Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure Database for PostgreSQL 中的业务连续性是指使企业能够面对中断(尤其是计算基础结构)继续运营的机制、策略和过程。 在大多数情况下,Azure Database for PostgreSQL处理云环境中可能发生的中断事件,并使应用程序和业务流程保持运行。 但是,某些事件无法自动处理,例如:
- 用户意外删除或更新表中的行。
- 地震导致停电,暂时禁用可用性区域或区域。
- 修复 bug 或安全问题所需的数据库修补。
Azure Database for PostgreSQL提供了在计划内和计划外停机事件期间保护数据和缓解任务关键型数据库的停机时间的功能。 Azure Database for PostgreSQL 基于提供可靠复原和可用性的 Azure 基础结构构建,提供另一种故障保护、解决恢复时间要求并减少数据丢失暴露的业务连续性功能。 在构建应用程序时,请考虑故障时间容忍度(恢复时间目标(RTO)和数据丢失暴露-恢复点目标(RPO)。 例如,与测试数据库相比,业务关键数据库具有更严格的正常运行时间要求。
下表说明了Azure Database for PostgreSQL产品/服务的功能。
| 功能 | 说明 | 考虑 |
|---|---|---|
| 自动备份 | Azure Database for PostgreSQL 灵活服务器实例会自动执行数据库文件的每日备份,并持续备份事务日志。 可将备份从 7 天保留到 35 天。 可以将数据库服务器还原到备份保留期内的任何时间点。 RTO 取决于要还原的数据大小以及执行日志恢复的时间。 它可以从几分钟到 12 小时。 有关详细信息,请参阅 概念 - 备份和还原。 | 备份数据保留在该区域中。 |
| 区域冗余高可用性 | 可以使用区域冗余高可用性(HA)配置部署Azure Database for PostgreSQL灵活服务器实例,其中主服务器和备用服务器部署在区域中的两个不同的可用性区域中。 此 HA 配置可保护数据库免受区域级故障的影响,还有助于在计划内和计划外停机事件期间减少应用程序停机时间。 在同步模式下,主服务器中的数据将复制到备用副本。 如果主服务器发生任何中断,服务器将自动故障转移到备用副本。 在大多数情况下,RTO 预计将低于 120 秒。 RPO 应为零(无数据丢失)。 有关详细信息,请参阅 概念 - 高可用性。 | 在常规用途和内存优化计算层中受支持。 仅可在提供多个区域的区域中使用。 |
| 同一区域高可用性 | 可以使用同一区域高可用性(HA)配置部署Azure Database for PostgreSQL灵活服务器实例,其中主服务器和备用服务器部署在区域中的同一可用性区域中。 此 HA 配置可保护数据库免受节点级故障的影响,还有助于在计划内和计划外停机事件期间减少应用程序停机时间。 在同步模式下,主服务器中的数据将复制到备用副本。 如果主服务器发生任何中断,服务器将自动故障转移到备用副本。 在大多数情况下,RTO 预计将低于 120 秒。 RPO 应为零(无数据丢失)。 有关详细信息,请参阅 概念 - 高可用性。 | 在常规用途和内存优化计算层中受支持。 |
| 高级托管磁盘 | 数据库文件存储在高度持久且可靠的高级托管存储中。 此存储通过在一个可用区内存储三个副本来提供数据冗余,并具备自动数据恢复能力。 有关详细信息,请参阅 托管磁盘文档。 | 存储在可用性区域中的数据。 |
| 区域冗余备份 | 如果区域支持可用性区域,Azure Database for PostgreSQL 灵活服务器实例备份会自动安全地存储在区域中的区域冗余存储中。 在预配服务器的区域级别故障期间,如果服务器未配置区域冗余,则仍可以使用不同区域中的最新还原点还原数据库。 有关详细信息,请参阅 概念 - 备份和还原。 | 只有在有多个区域可用的区域中才适用。 |
| 异地冗余备份 | Azure Database for PostgreSQL 灵活服务器实例备份将复制到远程区域。 此功能有助于在主服务器区域关闭时出现灾难恢复情况。 | 此功能目前在选定区域已启用。 根据要还原的数据大小和要执行的恢复量,它需要更长的 RTO 和更高的 RPO。 |
| 只读副本 | 可以部署跨区域只读副本,以保护数据库免受区域级故障的影响。 只读副本是使用 PostgreSQL 的物理复制技术异步更新的,并且可能会滞后主要副本。 有关详细信息,请参阅概念 - 只读副本。 | 在常规用途和内存优化计算层中受支持。 |
下表比较了典型工作负荷方案中的 RTO 和 RPO:
| 能力 | 可突发 | 产品 SKU (通用型/内存优化型) |
|---|---|---|
| 从备份执行时间点还原 | 保留期内的任何还原点 RTO - 可变 RPO < 5 分钟 |
保留期内的任何还原点 RTO - 可变 RPO < 5 分钟 |
| 从异地复制的备份执行异地还原 | RTO - 可变 RPO < 1 小时 |
RTO - 可变 RPO < 1 小时 |
| 只读副本 | 不適用 | RTO - 几分钟* RPO - 通常范围为 30 秒到 5 分钟* |
| 高可用性 | 不適用 | RTO < 120 秒 RPO = 0 |
计划内故障事件
下表介绍了一些常见的计划内维护方案。 这些事件通常会导致几分钟的停机时间,但它们不会导致数据丢失。
| 情景 | 过程 |
|---|---|
| 计算缩放(由用户发起) | 在计算缩放操作期间,该过程允许活动检查点完成、清空客户端连接、取消任何未提交的事务、分离存储,然后关闭。 该过程会预配一个新的 Azure Database for PostgreSQL 灵活服务器实例,并沿用相同的数据库服务器名称,但采用扩展后的计算配置。 该过程将存储附加到新服务器,并启动数据库,在接受客户端连接之前,该数据库会在必要时执行恢复。 |
| 扩展存储(由用户启动) | 启动纵向扩展存储操作时,该过程允许活动检查点完成、清空客户端连接并取消任何未提交的事务。 之后,进程将关闭服务器。 进程将存储缩放为所需的大小,然后将其附加到新服务器。 在接受客户端连接之前,此过程会根据需要执行恢复。 请注意,不支持对存储大小进行缩减。 |
| 新软件部署(由 Azure 启动) | 该服务会在计划内维护过程中自动推出新功能或 bug 修复。 可以计划这些活动何时发生。 有关详细信息,请查看 门户。 |
| 次要版本升级(由 Azure 启动) | Azure Database for PostgreSQL 会自动将数据库服务器修补到 Azure 确定的次要版本。 此修补作为服务计划内维护的一部分进行。 此过程会自动使用新的次要版本重启数据库服务器。 有关详细信息,请参阅 文档。 你还可以查看你的门户。 |
配置具有高可用性的Azure Database for PostgreSQL灵活服务器实例时,该服务首先对备用服务器执行缩放和维护操作。 有关详细信息,请参阅 概念 - 高可用性。
缓解计划外停机
意外中断(如基础硬件故障、网络问题和软件 bug)可能会导致计划外停机。 如果配置了高可用性的数据库服务器意外关闭,服务将激活备用副本,客户端可以恢复其操作。 如果未配置具有高可用性的服务器(HA),服务会在重启尝试失败时自动预配新的数据库服务器。 虽然无法避免计划外停机,但Azure Database for PostgreSQL无需人工干预即可自动执行恢复操作来帮助缓解停机时间。
尽管工程团队不断努力提供高可用性,但有时Azure Database for PostgreSQL确实会导致数据库不可用,从而影响应用程序。 当服务监视检测到导致普遍连接错误、故障或性能问题的问题时,该服务会自动声明中断以保持通知。
服务中断
如果Azure Database for PostgreSQL灵活服务器实例出现故障,可以在以下位置找到有关中断的更多详细信息:
- Azure门户横幅:如果订阅受到影响,Azure门户通知会显示服务问题的中断警报。
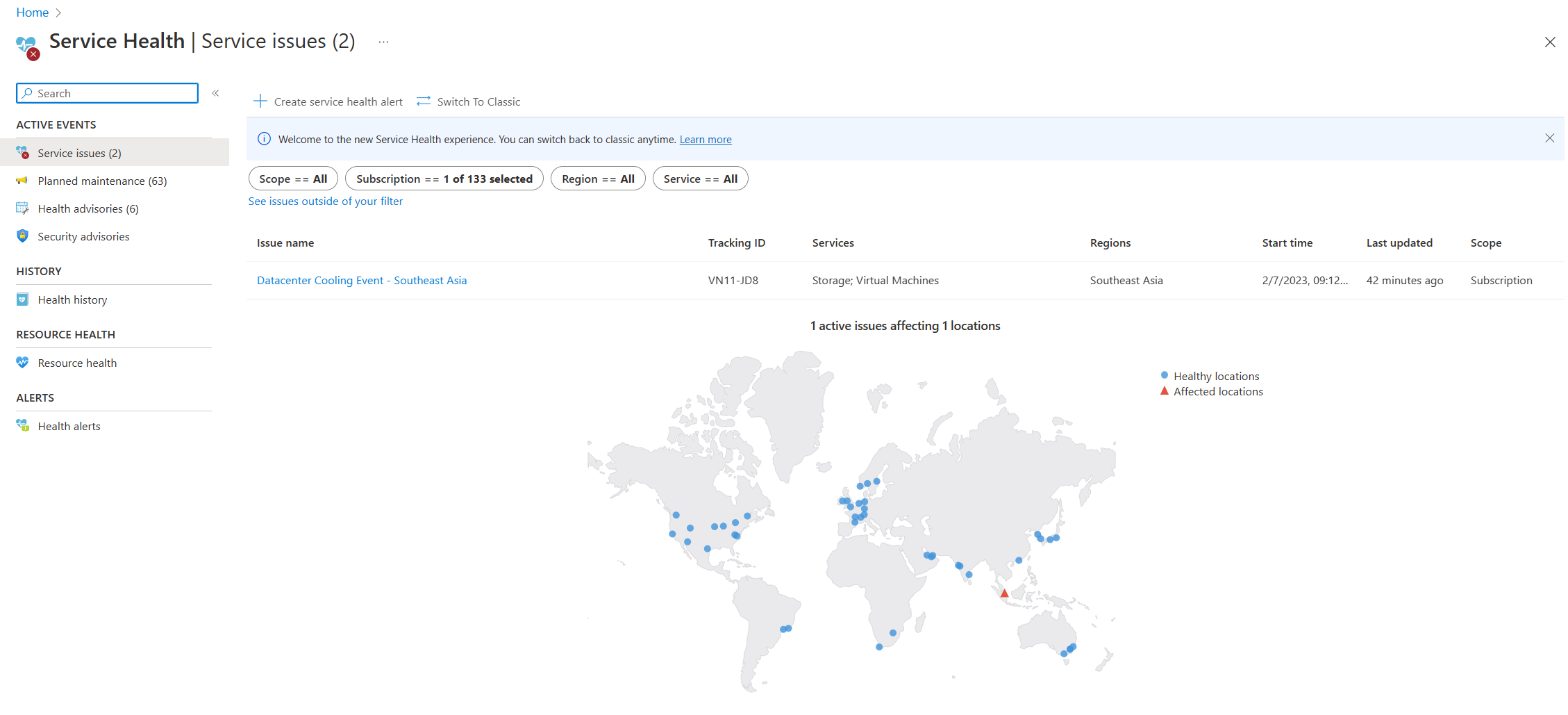
- 服务运行状况:Azure门户中的服务运行状况页包含全局Azure数据中心状态的相关信息。 在Azure门户中的搜索栏中搜索“服务运行状况”,然后在“活动事件”类别中查看服务问题。 还可以在帮助菜单下任何资源的资源运行状况页中查看单个资源的运行状况。 下面显示了“服务运行状况”页的示例屏幕截图。
- 电子邮件通知:如果设置了警报,则服务中断影响订阅和资源时会收到电子邮件通知。 邮件来自 "azure-noreply@microsoft.com"。 电子邮件正文以“活动日志警报...由 Azure 订阅的服务问题触发...”开头。 有关服务运行状况警报的详细信息,请参阅使用 Azure 门户在Azure服务通知上接收活动日志警报。
重要
顾名思义,PostgreSQL 中的临时表空间用于临时对象以及其他内部数据库操作,例如排序。 因此,请勿在临时表空间中创建用户架构对象,因为服务器重启后这些对象的持久性、HA 故障转移和类似的事件不能保证。
计划外停机:故障场景和服务恢复
下表介绍了常见的计划外故障方案和恢复过程。
| 情景 |
恢复过程 [未配置区域冗余 HA 的服务器] |
恢复过程 [配置了区域冗余 HA 的服务器] |
|---|---|---|
| 数据库服务器故障 | 如果数据库服务器出现故障,Azure尝试重启数据库服务器。 如果尝试失败,Azure在另一个物理节点上重新启动数据库服务器。 恢复时间(RTO)取决于各种因素,包括故障时的活动,例如大型事务,以及在数据库服务器启动过程中要执行的恢复量。 使用 PostgreSQL 数据库的应用程序需要检测并重试已删除的连接和失败的事务。 |
如果检测到数据库服务器发生故障,服务器将切换到备用服务器,从而减少停机时间。 有关详细信息,请参阅 HA 概念页。 RTO 预计为 60-120 秒,不会丢失任何数据。 |
| 存储失败 | 应用程序不会看到任何与存储相关的问题(例如磁盘故障或物理块损坏)产生的任何影响。 由于数据保存为三个副本,因此剩余的存储副本中仍保存着该数据的副本。 损坏的数据块会自动修复,数据的新副本会自动创建。 | 发生任何罕见且无法恢复的错误时,例如整个存储都无法访问,Azure Database for PostgreSQL 灵活服务器实例会故障转移到备用副本,以减少停机时间。 有关详细信息,请参阅 HA 概念页。 |
| 逻辑或用户错误 | 若要从用户错误中恢复(例如误删表或错误更新数据),请执行时间点恢复(PITR)。 执行还原操作时,请指定自定义还原点,这是错误发生前的时间。 如果只想还原数据库或特定表的子集,而不是数据库服务器中的所有数据库,则可以在新实例中还原数据库服务器,通过 pg_dump导出表,然后使用 pg_restore 将这些表还原到数据库中。 |
这些用户错误不受高可用性保护,因为所有更改都同步复制到备用副本。 需要执行时间点恢复,才能从此类错误中恢复数据。 |
| 可用性区域故障 | 若要从区域级别故障中恢复,请使用备份执行时间点还原,并选择具有最新时间的自定义还原点以还原最新数据。 在另一个不受影响的区域中部署新的Azure Database for PostgreSQL灵活服务器实例。 还原所需的时间取决于以前的备份和要恢复的事务日志量。 | Azure Database for PostgreSQL 灵活服务器实例会在 60 到 120 秒内自动故障转移到备用服务器,且不会发生数据丢失。 有关详细信息,请参阅 HA 概念页。 |
| 区域故障 | 如果服务器配置了异地冗余备份,可以在配对区域执行异地还原。 Azure 会预配一台新服务器,并将其恢复到已复制到该区域的最新可用数据状态。 还可以使用跨区域只读副本。 发生区域故障时,可以通过将只读副本提升为独立的可读写服务器来执行灾难恢复操作。 除发生严重区域故障的情况外,预计 RPO 最多为 5 分钟(可能会发生数据丢失);而在这种情况下,RPO 可能接近故障发生时的复制延迟。 |
相同的过程。 |
从区域故障恢复后配置数据库
- 如果使用异地还原或异地副本从中断中恢复,请确保正确配置了与新服务器的连接,以便正常应用程序功能可以恢复。 遵循 还原后任务。
- 如果之前在原始服务器上设置了诊断设置,请确保在目标服务器上执行相同的操作(如有必要),如Azure Database for PostgreSQL中的“配置和访问日志”中所述。
- 若要设置遥测警报,请确保将现有警报规则设置更新为映射到新服务器。 有关警报规则的详细信息,请参阅 使用 Azure 门户针对 Azure Database for PostgreSQL 的指标设置警报。
重要
可以还原已删除的服务器。 如果删除服务器,请按照 还原已删除的服务器 中的指南进行恢复。 使用 Azure 资源锁帮助防止意外删除服务器。