Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文面向需要更深入地了解技能集组合的开发人员,并假设熟悉 AI 扩充 的高级概念,或者如何在 Azure AI 搜索中应用 AI 以在编制索引期间转换原始内容。
技能组是 Azure AI 搜索中的可重用对象,附加到索引器。 它包含一个或多个技能,这些技能通过从外部数据源检索的原始内容调用内置 AI 或外部自定义处理。
下图演示了技能组执行的基本数据流。
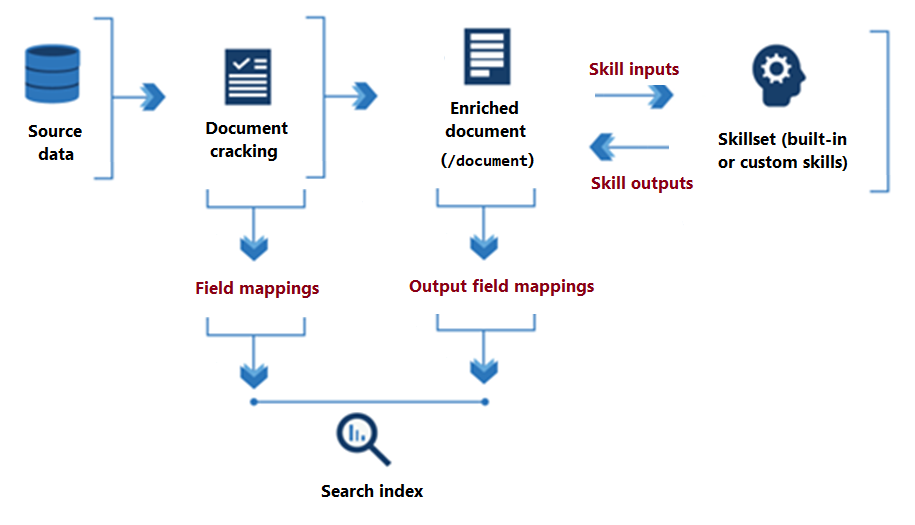
从技能集处理开始到其结论,技能从内存中存在的 *扩充文档树 读取和写入。 最初,增强文档只是从数据源中提取的原始内容(被表达为 "/document" 根节点)。 随着每个技能的执行,扩充的文档会获取结构和实质内容,因为每个技能都将输出写为图形中的节点。
技能集执行完成后,扩充文档的输出将通过用户定义的 输出字段映射路由到索引。 任何需要从源到索引完整传输的原始内容都是通过字段映射来定义的。 相比之下, 输出字段映射会将 内存中内容(节点)传输到索引。
要配置应用 AI,请在技能组和索引器中指定设置。
技能集定义
技能组合是由一个或多个技能组成的集,执行丰富化操作,比如翻译文本或在图像文件上进行光学字符识别 (OCR)。 技能可以是 Microsoft 的内置技能,也可以是用于处理外部托管的逻辑的自定义技能。 技能集生成的丰富文档在编制索引期间使用或被投影到知识存储中。
技能包含上下文、输入和输出:
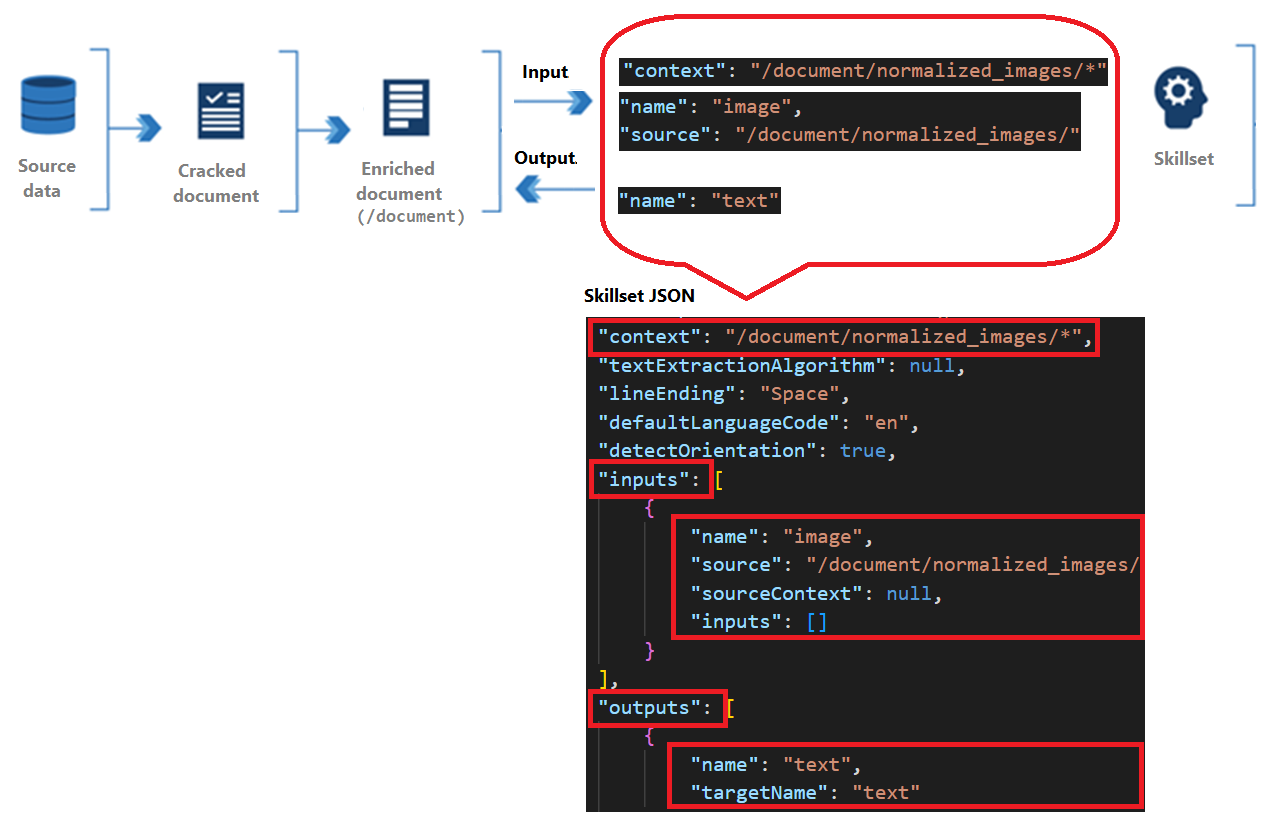
上下文是指操作的范围,可以是对每个文档调用一次,也可以是对集合中每个项调用一次。
输入源自扩充文档中的节点,其中“源”和“名称”标识给定节点。
输出作为新节点返回到增强的文档中。 值是节点“名称”和节点内容。 如果节点名称重复,可设置一个目标名称消除歧义。
技能上下文
每项技能都有上下文,该上下文可以是整个文档 (/document) 或树 (/document/regions/*) 下的节点。
上下文确定:
技能对单个值执行的次数(每个字段、每个文档一次),或针对集合执行的次数,其中添加
/*会导致对集合中的每个实例都调用技能。输出声明,或在扩充树中添加技能输出的位置。 输出始终作为上下文节点的子级添加到树中。
输入的形状。 对于多级集合,将上下文设置为父级集合会影响技能输入的形式。 例如,如果您有一个扩展树,其中包含一个区域列表,每个区域中又有一个州列表,并且每个州列表中有一个 ZIP 代码列表,那么您如何设置上下文将决定输入的解释方式。
上下文 输入 输入的形状 技能调用 /document/regions/*/document/regions/*/states/*/zipcodes/*区域中所有邮政编码的列表 每个区域一次 /document/regions/*/states/*/document/regions/*/states/*/zipcodes/*省/自治区/直辖市中邮政编码的列表 每个区域和州的组合各进行一次
技能依赖项
如果你将一个技能的输出馈送到另一个技能中,技能可以独立并行执行,也可以在依赖关系中按顺序执行。 以下示例演示了两个按顺序执行的内置技能:
技能 #1 是一种文本拆分技能,它接受“reviews_text”源字段的内容作为输入,并将该内容拆分为 5,000 个字符作为输出的“页面”。 将大文本拆分为较小的区块可以为情绪检测等技能生成更好的结果。
技能#2 是情绪检测技能,其功能依赖于拆分技能的输出。 它接受“pages”作为输入,并生成一个名为“Sentiment”的新字段作为包含情绪分析结果的输出。
注意第一个技能的输出(“pages”)是如何用于情绪分析的,其中“/document/reviews_text/pages/*”既是上下文又是输入。 有关路径表述的详细信息,请参阅如何引用扩充。
{
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SentimentSkill",
"name": "#2",
"description": null,
"context": "/document/reviews_text/pages/*",
"defaultLanguageCode": "en",
"inputs": [
{
"name": "text",
"source": "/document/reviews_text/pages/*",
}
],
"outputs": [
{
"name": "sentiment",
"targetName": "sentiment"
},
{
"name": "confidenceScores",
"targetName": "confidenceScores"
},
{
"name": "sentences",
"targetName": "sentences"
}
]
}
. . .
]
}
充实树
扩充文档是在技能组执行过程中创建的临时类树形数据结构,用于收集通过技能引入的所有更改。 总体而言,扩充表示为可寻址节点的层次结构。 节点还包括从外部数据源逐字传递的任何未扩充字段。 检查扩充树的结构和内容的最佳方法是在 Azure 门户中通过 调试会话 。
扩充文档在技能组执行期间存在,但可以将其缓存或发送到知识存储中。
最初,增强文档是指在文档破解期间从数据源中提取的内容,其中文本和图像被提取出来,并可供语言或图像分析使用。
初始内容是元数据和根节点 ()。 根节点通常是整个文档或在文档破解期间从数据源提取的规范化映像。 它在扩充树中的表达方式因数据源类型而异。 下表展示了文档在进入多个受支持数据源的丰富化管道时的状态:
| 数据源\分析模式 | 默认值 | JSON、JSON 行 和 CSV |
|---|---|---|
| Blob 存储 | /document/content /document/normalized_images/* … |
/document/{key1} /document/{key2} … |
| Azure SQL | /document/{column1} /document/{column2} … |
不可用 |
| Azure Cosmos DB | /document/{key1} /document/{key2} … |
不可用 |
随着技能的执行,输出将作为新节点添加到扩充树中。 如果技能运用遍及整个文档,则会在根节点下添加一级节点。
节点可用作下游技能的输入。 例如,创建内容的技能(如翻译后的字符串)可能成为识别实体或提取关键短语的技能的输入。
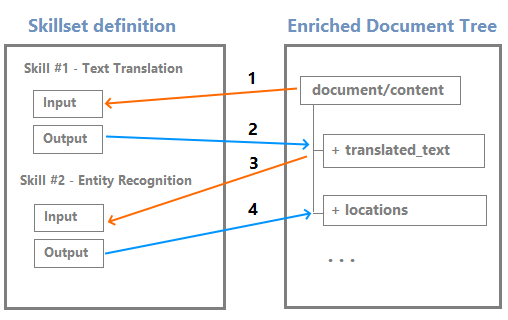
尽管可以通过调试会话可视化编辑器来可视化和使用扩充树,但它主要是一种内部结构。
扩充是不可变的:创建节点后无法对节点进行编辑。 随着技能组合变得越来越复杂,充实树也会更加复杂,但是,充实树中的并非所有节点都需要进入索引或知识存储。
可以有选择地只保留部分扩充输出,以便只保留要使用的内容。 索引器定义中的输出字段映射决定了搜索索引中实际引入的内容。 同样,如果要创建知识存储,可以将输出映射到分配给投影的形状。
注意
富集树格式使富集流水线能够将元数据附加到原始数据类型上。 元数据将不是有效的 JSON 对象,但它可以在知识存储的投影定义中投影为有效的 JSON 格式。 有关详细信息,请参阅Shaper 技能。
索引器定义
索引器具有用于配置索引器执行的属性和参数。 这些属性包括将数据路径映射到搜索索引中字段的映射。

有两组映射:
“fieldMappings”将源字段映射到搜索字段。
“outputFieldMappings”将扩充文档中的节点映射到搜索字段。
“sourceFieldName”属性指定数据源中的字段或扩充树中的节点。 “targetFieldName”属性指定接收内容的索引中的搜索字段。
扩充示例
本示例使用酒店评价技能组作为参考点,说明如何使用概念图通过技能执行来发展扩充树。
本示例还演示了如何执行以下操作:
- 技能的上下文和输入如何运作,以决定技能执行的次数
- 输入的形状取决于上下文
在本示例中,CSV 文件中的源字段包括客户对酒店的评价(“reviews_text”)和评级(“reviews_rating”)。 索引器会从 Blob 存储添加元数据字段,而技能则添加翻译文本、情绪评分和关键短语检测。
在酒店评价示例中,扩充流程中的“文档”表示单条酒店评价。
从概念上讲,初始的扩充树如下所示:

所有扩充的根节点是 "/document"。 使用 Blob 索引器时,"/document" 节点包含 "/document/content" 和 "/document/normalized_images" 的子节点。 如本示例中所示,当数据为 CSV 时,列名称映射到 "/document" 下面的节点。
技能#1:拆分技能
当源内容由大量文本组成时,最好将其分解为较小的组件,以便 进行集成矢量化,或者提高语言、情绪和关键短语检测的准确性。 有两个可用的粒度级别:页面和句子。 一个页面包含大约 5,000 个字符。
除了使用拆分技能进行分块外,还可以通过 Azure 内容理解技能 来实现,但该技能不在本文的讨论范围内。
需要分块时,拆分技能通常首先在技能集中。
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
在 "/document/reviews_text" 的技能上下文中,此拆分技能对 reviews_text 执行一次。 技能输出是一个列表,其中的 reviews_text 分块成包含 5,000 个字符的段。 拆分技能的输出名为 pages,将添加到扩充树中。 使用 targetName 功能可以在将技能输出添加到扩充树之前对其重命名。
现在,充实树在技能上下文下新增了一个节点。 此节点可用于任何技能、投影或输出字段映射。

若要访问由技能添加到节点的任何扩充,需要使用扩充的完整路径。 例如,要使用 pages 节点中的文本作为另一技能的输入,请将它指定为 "/document/reviews_text/pages/*"。 有关路径的详细信息,请参阅引用扩充。
技能 #2:语言检测
酒店评论文档包含以多种语言表达的客户反馈。 语言检测技能确定使用的是哪种语言。 接下来,结果将传递给短语提取和情感检测工具(未显示),并在检测情感和用语时考虑到语言。
尽管语言检测技能是技能组中定义的第三个技能(技能 #3),但它是下一个要执行的技能。 它不需要任何输入,因此它与前一个技能并行执行。 与前面的拆分技能一样,语言检测技能也只对每个文档调用一次。 扩充树现在包含新的语言节点。

技能 #3 和 #4(情绪分析和关键短语检测)
客户反馈反映了一系列正面和负面的体验。 情感分析功能分析反馈,并在负到正的连续区间内分配分数,如果无法确定情感,则被归为中性。 在进行情绪分析的同时,关键短语检测识别并提取看似重要的单词和短短语。
根据 /document/reviews_text/pages/* 的上下文,系统会对 pages 集合中的每个项都调用一次情绪分析和关键短语技能。 该技能的输出结果将作为一个节点,附加到关联的页面元素下。
现在,你应该能够查看技能集中的其他技能,并可视化增强树如何随着每个技能的执行而增长。 某些技能(例如合并技能和形状生成技能)也会创建新的节点,但只使用现有节点中的数据,而不会创建新的补充。

上述树中的连接线颜色显示出扩充是由不同技能创建的,因此这些节点需要分别处理,并且在选择父节点时,它们不会作为返回对象的一部分。
技能 #5 造型技能
如果输出中包含知识存储,就添加一个Shaper技能作为最后一步。 整形程序技能使用扩充树中的节点创建数据形状。 例如,你可能想要将多个节点合并为一个形状。 然后,便可以将此形状投影为一个表(节点成为表中的列),并按名称将形状传递到表投影。
Shaper 技能比较容易使用,因为它侧重于通过一项技能进行塑造。 或者,你可以选择在单个投影内进行内联剪裁。 塑造者技能不会增加或减少增益树,因此没有对其进行可视化。 相反,您可以将 Shaper 技能视为您重新阐述现有优化树的方法。 从概念上讲,这类似于在数据库中使用表创建视图。
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"description": null,
"context": "/document",
"inputs": [
{
"name": "name",
"source": "/document/name"
},
{
"name": "reviews_date",
"source": "/document/reviews_date"
},
{
"name": "reviews_rating",
"source": "/document/reviews_rating"
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "AzureSearch_DocumentKey",
"source": "/document/AzureSearch_DocumentKey"
},
{
"name": "pages",
"sourceContext": "/document/reviews_text/pages/*",
"inputs": [
{
"name": "Sentiment",
"source": "/document/reviews_text/pages/*/Sentiment"
},
{
"name": "LanguageCode",
"source": "/document/Language"
},
{
"name": "Page",
"source": "/document/reviews_text/pages/*"
},
{
"name": "keyphrase",
"sourceContext": "/document/reviews_text/pages/*/Keyphrases/*",
"inputs": [
{
"name": "Keyphrases",
"source": "/document/reviews_text/pages/*/Keyphrases/*"
}
]
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "tableprojection"
}
]
}
后续步骤
借助介绍和示例,尝试使用内置技能创建第一个技能组。