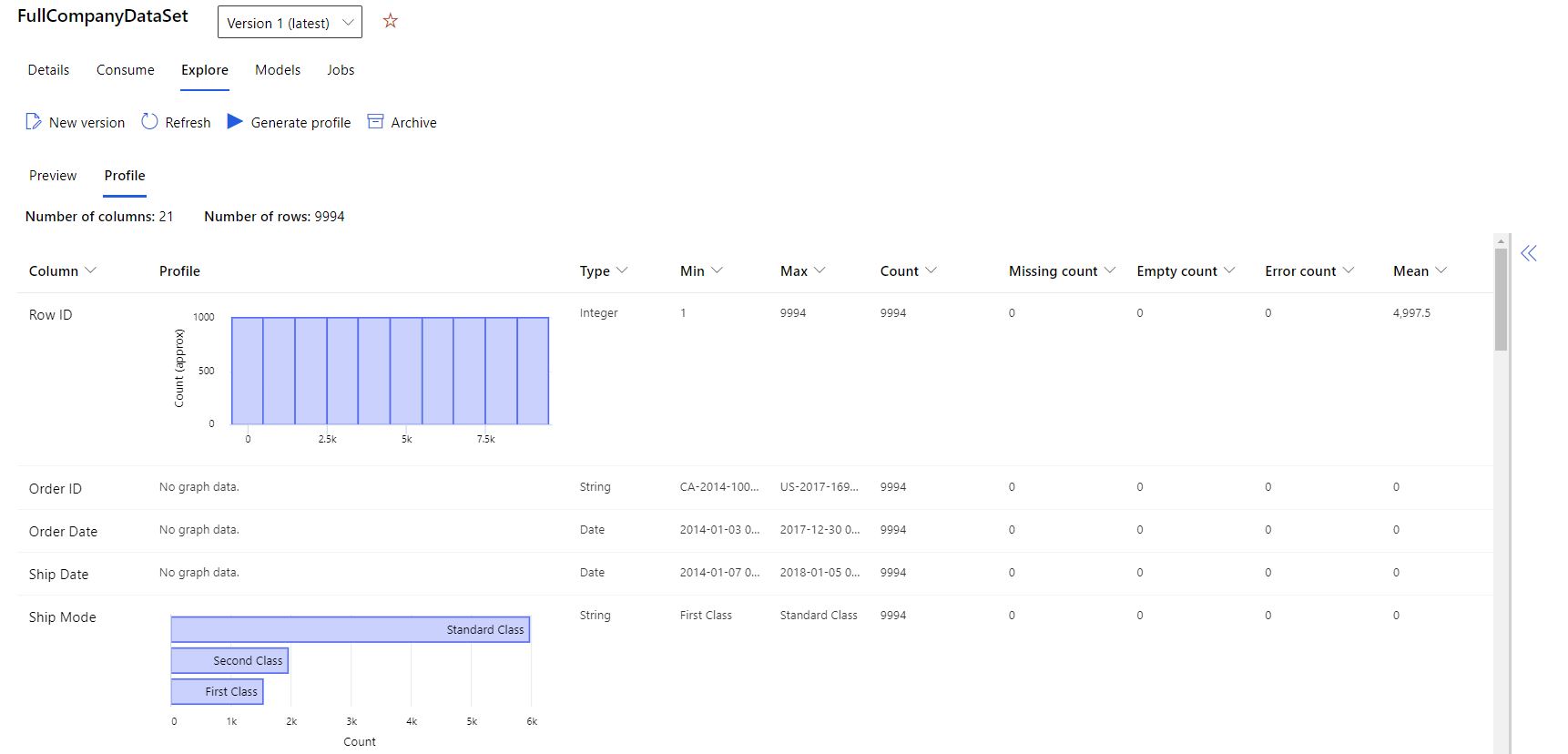
数据概况统计信息参考
Azure Machine Learning数据集数据配置文件包含以下统计信息。 使用这些指标来验证数据集是否为 ML 就绪。
注意
对于具有不相关类型的特征,将显示空白条目。
| 统计信息 | 说明 |
|---|---|
| 功能 | 汇总列名。 |
| 用户资料 | 基于推断类型的内嵌可视化。 字符串、布尔值和日期都有值计数。 小数(数值)具有近似的直方图。 这些可视化效果可快速了解数据分布。 |
| 类型分布 | 列内类型值的直接计数。 空值是它自己的类型,因此此可视化效果可以检测异常值或缺失值。 |
| 类型 | 推断的列类型。 可能的值包括:字符串、布尔值、日期和小数。 |
| 最小值 | 列的最小值。 对于类型没有固有排序的特征(例如布尔值),会出现空白条目。 |
| 最大 | 列的最大值。 |
| 计数 | 列中缺失和非缺失条目的总数。 |
| 非缺失计数 | 列中的非缺失条目数。 空字符串和错误被视为值,因此它们不会计入“缺失计数”。 |
| 分位数 | 每个分位的近似值,以提供数据分布感。 |
| 平均值 | 列的平均值或算术平均值。 |
| 标准偏差 | 测量此列数据的分散量或变体量。 |
| 差异 | 测量此列的数据与其平均值的分布距离。 |
| 偏度 | 度量此列的数据与正态分布的区别。 |
| 峰度 | 与正态分布相比,测量此列数据的“尾部特征”程度。 |
管理存储访问和权限
若要安全地连接到Azure存储服务,必须有权访问相应的数据存储。 此访问取决于用于注册数据存储的身份验证凭据。
虚拟网络
如果数据存储帐户位于 virtual network 中,则需要完成额外的配置步骤,以确保Azure Machine Learning有权访问数据。 若要了解详细信息,请参阅 在虚拟网络中使用Azure Machine Learning studio。 确保在创建和注册数据存储时应用相应的配置步骤。
访问验证
警告
不支持跨租户访问存储帐户。 如果你的方案需要跨租户访问,请联系 (Azure Machine Learning 数据支持团队),以获取有关自定义代码解决方案的帮助。
初始数据存储创建和注册过程的一部分,Azure Machine Learning会自动验证基础存储服务是否存在,并且用户提供的主体(用户名、服务主体或 SAS 令牌)有权访问指定的存储。
创建数据存储后,仅对需要访问基础存储容器的方法执行此验证。 每次检索数据存储对象时,不会执行验证。 例如,从数据存储中下载文件时,会进行验证。 但是,如果想更改默认数据存储,则不会进行验证。
若要验证对基础存储服务的访问,请根据要创建的数据存储类型提供帐户密钥、共享访问签名 (SAS) 令牌或服务主体。 存储类型矩阵列出了与各种数据存储类型对应的受支持的身份验证类型。
查找身份验证凭据
可以在 Azure 门户中找到帐户密钥、SAS 令牌和服务主体信息。
若要获取用于身份验证的帐户密钥,请在左窗格中选择 “存储帐户 ”,然后选择要注册的存储帐户:
- “ 概述 ”页提供帐户名称、容器和文件共享名称等信息。
- 展开左侧导航中的 “安全性 + 网络 ”节点。
- 选择“访问密钥”。
- 可用的键值用作 帐户密钥 值。
若要获取用于身份验证的 SAS 令牌,请在左窗格中选择 “存储帐户 ”,然后选择所需的存储帐户:
- 若要获取 Access 密钥 值,请展开左侧导航中的 “安全性 + 网络 ”节点。
- 选择 “共享访问签名”。
- 完成生成 SAS 值的过程。
若要使用 service principal 进行身份验证,请转到 App registrations并选择要使用的应用:
- 其对应的 “概述 ”页包含所需的信息,如租户 ID 和客户端 ID。
重要
- 若要更改Azure Storage帐户(帐户密钥或 SAS 令牌)的访问密钥,请务必将新凭据与工作区和连接到该帐户的数据存储同步。 有关详细信息,请参阅 同步更新的凭据。
- 如果您注销并重新注册同名的数据存储,而重新注册过程失败,那么您工作区的 Azure Key Vault 可能未启用软删除功能。 默认情况下,将为工作区创建的密钥保管库实例启用软删除。 但是,如果使用现有密钥保管库或在 2020 年 10 月之前创建了工作区,则可能无法启用它。 有关如何启用软删除的详细信息,请参阅 为现有密钥保管库启用软删除。
权限
对于 Azure blob 容器和 Azure Data Lake 第 2 代存储,请确保身份验证凭据具有 Storage Blob 数据读取者访问权限。 详细了解Storage Blob 数据读取器。 默认情况下,帐户 SAS 令牌没有权限。
对于数据 读取访问权限,身份验证凭据至少需要为容器和对象列出和读取权限。
对于数据写入权限,身份验证凭据还需要写入和添加权限。
使用数据集训练模型
创建和注册数据集后,可以在训练试验中引用它。 数据集支持与Azure Machine Learning训练管道和 AutoML 运行直接集成。 有关分步指南,请参阅使用Azure Machine Learning数据集训练模型。
排查常见问题
下表列出了连接到Azure存储时的常见问题和解决方法。
| 問题 | 解决方案 |
|---|---|
| 访问存储时权限被拒绝 | 验证您的身份或凭据是否具有 存储 Blob 数据读取者 角色。 有关详细信息,请参阅 Storage Blob Data Reader。 |
| SAS 令牌已过期或无效 | 生成具有正确权限和到期日期的新 SAS 令牌。 将更新的令牌与工作区同步。 有关详细信息,请参阅 同步更新的凭据。 |
| 在虚拟网络中被阻止的数据访问 | 验证是否已为虚拟网络访问配置Azure Machine Learning studio。 请参阅在虚拟网络中使用Azure Machine Learning studio。 |
| 数据存储重新注册失败 | 工作区的Azure Key Vault可能未启用软删除。 请参阅 打开现有密钥保管库的软删除。 |
| 跨租户访问失败 | 不支持跨租户访问存储帐户。 请联系 Azure Machine Learning 数据支持团队获取帮助。 |
相关内容
- 创建和管理数据资产(v2) -Azure Machine Learning 中数据访问的建议方法。
- 使用Azure Machine Learning数据集训练模型 - 使用在训练试验中注册的数据集。
- 通过 TabularDatasets 使用自动化机器学习 - AutoML 训练的分步示例。