适用于: Azure CLI ml 扩展 v2 (当前版本)Python SDK azure-ai-ml v2 (当前版本)
Azure CLI ml 扩展 v2 (当前版本)Python SDK azure-ai-ml v2 (当前版本)
Warning
Azure 机器学习中的外部源(预览版)和数据连接(预览版)导入数据已弃用,在 2026 年 9 月 30 日之后不可用。 在此之前,可以继续使用这些功能,而不会中断。 在该日期之后,依赖于它们的任何工作负荷都会中断。
建议的操作: 将外部数据导入迁移到 Microsoft Fabric ,并使用 Azure 机器学习数据存储在 Azure 机器学习中提供数据。
本文介绍如何将数据从外部源导入Azure Machine Learning平台。 成功的数据导入会自动创建并注册您在导入过程中提供名称的 Azure Machine Learning 数据资产。 Azure Machine Learning数据资产类似于 Web 浏览器书签(收藏夹)。 无需记住指向最常用的数据的长存储路径 (URI)。 相反,可以创建数据资产,然后使用友好名称访问该资产。
数据导入会创建源数据的缓存以及元数据,以便在Azure Machine Learning训练作业中更快、更可靠的数据访问。 数据缓存可避免网络和连接约束。 对缓存的数据进行版本控制以支持可重现性。 此功能为从SQL Server源导入的数据提供版本控制功能。 此外,缓存的数据还提供数据血统以支持审计任务。 数据导入在后台使用Azure Data Factory(ADF)管道,这意味着你可以避免与 ADF 的复杂交互。 Azure Machine Learning还处理 ADF 计算资源池大小、计算资源预配和拆解的管理。 此管理通过确定适当的并行化来优化数据传输。
传输的数据已分区并安全地存储为 Azure 存储中的 parquet 文件。 此存储可在训练期间更快地进行处理。 ADF 计算成本仅涉及用于数据传输的时间。 存储成本仅涉及缓存数据所需的时间,因为缓存的数据是从外部源导入的数据副本。 Azure存储主机外部源。
缓存功能涉及前期计算和存储成本。 但是,它能够收回成本,并且能够节省资金,因为与在训练期间直接连接到外部源数据相比,它降低了经常性的训练计算成本。 它将数据缓存为 parquet 文件,这使得作业训练更快、更可靠,从而防止大型数据集出现连接超时。 这种缓存会导致重新运行次数减少,训练失败次数更少。
可以从 Amazon S3、Azure SQL 和 Snowflake 导入数据。
重要
此功能目前处于公开预览状态。 此预览版在提供时没有附带服务级别协议,我们不建议将其用于生产工作负荷。 某些功能可能不受支持或者受限。
有关详细信息,请参阅 Azure 预览版的使用条款。
先决条件
若要创建和使用数据资产,需要做好以下准备:
注意
若要成功导入数据,请验证是否已为 SDK 安装了最新的 azure-ai-ml 包(版本 1.31.0 或更高版本),以及 ml 扩展(版本 2.37.0 或更高版本)。 Python 3.9 或更高版本是必需的。
如果有较旧的 SDK 包或 CLI 扩展,请使用选项卡部分中显示的代码删除旧包或 CLI 扩展并安装新扩展。 按照如下所示的 SDK 和 CLI 说明进行操作:
代码版本
az extension remove -n ml
az extension add -n ml --yes
az extension show -n ml #(the version value needs to be 2.37.0 or later)
pip install azure-ai-ml
pip show azure-ai-ml #(the version value needs to be 1.31.0 or later)
作为 mltable 数据资产从外部数据库导入
注意
外部数据库包括 Snowflake 和 Azure SQL。
以下代码示例可以从外部数据库导入数据。 负责处理导入操作的 connection 将确定外部数据库数据源元数据。 在此示例中,代码从 Snowflake 资源导入数据。 连接指向 Snowflake 源。 稍加修改,连接可以指向Azure SQL数据库源或其他受支持的数据库源。 从外部数据库源导入的资产 type 为 mltable。
创建 YAML 文件 <file-name>.yml:
$schema: http://azureml/sdk-2-0/DataImport.json
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# Datastore: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
type: mltable
name: <name>
source:
type: database
query: <query>
connection: <connection>
path: <path>
接下来,在 CLI 中运行以下命令:
> az ml data import -f <file-name>.yml
from azure.ai.ml.entities import DataImport
from azure.ai.ml.data_transfer import Database
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# path: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_import = DataImport(
name="<name>",
source=Database(connection="<connection>", query="<query>"),
path="<path>"
)
ml_client.data.import_data(data_import=data_import)
注意
此处的示例描述了 Snowflake 数据库的过程。 但是,此过程涵盖其他外部数据库格式,例如Azure SQL等。
转到 Azure Machine Learning studio。
在左侧导航栏的“资产”下,选择“数据”。 接下来,选择“数据导入”选项卡。然后选择“创建”,如以下屏幕截图所示:
截图显示在 Azure Machine Learning studio UI 中创建新的数据导入。
在“数据源”屏幕上,选择“Snowflake”,然后选择“下一步”,如下方的屏幕截图所示:
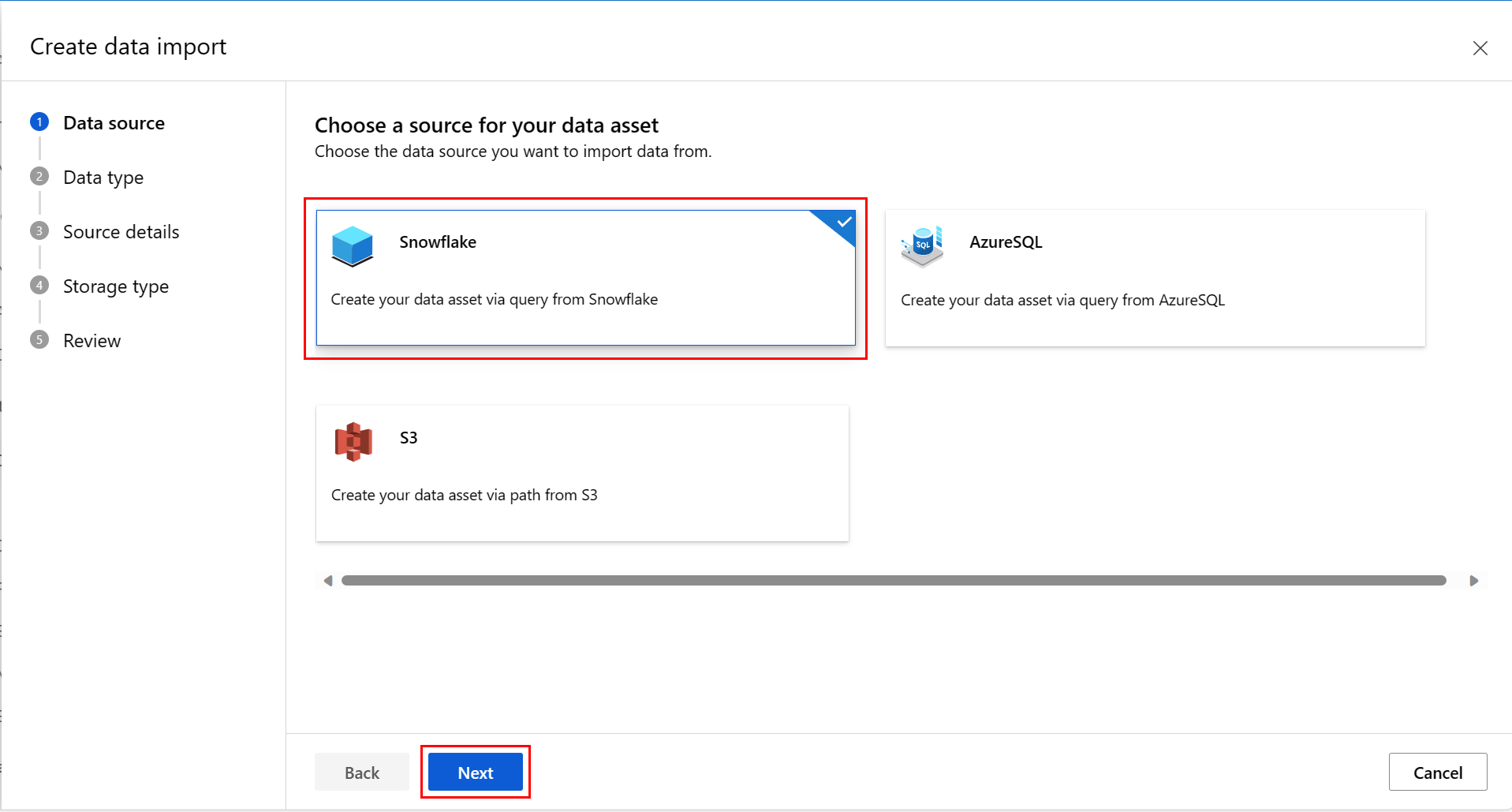
在“数据类型”屏幕上填写值。 “类型”值默认为“表(mltable)”。 然后选择“下一步”,如下方的屏幕截图所示:
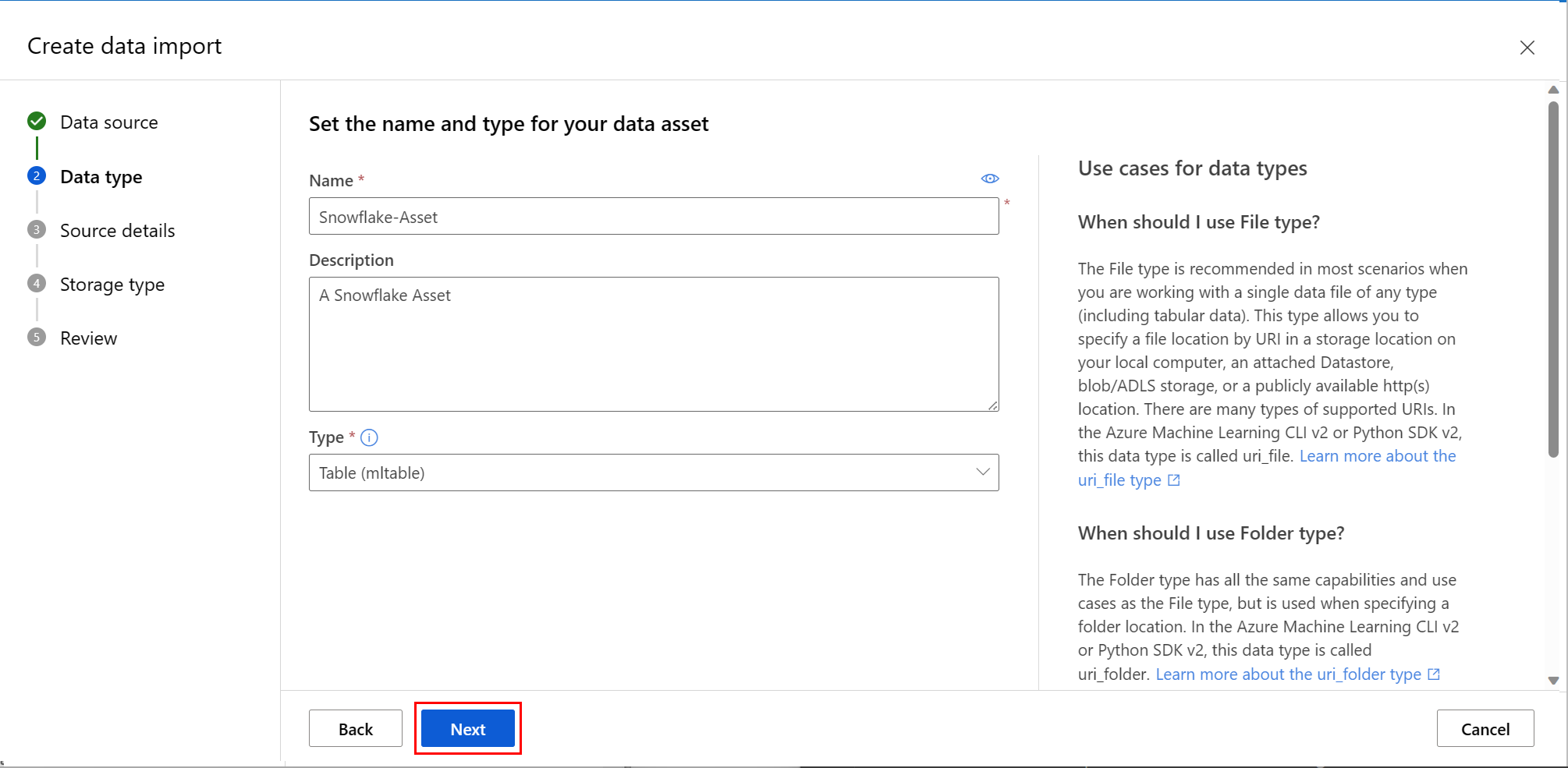
在 “创建数据导入 ”屏幕上,填写值,然后选择“ 下一步”,如以下屏幕截图所示:
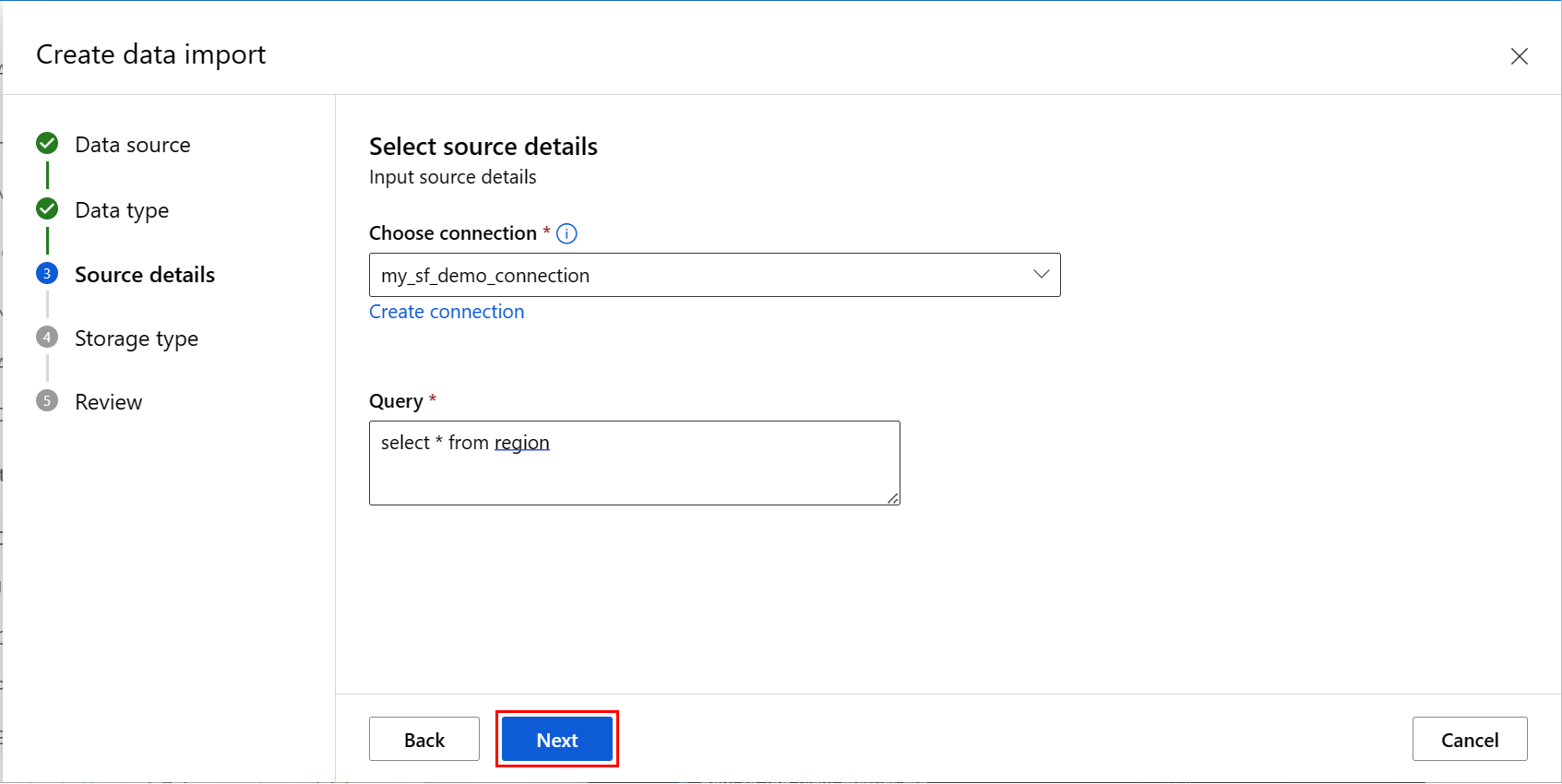
填写“ 选择要输出的数据存储 ”屏幕上的值,然后选择“ 下一步”,如以下屏幕截图所示。 默认选择“工作区托管数据存储”;选择托管数据存储时,系统会自动分配路径。 如果选择“工作区托管数据存储”,将显示“自动删除设置”下拉列表。 默认情况下会提供 30 天的数据删除时段,如何管理导入的数据资产说明了如何更改此值。
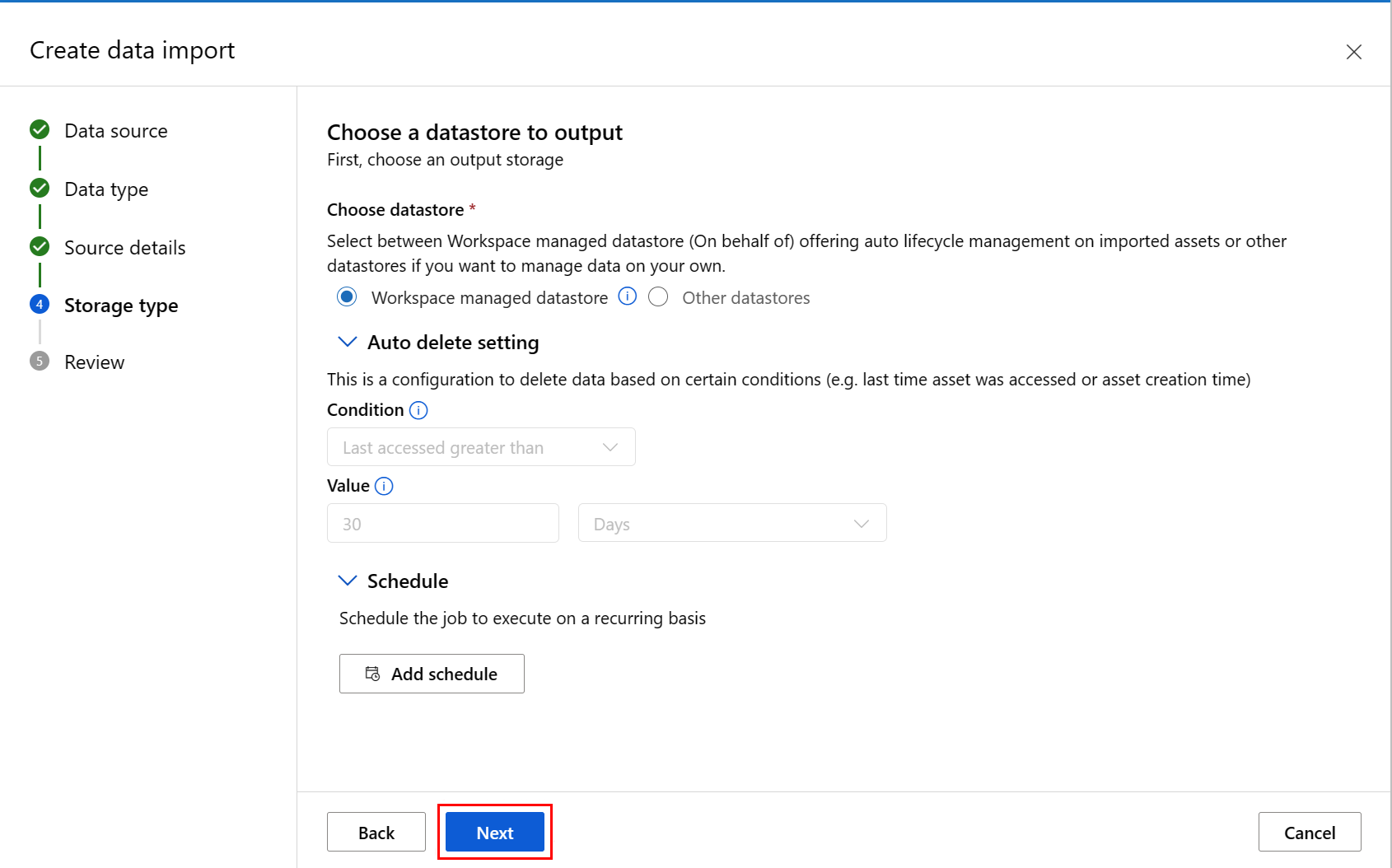
注意
若要选择自己的数据存储,请选择“其他数据存储”。 在这种情况下,必须选择数据缓存位置的路径。
可以添加计划。 选择 “添加计划” ,如以下屏幕截图所示:
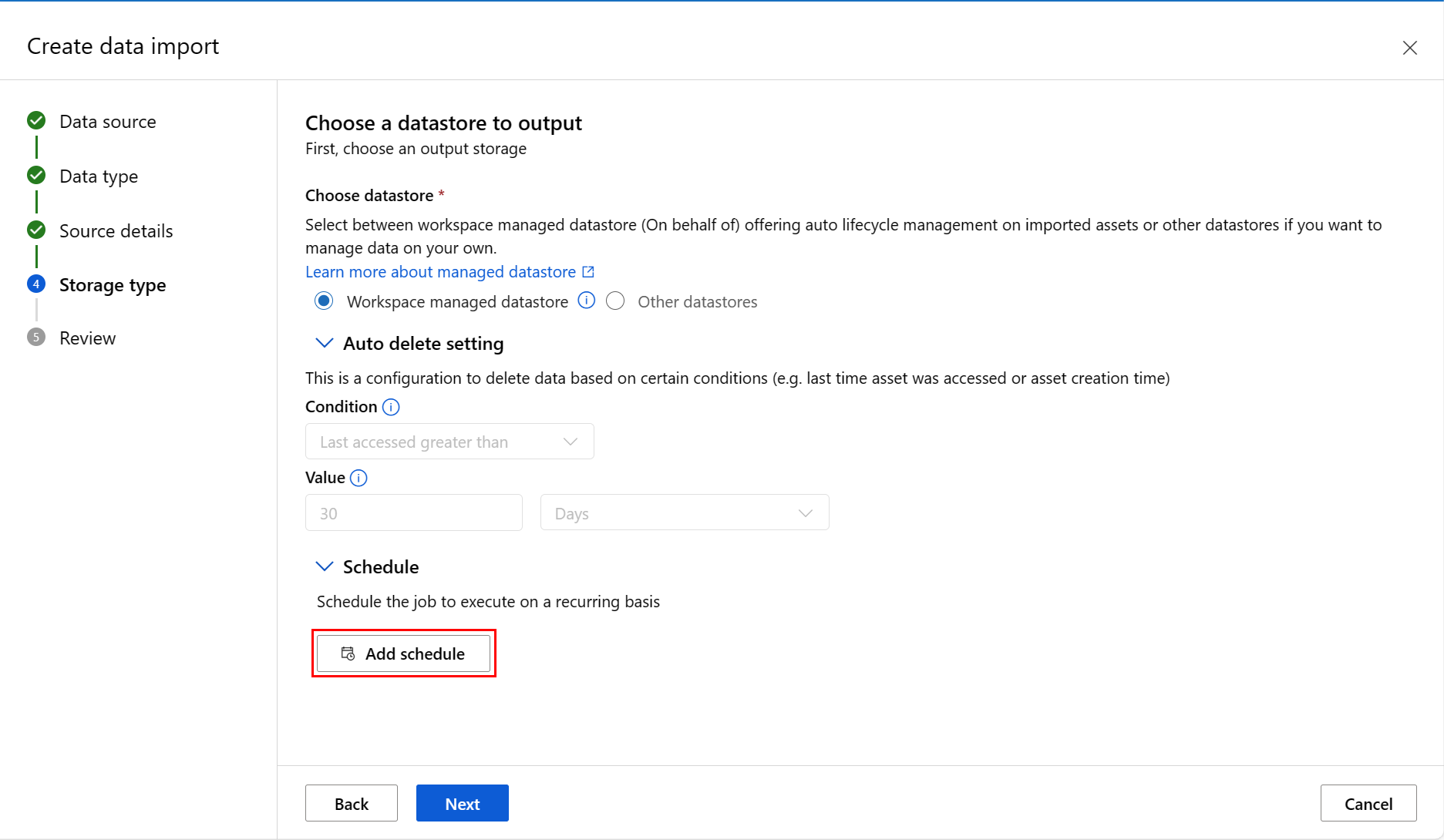
此时会打开一个新面板,可在其中定义“重复”计划或“Cron”计划。 屏幕截图显示了重复计划的界面:
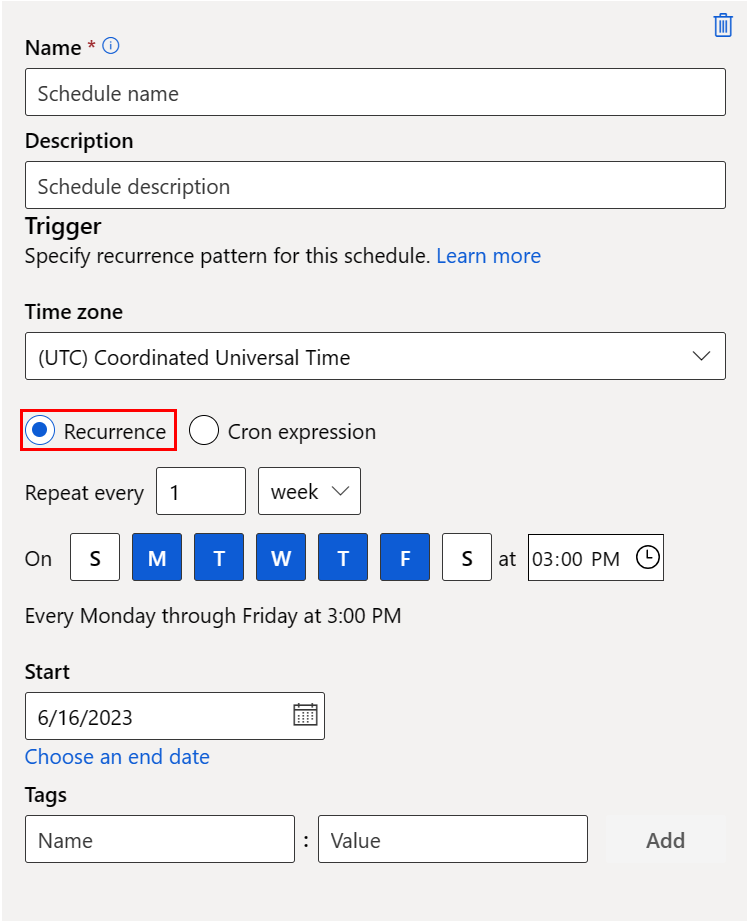
- 名称:工作区中计划的唯一标识符。
-
描述:计划说明。
- 触发器:计划的重复模式,其包括以下属性。
- 时区:触发时间是基于此时区计算的;默认情况下为 (UTC) 协调世界时。
- 重复或 Cron 表达式:选择“重复”以指定重复模式。 在“重复”选项下,您可以指定重复频率 - 按分钟、小时、天、周或月。
- 开始:计划从此日期开始首次变为活动状态。 默认情况下,此计划的创建日期为。
-
结束:计划在此日期之后变为非活动状态。 默认情况下,它是 NONE,这意味着计划始终处于活动状态,直到手动禁用它。
- 标签:所选的日程标签。
注意
开始指定计划时区的开始日期和时间。 如果省略 “开始”,开始时间等于计划创建时间。 如果开始时间在过去,第一个作业将在下一个预计的运行时间开始。
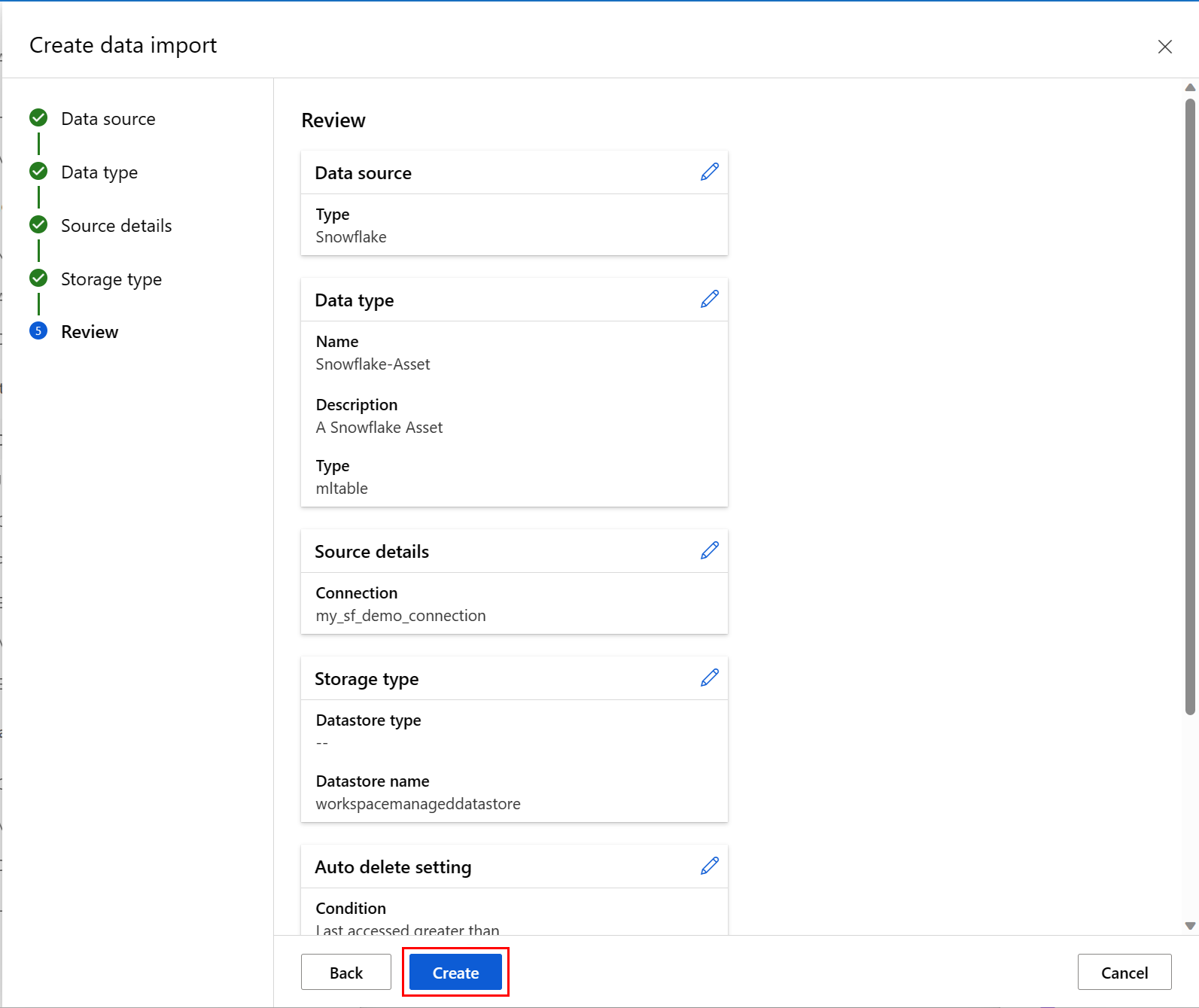
以下屏幕截图显示了此过程的最后一个屏幕。 查看你的选择,然后选择“ 创建”。 在此屏幕和此过程中的其他屏幕中,选择 “返回 ”以移动到早期屏幕以更改值选择。
以下屏幕截图显示了 Cron 计划的面板:
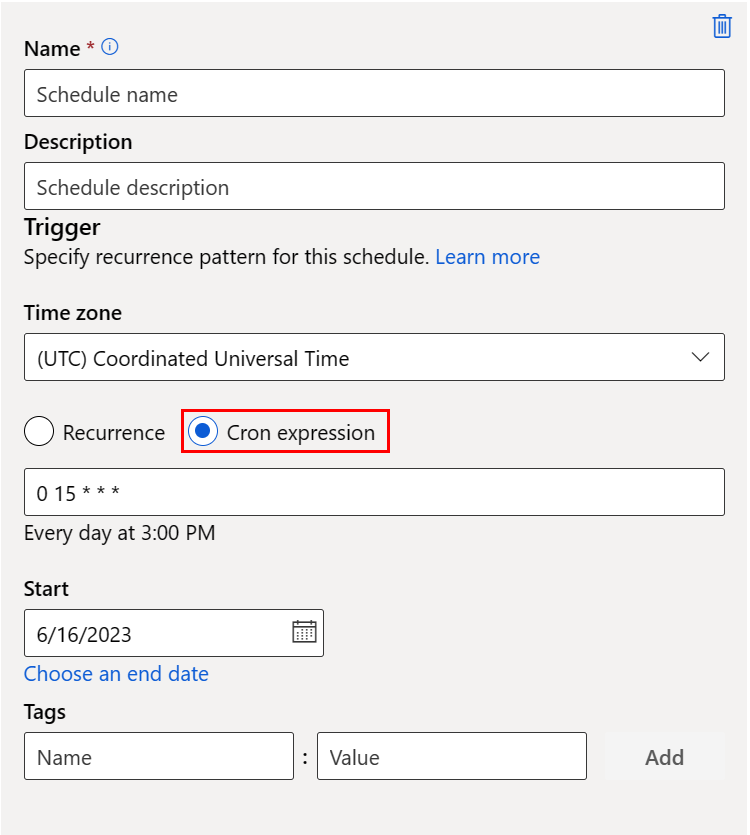
名称:工作区中计划的唯一标识符。
描述:计划说明。
触发器:计划的重复模式,其包括以下属性。
时区:触发时间是基于此时区计算的;默认情况下为 (UTC) 协调世界时。
重复或 Cron 表达式:选择 cron 表达式以指定 cron 详细信息。
(必需)expression 使用标准 crontab 表达式来表达定期计划。 单个表达式由 5 个空格分隔的字段组成:
MINUTES HOURS DAYS MONTHS DAYS-OF-WEEK
有关 crontab 表达式的详细信息,请访问 GitHub 上的 Crontab 表达式 wiki。
重要
DAYS 和 MONTH 不受支持。 如果传递其中一个值,则会将其忽略为 *。
- 开始:计划从此日期开始首次变为活动状态。 默认情况下,此计划的创建日期为。
-
结束:计划在此日期之后变为非活动状态。 默认情况下,它是 NONE,这意味着计划始终处于活动状态,直到手动禁用它。
- 标签:所选的日程标签。
注意
开始指定计划时区的开始日期和时间。 如果省略 “开始”,开始时间等于计划创建时间。 如果开始时间在过去,第一个作业将在下一个预计的运行时间开始。
以下屏幕截图显示了此过程的最后一个屏幕。 查看你的选择,然后选择“ 创建”。 在此屏幕和此过程中的其他屏幕中,选择 “返回 ”以移动到早期屏幕以更改值选择。
从外部文件系统将数据作为文件夹数据资产导入
注意
Amazon S3 数据资源可用作外部文件系统资源。
负责处理数据导入操作的 connection 将确定外部数据源方面。 连接将 Amazon S3 存储桶定义为目标。 连接需要有效的 path 值。 从外部文件系统源导入的资产值的 type 为 uri_folder。
下一个代码示例从 Amazon S3 资源导入数据。
创建 YAML 文件 <file-name>.yml:
$schema: http://azureml/sdk-2-0/DataImport.json
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# path: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
type: uri_folder
name: <name>
source:
type: file_system
path: <path_on_source>
connection: <connection>
path: <path>
接下来,在 CLI 中执行以下命令:
> az ml data import -f <file-name>.yml
from azure.ai.ml.entities import DataImport
from azure.ai.ml.data_transfer import FileSystem
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# path: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_import = DataImport(
name="<name>",
source=FileSystem(connection="<connection>", path="<path_on_source>"),
path="<path>"
)
ml_client.data.import_data(data_import=data_import)
转到 Azure Machine Learning studio。
在左侧导航栏的“资产”下,选择“数据”。 接下来,选择“数据导入”选项卡。然后选择“ 创建 ”,如以下屏幕截图所示:
屏幕截图显示在 Azure Machine Learning Studio UI 中创建数据导入。
在 “数据源 ”屏幕上,选择 “S3”,然后选择“ 下一步”,如以下屏幕截图所示:
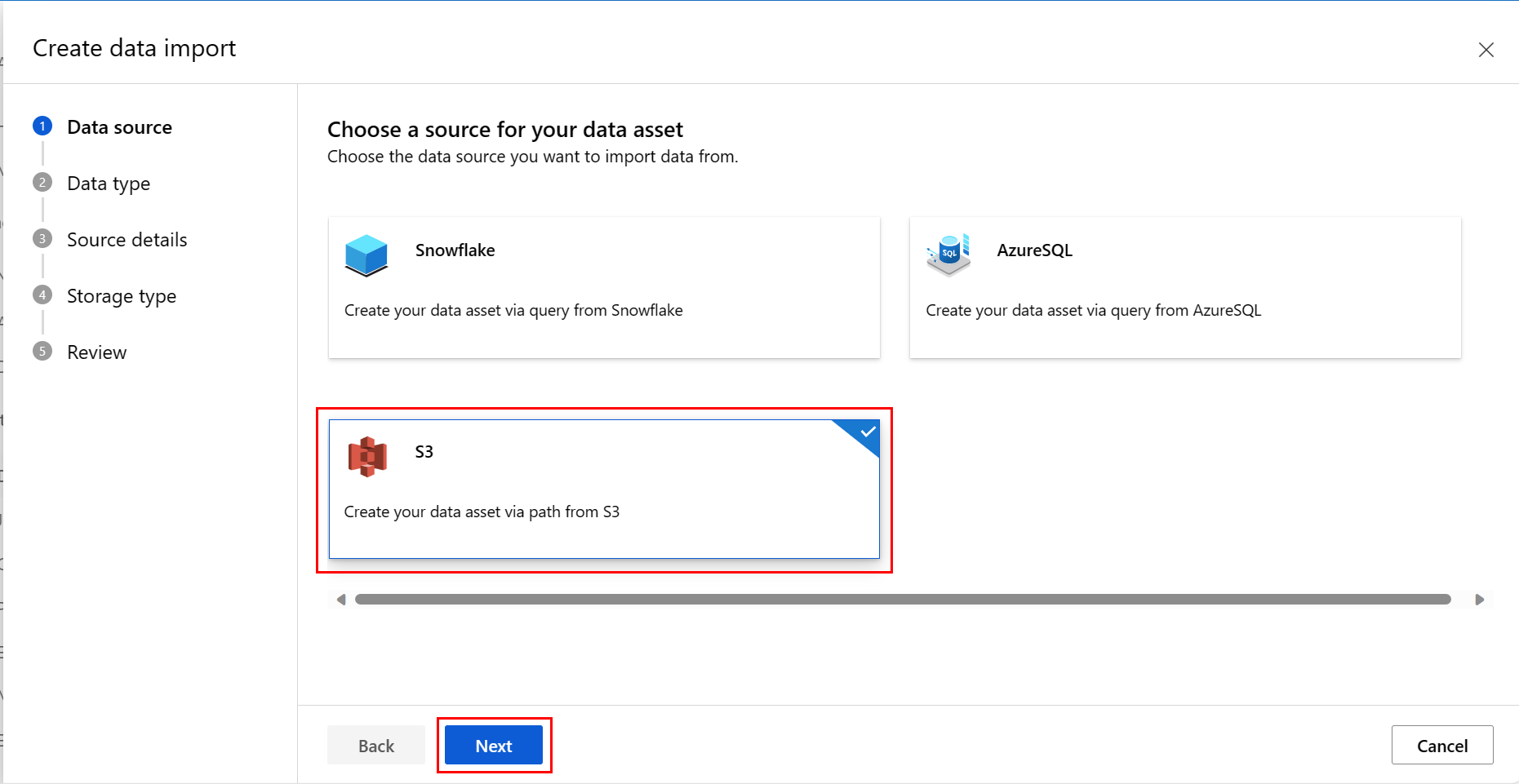
在 “数据类型” 屏幕上,填写值。
类型值默认为文件夹 (uri_folder)。 然后选择“ 下一步”,如以下屏幕截图所示:

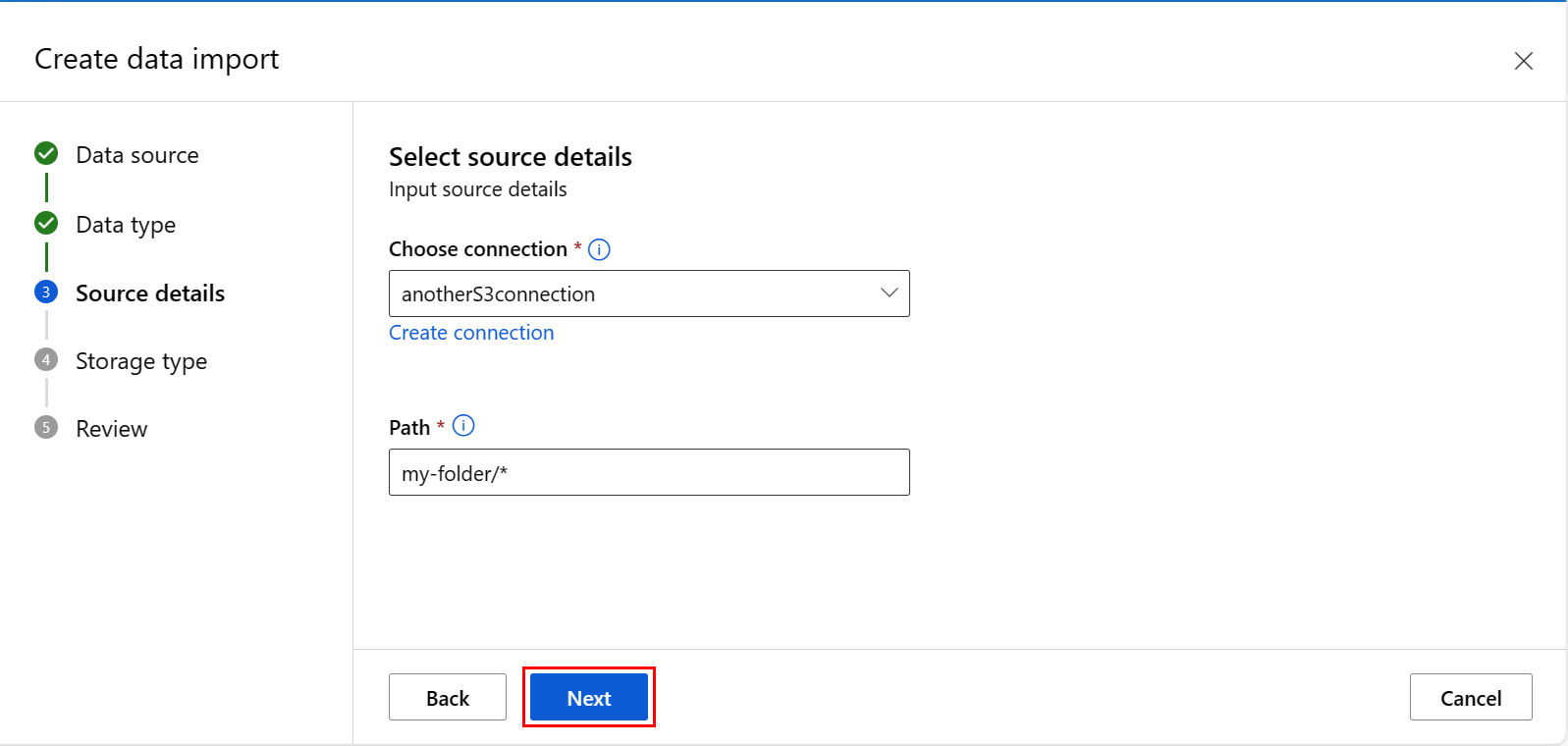
在 “创建数据导入 ”屏幕上,填写值,然后选择“ 下一步”,如以下屏幕截图所示:
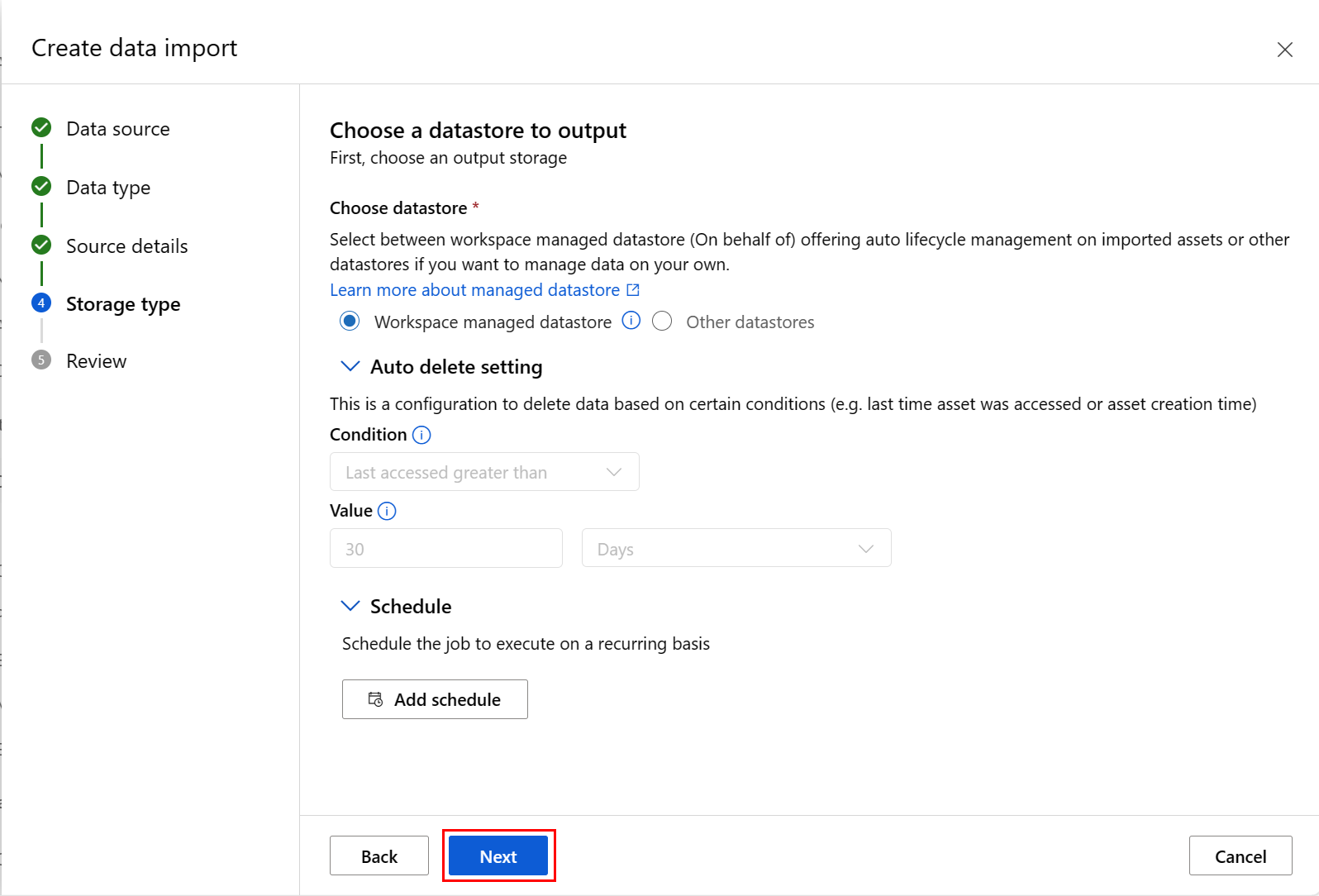
填写“ 选择要输出的数据存储 ”屏幕上的值,然后选择“ 下一步”,如以下屏幕截图所示。 默认选择“工作区托管数据存储”;选择托管数据存储时,系统会自动分配路径。 如果选择“工作区托管数据存储”,将显示“自动删除设置”下拉列表。 默认情况下会提供 30 天的数据删除时段,如何管理导入的数据资产说明了如何更改此值。
可以添加计划。 选择 “添加计划” ,如以下屏幕截图所示:
此时会新开一个面板,以便定义“重复性”计划或“Cron”计划。 以下屏幕截图显示了重复计划的面板:
- 名称:工作区中计划的唯一标识符。
-
描述:计划说明。
- 触发器:计划的重复模式,其包括以下属性。
- 时区:触发时间是基于此时区计算的;默认情况下为 (UTC) 协调世界时。
- 重复或 Cron 表达式:选择“重复”以指定重复模式。 在“重复”选项下,您可以指定重复频率 - 按分钟、小时、天、周或月。
- 开始:计划从此日期开始首次变为活动状态。 默认情况下,此计划的创建日期为。
-
结束:计划在此日期之后变为非活动状态。 默认情况下,它是 NONE,这意味着计划始终处于活动状态,直到手动禁用它。
- 标签:所选的日程标签。
注意
开始指定计划时区的开始日期和时间。 如果省略 “开始”,开始时间等于计划创建时间。 如果开始时间在过去,第一个作业将在下一个预计的运行时间开始。
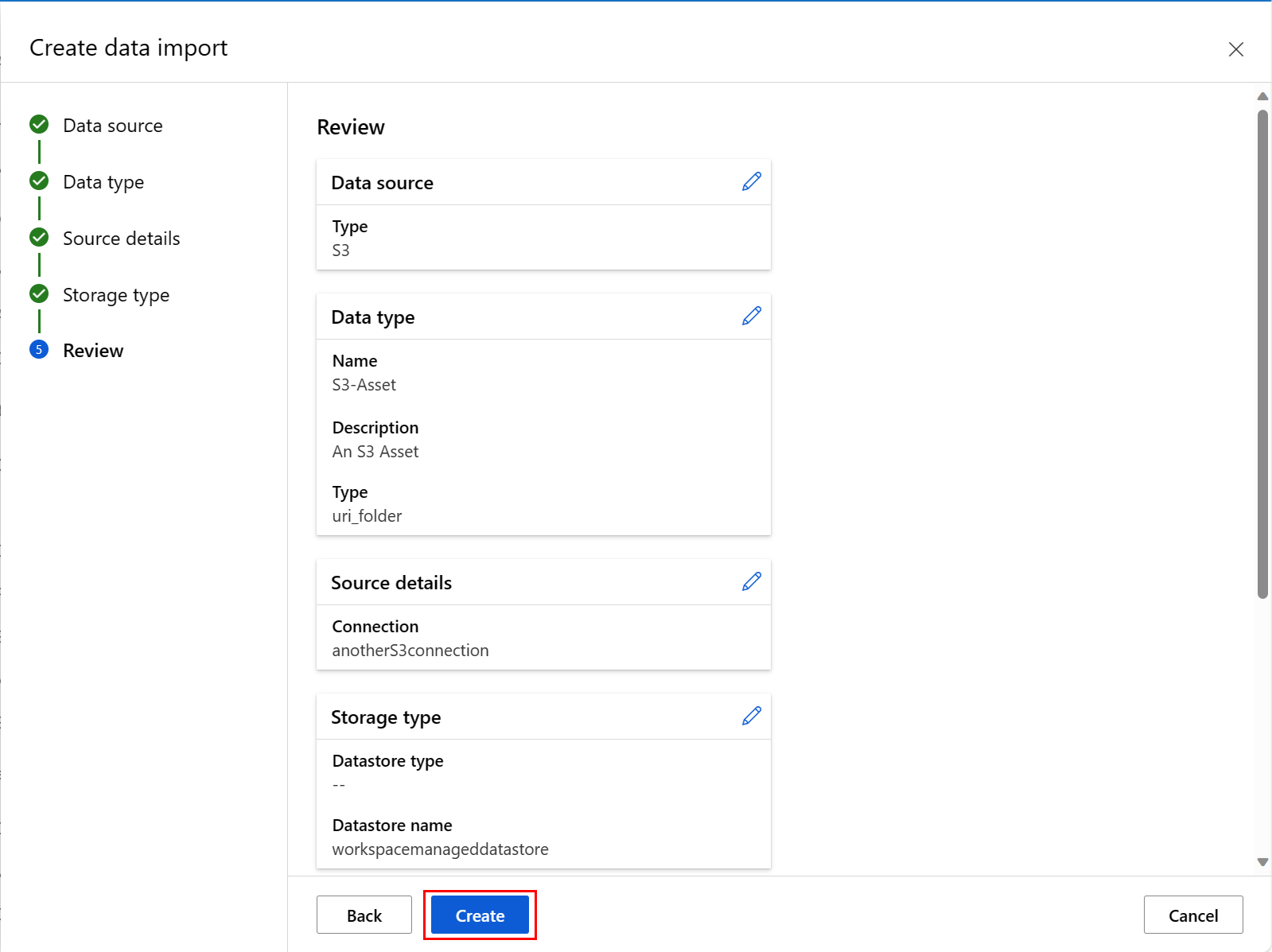
在此过程的最后一个屏幕中查看你的选择,然后选择“ 创建”。 在此屏幕和此过程中的其他屏幕中,如果要更改值选择,请选择 “返回 ”以移动到早期屏幕。
查看你的选择,然后选择“ 创建”。 在此屏幕和此过程中的其他屏幕中,选择 “返回 ”以移动到早期屏幕以更改值选择。
以下屏幕截图显示了 Cron 计划的面板:
名称:工作区中计划的唯一标识符。
描述:计划说明。
触发器:计划的重复模式,其包括以下属性。
时区:触发时间是基于此时区计算的;默认情况下为 (UTC) 协调世界时。
重复或 Cron 表达式:选择 cron 表达式以指定 cron 详细信息。
(必需)expression 使用标准 crontab 表达式来表达定期计划。 单个表达式由 5 个空格分隔的字段组成:
MINUTES HOURS DAYS MONTHS DAYS-OF-WEEK
有关 crontab 表达式的详细信息,请访问 GitHub 上的 Crontab 表达式 wiki。
重要
DAYS 和 MONTH 不受支持。 如果传递其中一个值,则会将其忽略为 *。
- 开始:计划从此日期开始首次变为活动状态。 默认情况下,此计划的创建日期为。
-
结束:计划在此日期之后变为非活动状态。 默认情况下,它是 NONE,这意味着计划始终处于活动状态,直到手动禁用它。
- 标签:所选的日程标签。
注意
开始指定计划时区的开始日期和时间。 如果省略 “开始”,开始时间等于计划创建时间。 如果开始时间在过去,第一个作业将在下一个预计的运行时间开始。
以下屏幕截图显示了此过程的最后一个屏幕。 查看你的选择,然后选择“ 创建”。 在此屏幕和此过程中的其他屏幕中,选择 “返回 ”以移动到早期屏幕以更改值选择。
检查外部数据源的导入状态
数据导入操作是一种异步操作。 这可能需要很长时间。 通过 CLI 或 SDK 提交导入数据操作后,Azure Machine Learning服务可能需要几分钟才能连接到外部数据源。 然后,服务启动数据导入,并处理数据缓存和注册。 导入数据所需的时间还取决于源数据集的大小。
以下示例返回提交的数据导入活动的状态。 命令或方法使用数据资产名称作为输入来确定数据具体化的状态。
> az ml data list-materialization-status --name <name>
from azure.ai.ml.entities import DataImport
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
ml_client.data.list_materialization_status(name="<name>")
后续步骤












