Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
在本文中,在 Azure 机器学习工作室中使用 Azure 机器学习自动化 ML 设置自动化机器学习训练作业。 此方法允许你在不编写代码的情况下设置作业。 自动化 ML 是 Azure 机器学习为特定数据选择最佳机器学习算法的过程。 通过该过程,可快速生成机器学习模型。 有关详细信息,请参阅自动化 ML 过程的概述。
本文简要概述了如何在工作室中使用自动化 ML。 以下文章提供有关使用特定机器学习模型的详细说明:
- 分类:教程:在工作室中使用自动化 ML 训练分类模型
- 时序预测:教程:在工作室中使用自动化 ML 预测需求
- 自然语言处理 (NLP):设置自动化 ML 以训练 NLP 模型(Azure CLI 或 Python SDK)
- 计算机视觉:设置自动化 ML 以训练计算机视觉模型(Azure CLI 或 Python SDK)
- 回归:使用自动化 ML (Python SDK) 训练回归模型
先决条件
Azure 订阅。 可创建 Azure 机器学习的免费或付费帐户。
一个 Azure 机器学习工作区或一个计算实例。 要准备这些资源,请参阅快速入门:开始使用 Azure 机器学习。
用于自动化的 ML 训练作业的数据资产。 本文介绍如何选择现有数据资产或从数据源创建数据资产,例如本地文件、Web URL 或数据存储。 有关详细信息,请参阅创建和管理数据资产。
重要
对于训练数据,有两个要求:
- 数据必须采用表格形式。
- 要预测的值(目标列)必须存在于数据中。
创建试验
按照以下步骤创建并运行试验:
登录 Azure 机器学习工作室,并选择你的订阅和工作区。
在左侧菜单的创作部分下,选择自动化 ML:
首次在工作室中使用试验时,你会看到一个空列表和指向文档的链接。 如果不是,你会看到最近的自动化 ML 试验列表,包括使用 Azure 机器学习 SDK 创建的项。
选择“新建自动化 ML 作业”以启动“提交自动化 ML 作业”过程。
默认情况下,该过程会在“训练方法”选项卡上选择“自动训练”选项,并继续执行配置设置。
在“基本信息设置”选项卡上,输入所需设置的值,包括“作业”名称和“试验”名称。 还可根据需要为可选设置提供值。
选择“下一步”继续操作。

确定数据资产
在“任务类型和数据”选项卡上,指定试验的数据资产和用于训练数据的机器学习模型。
在本文中,可以使用现有数据资产,或者从本地计算机上的文件创建新的数据资产。 工作室 UI 页面会根据所选的数据源和训练模型类型而变化。
如果选择使用现有数据资产,可继续转到“配置训练模型”部分。
若要创建新的数据资产,请执行以下步骤:
若要从本地计算机上的某个文件创建新的数据资产,请选择“创建”。
在“数据类型”页上:
- 输入“数据资产”名称。
- 对于“类型”,请从下拉列表中选择“表格”。
- 选择下一步。
在“数据源”页上,选择“从本地文件”。
机器学习工作室向左侧菜单添加了额外的选项,供你配置数据源。
选择“下一步”以继续转到“目标存储类型”页,在其中指定 Azure 存储位置以上传数据资产。
可指定使用工作区自动创建的默认存储容器,或选择用于试验的存储容器。
- 对于“数据存储类型”,请选择“Azure Blob 存储”。
- 在数据存储列表中,选择”workspaceblobstore”。
- 选择下一步。
在“文件和文件夹选择”页上,使用“上传文件或文件夹”下拉菜单,然后选择“上传文件”或“上传文件夹”选项。
- 浏览到要上传的数据的位置,然后选择“打开”。
- 上传文件后,选择“下一步”。
机器学习工作室会验证数据并上传数据。
注意
如果数据位于虚拟网络后面,则需要启用“跳过验证”功能以确保工作区可以访问数据。 有关详细信息,请参阅在 Azure 虚拟网络中使用 Azure 机器学习工作室。
在 “设置” 页上,检查上传的数据的准确性。 页面上的字段根据数据的文件类型进行预填充:
字段 说明 文件格式 定义文件中存储的数据的布局和类型。 分隔符 确定一个或多个字符,用于指定纯文本或其他数据流中不同的独立区域之间的边界。 编码 指定字符架构表中用于读取数据集的位。 列标题 指示如何处理数据集的标头(如果有)。 跳过行 指示要跳过数据集中的多少行(如果有)。 选择“下一步”以继续转到“架构”页。 此页也根据“设置”选择进行预填充。 可为每个列配置数据类型、审查列名并管理列:
- 若要更改列的数据类型,请使用“类型”下拉菜单以选择一个选项。
- 若要从数据资产中排除某列,请切换该列的“包括”选项。
选择“下一步”以继续转到“审查”页。 查看作业的配置设置摘要,然后选择“ 创建”。
配置训练模型
数据资产准备就绪后,机器学习工作室将返回到“提交自动化 ML 作业”过程的“任务类型”和“数据”选项卡。 新数据资产列于页面上。
按照以下步骤完成作业配置:
展开“选择任务类型”下拉菜单,然后选择用于试验的训练模型。 这些选项包括分类、回归、时序预测、自然语言处理 (NLP) 或计算机视觉。 有关这些选项的详细信息,请参阅支持的任务类型的说明。
指定训练模型后,从列表中选择数据集。
选择“下一步”以继续转到“任务设置”选项卡。
在“目标列”下拉列表中,选择用于模型预测的列。
根据训练模型,配置以下必需设置:
分类:选择是否启用深度学习。
时序预测:选择是否启用深度学习,并确认必需设置的首选项:
使用 “时间”列 选项指定要在模型中使用的时间数据。
选择是否启用一个或多个“自动检测”选项。 取消选择一个“自动检测”选项(如“自动检测预测范围”)时,可指定一个特定值。 “预测边际”值指示模型可预测未来的时间单位数(分钟/小时/天/周/月/年)。 模型需要预测的未来越远,其准确度就会越低。
有关如何配置这些设置的详细信息,请参阅使用自动化 ML 训练时序预测模型。
自然语言处理:确认所需设置的首选项:
使用“选择子类型”选项,为 NLP 模型配置子分类类型。 可从多类分类、多标签分类和命名实体识别 (NER) 中进行选择。
在“扫描设置”部分中,提供“可宽延时间因数”和“采样算法”的值。
在 “搜索空间 ”部分中,配置 模型算法 选项。
有关如何配置这些设置的详细信息,请参阅设置自动化 ML 以训练 NLP 模型(Azure CLI 或 Python SDK)。
计算机视觉:选择是否启用手动扫描,并确认必需设置的首选项:
- 使用“选择子类型”选项,为计算机视觉模型配置子分类类型。 可从图像分类(多类)或(多标签)、对象检测和多边形(实例分段)中进行选择。
有关如何配置这些设置的详细信息,请参阅设置自动化 ML 以训练计算机视觉模型(Azure CLI 或 Python SDK)。
指定可选设置
机器学习工作室提供可根据机器学习模型选择配置的可选设置。 以下各部分介绍额外的设置。
配置其他设置
可选择“查看其他配置设置”选项,以查看在准备进行训练时对数据执行的操作。
“其他配置”页根据试验选择和数据显示默认值。 可使用默认值或配置以下设置:
| 设置 | 说明 |
|---|---|
| 主要指标 | 确定用于对模型进行评分的主要指标。 有关详细信息,请参阅模型指标。 |
| 启用集成堆栈 | 通过组合多个模型而不是使用单个模型,允许集成学习并改进机器学习结果和预测性能。 有关详细信息,请参阅集成模型。 |
| 使用所有受支持的模型 | 使用此选项,指示自动化 ML 是否使用试验中所有受支持的模型。 有关详细信息,请参阅每种任务类型支持的算法。 - 选择此选项以配置“阻止的模型”设置。 - 取消选中此选项以配置“允许的模型”设置。 |
| 阻止的模型 | (选择“使用所有受支持的模型”时可用)使用下拉列表并选择从训练作业中排除的模型。 |
| 允许的模型 | (未选择“使用所有受支持的模型”时可用)使用下拉列表并选择用于训练作业的模型。 重要事项:仅适用于 SDK 试验。 |
| 解释最佳模型 | 选择此选项以自动显示有关自动化 ML 创建的最佳模型的可解释性。 |
| 正类标签 | 输入用于计算二进制指标的自动化 ML 标签。 |
配置特征化设置
可选择“查看特征化设置”选项,以查看在准备进行训练时对数据执行的操作。
“特征化”页显示数据列的默认特征化技术。 可启用/禁用自动特征化,并为试验自定义自动特征化设置。

选择“启用特征化”选项以允许配置。
重要
当数据包含非数值列时,始终启用特征化。
根据需要配置每个可用列。 下表汇总了工作室中目前可用的自定义。
列 自定义 特征类型 更改选定列的值类型。 插补值 选择数据中用于插补缺失值的值。 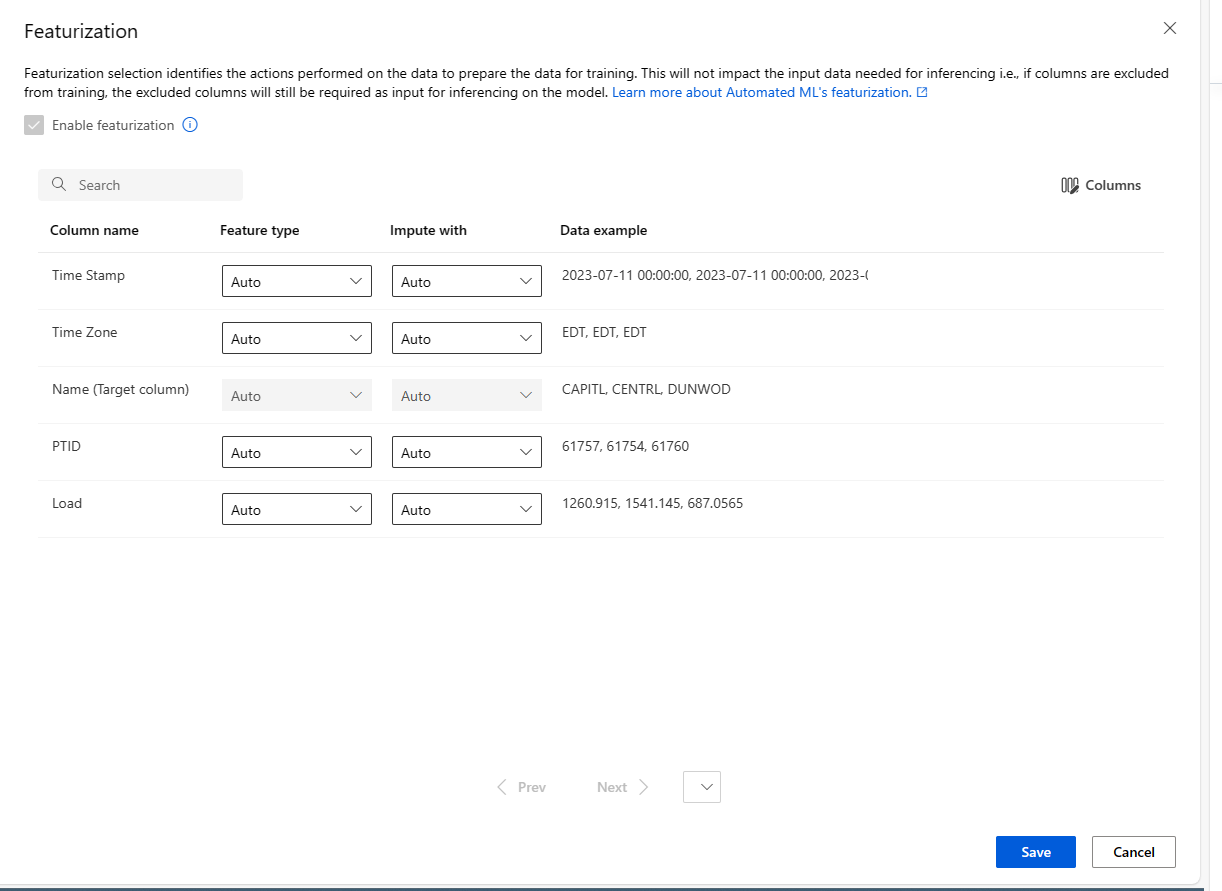

特征化设置不影响推理所需的输入数据。 如果从训练中排除列,则仍需要排除的列作为对模型进行推理的输入。
为作业配置限制
“ 限制 ”部分提供以下设置的配置选项:
| 设置 | 说明 | 值 |
|---|---|---|
| 试用版最大值 | 指定在自动化 ML 作业期间尝试的最大试运行数,其中每个试运行都有不同的算法和超参数组合。 | 介于 1 和 1,000 之间的整数 |
| 试用版最大并发数 | 指定可并行执行的试运行作业的最大数目。 | 介于 1 和 1,000 之间的整数 |
| 最大节点数 | 指定此作业可从所选计算目标使用的最大节点数。 | 1 个或多个,具体取决于计算配置 |
| 指标分数阈值 | 输入迭代指标阈值。 当迭代达到阈值时,训练作业终止。 请记住,有意义的模型的相关性大于零。 否则,结果与猜测值相同。 | 平均指标阈值,介于界限 [0, 10] 之间 |
| 试验超时(分钟) | 指定整个试验可运行的最大时间。 试验达到限制后,系统将取消自动化 ML 作业,包括所有试验(子作业)。 | 分钟数 |
| 迭代超时(分钟) | 指定每个试运行作业可运行的最大时间。 试用作业达到此限制后,系统将取消它。 | 分钟数 |
| 启用提前终止 | 分数在短期内没有提高时,使用此选项结束作业。 | 选择该选项,使作业提前结束 |
验证并测试
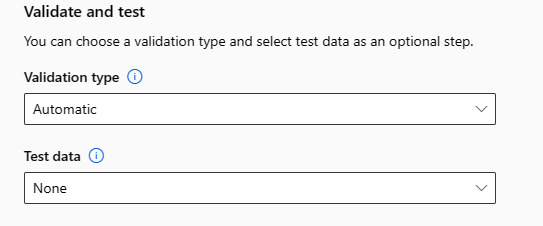
“验证和测试”部分提供以下配置选项:
指定用于训练作业的“验证类型”。 如果未显式指定
validation_data或n_cross_validations参数,则自动化 ML 会根据单个数据集training_data中的行数应用默认技术。训练数据大小 验证技术 大于 20,000 行 将应用训练/验证数据拆分。 默认行为是将初始训练数据集的 10% 用作验证集。 然后,该验证集将用于指标计算。 小于 20,000& 行 将应用交叉验证方法。 默认折数取决于行数。
- 少于 1,000 行的数据集:使用 10 折
- 包含 1,000 到 20,000 行的数据集:使用 3 折提供测试数据(预览)以评估自动化 ML 在试验结束时生成的推荐模型。 提供测试数据集时,会在试验结束时自动触发测试作业。 此测试作业是自动化 ML 推荐的最佳模型的唯一作业。
重要
提供测试数据集来评估生成的模型是一项预览功能。 此功能是一个试验性预览功能,可能会随时更改。
测试数据被视为独立于训练和验证,且不应对推荐模型的测试作业结果产生偏差。 有关详细信息,请参阅训练、验证和测试数据。
可以提供自己的测试数据集,也可以使用训练数据集的百分比。 测试数据必须采用 Azure 机器学习表数据集的形式。
测试数据集的架构应与训练数据集相匹配。 目标列是可选的,但如果未指示任何目标列,则不会计算测试指标。
测试数据集不应与训练数据集或验证数据集相同。
预测作业不支持训练/测试拆分。
配置计算
按照以下步骤配置计算:
选择“下一步”以继续转到“计算”选项卡。
使用 “选择计算类型 ”下拉列表选择用于数据分析和训练作业的选项。
选择计算类型后,页面上的其他 UI 会根据所选内容而变化:
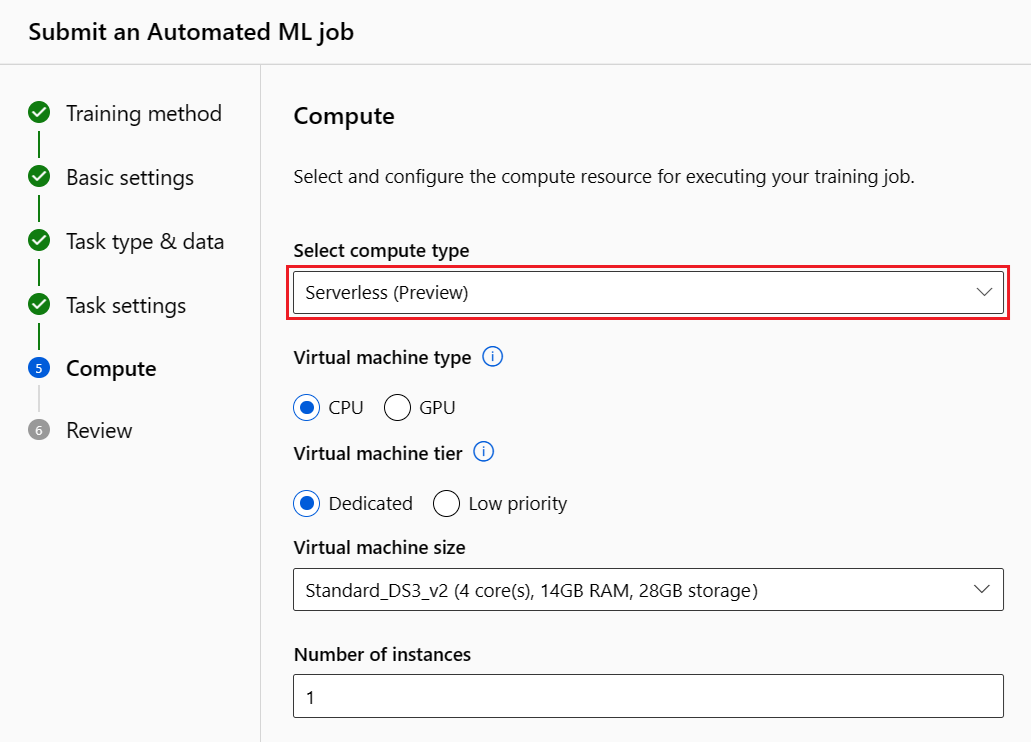
无服务器:配置设置显示在当前页上。 继续转到下一步,了解要配置的设置的说明。
计算群集 或 计算实例:从以下选项中进行选择:
- 使用 “选择自动 ML 计算 ”下拉列表选择工作区的现有计算,然后选择“ 下一步”。
- 选择“新建”以创建新的计算实例或群集。 此选项会打开“创建计算”页。 继续转到下一步,了解要配置的设置的说明。
对于无服务器计算或新的计算,配置任何必需的 (*) 设置:
配置设置因计算类型而异。 下表总结了你可能需要配置的各种设置:
字段 说明 计算名称 输入用于标识计算上下文的唯一名称。 位置 指定计算机的区域。 虚拟机优先级 低优先级虚拟机的费用更低,但不能保证计算节点。 虚拟机类型 选择“CPU”或“GPU”作为虚拟机类型。 虚拟机层 选择试验的优先级。 虚拟机大小 指定计算资源的虚拟机大小。 最小/最大节点数 要分析数据,必须指定一个或多个节点。 输入计算的最大节点数。 对于 Azure 机器学习计算,默认值为 6 个节点。 缩减前的空闲秒数 指定群集自动缩减到最小节点数之前的空闲时间。 高级设置 使用这些设置可以配置用户帐户和现有虚拟网络以进行试验。 配置必需设置后,根据需要选择“下一步”或“创建”。
创建新计算可能需要花费几分钟时间。 创建完成后,选择“下一步”。
运行试验并查看结果
选择“完成”来运行试验。 试验准备过程可能需要长达 10 分钟的时间。 训练作业可能需要额外的 2-3 分钟才能使每个管道完成运行。 如果指定为最佳推荐模型生成 RAI 仪表板,最长可能需要 40 分钟。
注意
自动化 ML 使用的算法本身具有随机性,这可能会导致建议的模型最终指标分数(如准确度)出现细微差异。 自动化机器学习还可以根据需要对数据执行诸如训练集-测试集划分、训练集-验证集划分或交叉验证等操作。 如果多次运行具有相同配置设置和主要指标的试验,则由于这些因素,每个试验的最终指标分数可能会有所不同。
查看试验详细信息
“ 作业详细信息 ”屏幕将打开“ 详细信息 ”选项卡。此屏幕显示试验作业的摘要,包括作业编号旁边的顶部的状态栏。
“模型”选项卡包含按指标评分排序的已创建模型列表。 默认情况下,列表中首先显示评分最高的模型(评分根据所选指标给出)。 随着训练作业尝试更多模型,练习的模型会添加到列表中。 使用此方法快速比较生成的模型的指标。
查看训练作业详细信息
深入了解任何已完成的模型,以获取训练作业详细信息。 可以在“ 指标 ”选项卡中查看特定模型的性能指标图表。有关详细信息,请参阅 评估自动化机器学习试验结果。 在此页上,还可以找到有关模型的所有属性的详细信息,以及关联的代码、子作业和图像。
查看远程测试作业结果(预览)
如果于试验设置期间在“验证和测试”窗体上指定了测试数据集或选择了训练/测试拆分,则默认情况下自动化 ML 会自动测试建议的模型。 因此,自动化 ML 会计算测试指标以确定建议模型及其预测的质量。
按照以下步骤查看推荐模型的测试作业指标:
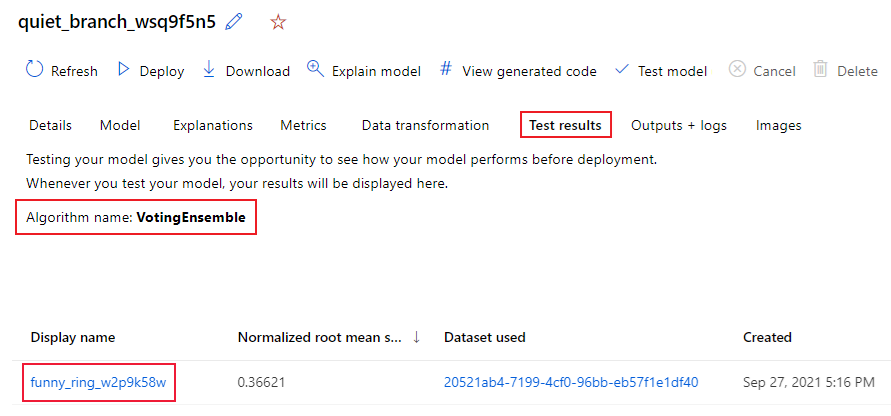
在工作室中,浏览到“ 模型 ”页并选择最佳模型。
选择“测试结果(预览)”选项卡。
选择所需的作业,然后查看“指标”选项卡:
按照以下步骤查看用于计算测试指标的测试预测:
在页面底部,选择“输出数据集”下的链接以打开数据集。
在“数据集”页上,选择“浏览”选项卡以查看测试作业的预测。
还可以从“ 输出 + 日志 ”选项卡查看和下载预测文件。展开 “预测 ”文件夹以找到 predictions.csv 文件。
模型测试作业将生成 predictions.csv 文件,该文件存储在与工作区一起创建的默认数据存储中。 此数据存储对使用同一订阅的所有用户可见。 如果用于测试作业或由测试作业创建的任何信息需要保持专用状态,则不建议将测试作业用于此方案。
测试现有的自动化 ML 模型(预览)
试验完成后,可测试自动化 ML 生成的模型。
若要测试其他自动生成的模型,而不是建议的模型,请执行以下步骤:
选择现有的自动化 ML 试验作业。
浏览到作业的“模型”选项卡,选择要测试的已完成模型。
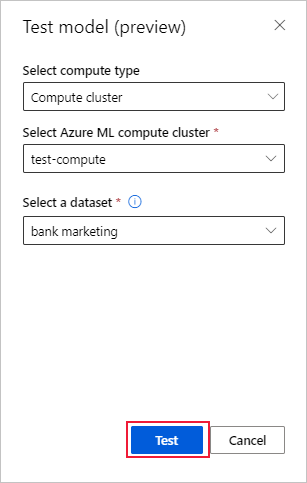
在“模型 详细信息 ”页上,选择 “测试模型”(预览), 打开 “测试模型 ”窗格。
在 “测试模型 ”窗格中,选择要用于测试作业的计算群集和测试数据集。
选择“测试”选项。 测试数据集的架构应与训练数据集相匹配,但目标列是可选的。
成功创建模型测试作业后,“ 详细信息 ”页会显示一条成功消息。 选择“测试结果”选项卡以查看作业进度。
若要查看测试作业的结果,请打开“详细信息”页,并按照“查看远程测试作业结果(预览)”部分中的步骤进行操作。
负责任 AI 仪表板(预览)
若要更好地了解模型,可以使用“负责任的 AI”仪表板查看有关它的各种见解。 通过此 UI,可以评估和调试最佳自动化 ML 模型。 负责任 AI 仪表板评估模型错误和公平性问题,通过评估训练和/或测试数据以及观察模型解释来诊断发生这些错误的原因。 这些见解有助于您与模型建立信任并通过审核流程。 无法为现有的自动化 ML 模型生成负责任 AI 仪表板。 只有在创建新的自动化 ML 作业时,才会为最佳推荐模型创建仪表板。 在为现有模型提供支持之前,用户应继续使用模型说明(预览版)。
若要为特定模型生成负责任的 AI 仪表板,请执行以下步骤:
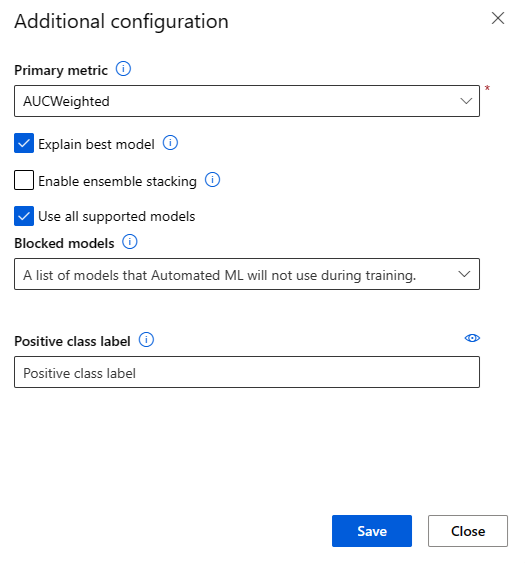
提交自动化 ML 作业时,请转到左侧菜单上的 “任务设置 ”部分,然后选择“ 查看其他配置设置”。
在“其他配置”页上,选择“解释最佳模型”选项:
切换到 “计算 ”选项卡并选择“ 无服务器 ”进行计算:
该操作完成后,浏览到自动化 ML 作业的“模型”页,其中包含已训练模型的列表。
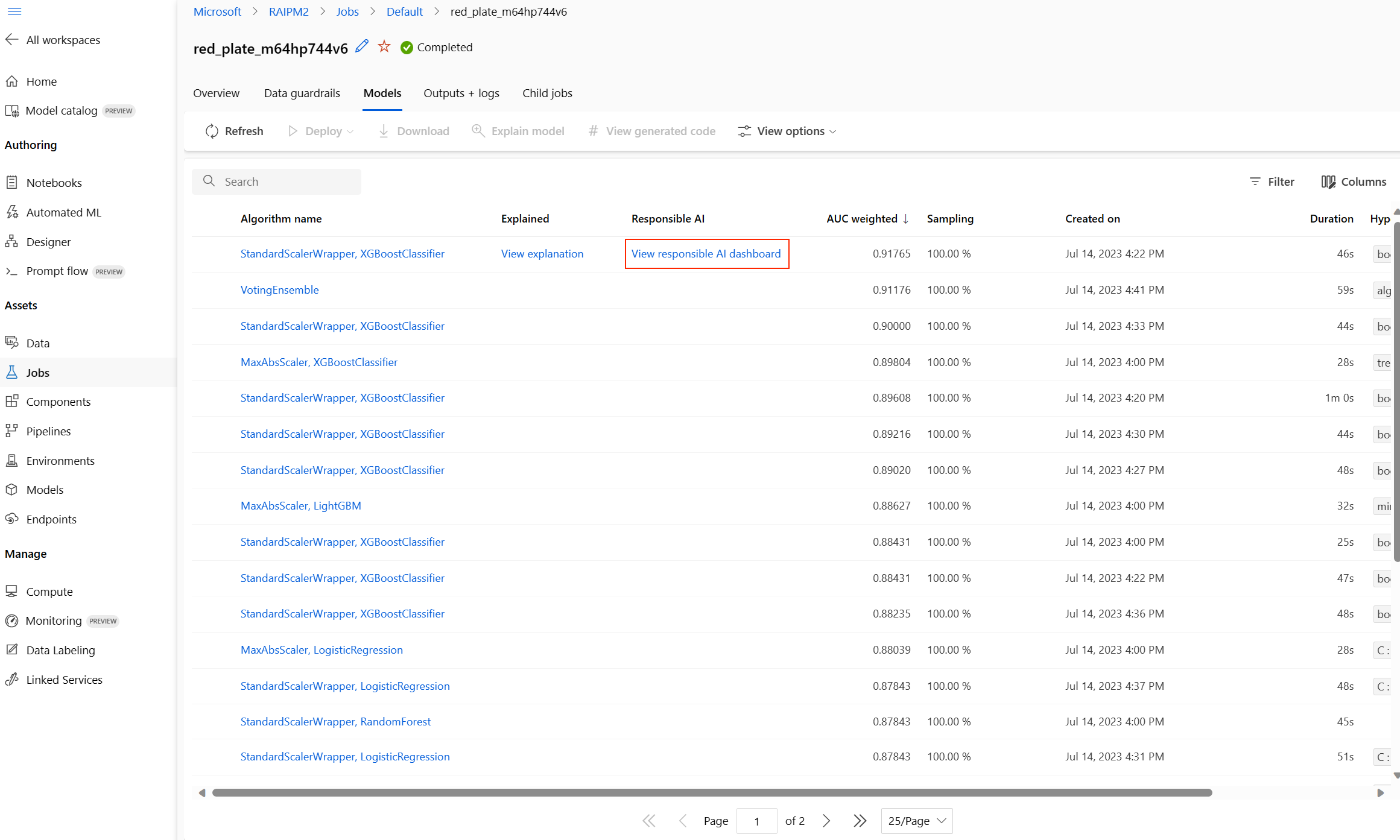
随即显示所选模型的负责任 AI 仪表板:
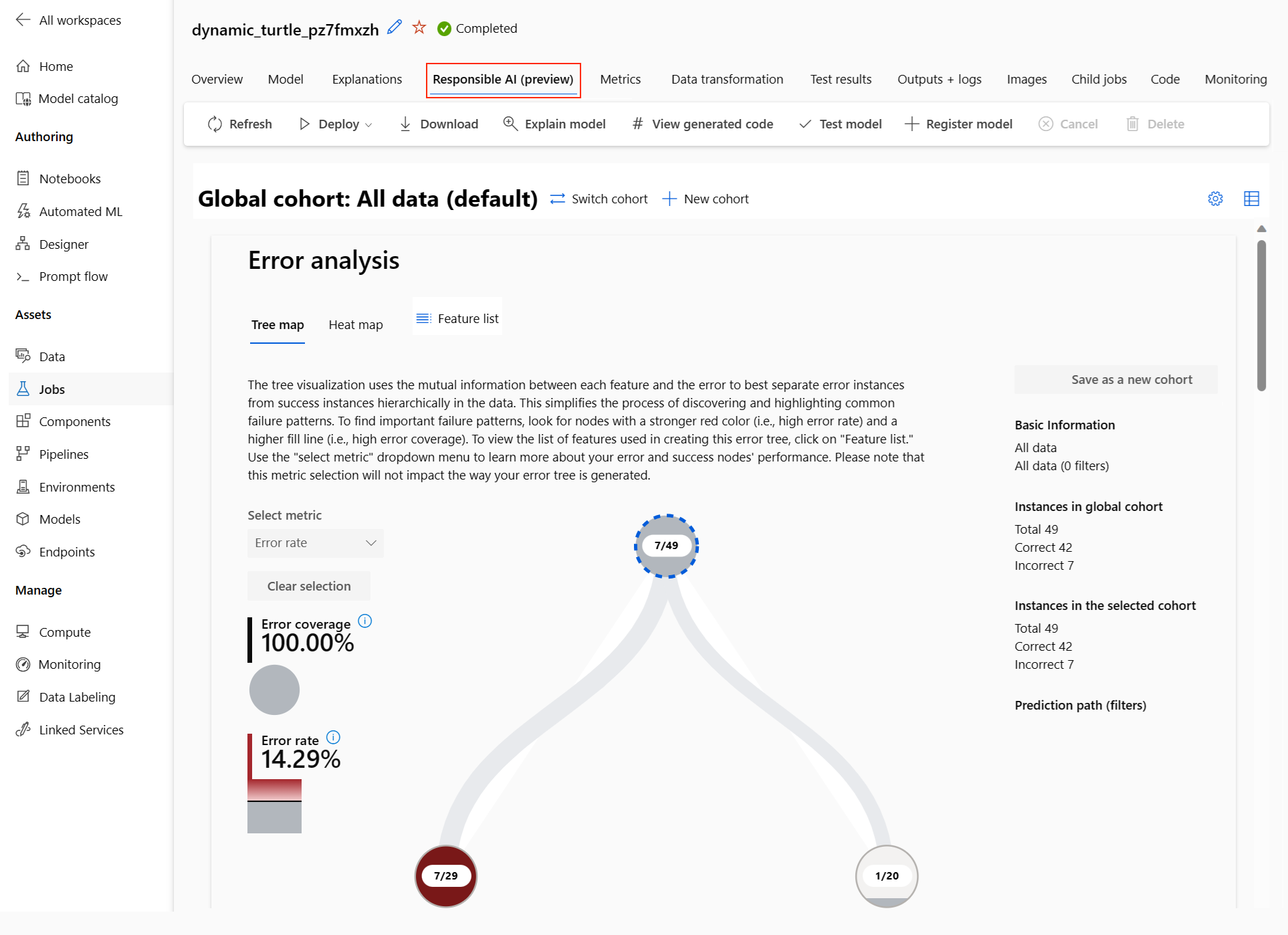
在仪表板中,可看到四个已为自动化 ML 最佳模型激活的组件:
组件 组件显示了什么内容? 如何阅读图表? 错误分析 以下情况下需要使用错误分析:
- 深入了解模型故障在数据集以及多个输入和特征维度中的分布方式。
- 细分聚合性能指标,自动发现错误的队列,以指导你采取针对性的缓解步骤。错误分析图表 模型概述和公平性 使用此组件执行以下操作:
- 深入了解模型在不同数据队列中的性能。
- 通过查看差异指标了解模型公平性问题。 这些指标可以评估和比较根据敏感(或非敏感)特征标识的子组的模型行为。模型概述和公平性图表 模型解释 通过查看以下内容,使用模型说明组件针对机器学习模型的预测结果生成人类可理解的说明:
- 全局解释:例如,哪些特征会影响贷款分配模型的整体行为?
- 局部解释:例如,为何批准或拒绝了客户的贷款申请?模型可解释性图表 数据分析 在以下情况下需要使用数据分析:
- 选择不同的筛选器将数据切片为不同的维度(也称为队列)以浏览数据集统计信息。
- 了解数据集在不同队列和功能组中的分布。
- 确定与公平性、错误分析和因果关系(来自其他仪表板组件)相关的发现是否是数据集分布的结果。
- 确定在哪些领域收集更多数据,以减少由表示问题、标签噪声、特征噪声、标签偏差以及类似因素引起的错误。数据资源管理器图表 可以创建队列(共享指定特征的数据点的子组),以便将每个组件的分析集中在不同的队列上。 当前应用于仪表板的队列的名称始终显示在仪表板的左上角。 仪表板中的默认视图是整个数据集,其标题默认为“所有数据”。 有关详细信息,请参阅仪表板的全局控件。


编辑并提交作业(预览)
如果要基于现有试验的设置创建新试验,自动化 ML 会在工作室 UI 中提供 “编辑和提交 ”选项。
重要
基于现有实验复制、编辑和提交新实验的功能是一项预览功能。 此功能是一个试验性预览功能,可能会随时更改。
“编辑和提交”选项会打开“创建新的自动化 ML 作业”向导,其中已预先填充了数据、计算和试验设置。 可配置向导中每个选项卡上的选项,并根据需要编辑新试验的选择。 此功能仅限于从工作室 UI 启动的试验,并且需要新实验的数据架构才能与原始试验的架构匹配。
部署模型
获得最佳模型后,可以将其部署为 Web 服务来预测新数据。
自动化 ML 有助于部署模型,而无需编写任何代码。
使用以下方法之一启动部署:
使用定义的指标条件部署最佳模型:
试验完成后,选择“作业 1”并浏览到“父作业”页。
选择“ 最佳模型摘要 ”部分中列出的模型,然后选择“ 部署”。
从此试验部署特定模型迭代:
- 从“ 模型 ”选项卡中选择所需的模型,然后选择“ 部署”。
填充“部署模型”窗格:
字段 值 Name 输入部署的唯一名称。 描述 输入说明,以更好地确定部署目的。 计算类型 选择要部署的终结点类型:Azure Kubernetes 服务 (AKS) 或 Azure 容器实例 (ACI) 。 计算名称 (仅适用于 AKS)选择要部署到的 AKS 群集的名称。 启用身份验证 选择此项将允许基于令牌或基于密钥的身份验证。 使用自定义部署资产 如果想上传自己的评分脚本和环境文件,请启用自定义资产。 否则,默认情况下,自动化 ML 会为你提供这些资产。 有关详细信息,请参阅使用在线终结点部署机器学习模型并为其评分。 重要
文件名称必须介于 1 到 32 个字符之间。 名称必须以字母数字开头和结尾,并且可以在两者之间包括短划线、下划线、点和字母数字。
“高级”菜单提供默认部署功能,例如数据收集和资源利用率设置。 可使用此菜单中的选项替代这些默认值。 有关详细信息,请参阅监视联机终结点。
选择“部署”。 完成部署可能需要大约 20 分钟。
部署启动后,“模型摘要”选项卡随即打开。 可在“部署状态”部分下监视部署进度。
现在,你已获得一个正常运行的、可以生成预测结果的 Web 服务! 可通过从 Microsoft Fabric 中的端到端 AI 示例查询服务来测试预测。