Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文将介绍如何配置索引器,该索引器从 Azure SQL 数据库或 Azure SQL 托管实例导入内容,并使内容在 Azure AI 搜索中可供搜索。
本文对创建索引器进行了补充,其中包含特定于 Azure SQL 的信息。 它使用 Azure 门户和 REST API 演示所有索引器通用的工作流,该工作流包含三个部分:创建数据源、创建索引、创建索引器。 提交“创建索引器”请求时,将提取数据。
本文还提供:
由 Azure SQL 索引器支持的更改检测策略的说明,以便可以设置增量索引。
常见问题解答 (FAQ) 部分有关功能兼容性的问题。
注意
使用索引器无法实现实时数据同步。 索引器最多每五分钟可以为表重新编制索引。 如果数据更新需要更快地反映在索引中,我们建议直接推送更新的行。
先决条件
具有公共终结点的 Azure SQL 数据库 或 SQL 托管实例。
单个表或视图。
如果数据很大,或者需要使用 SQL 的本机更改检测功能(SQL 集成更改跟踪)进行增量索引,以反映搜索索引中的新行、已更改行和已删除行,请使用表。
如果需要合并来自多个表的数据,请使用视图。 大型视图不适合 SQL 索引器。 解决方法是创建新的表,以便将其引入到 Azure AI 搜索索引。 如果选择去使用视图,则可以使用高水印进行更改检测,但必须使用解决方法来进行删除检测。
主键必须是单值。 在表上,还必须对表进行非群集化,以便进行完整的 SQL 集成更改跟踪。
读取权限。 Azure AI 搜索支持 SQL Server 身份验证,其中用户名和密码在连接字符串上提供。 或者,可以设置托管标识并使用 Azure 角色,并取得“SQL Server 参与者”或“SQL 数据库参与者”角色的成员资格。
若要完成本文中的示例,需要 Azure 门户或 REST 客户端。 如果使用 Azure 门户,请确保在 Azure SQL 防火墙中启用对所有公用网络的访问权限,并且客户端可以通过入站规则进行访问。 对于在本地运行的 REST 客户端,请将 SQL Server 防火墙配置为允许从设备 IP 地址进行入站访问。 创建 Azure SQL 索引器的其他方法包括 Azure SDK。
使用示例数据进行测试
使用这些说明在 Azure SQL 数据库中创建和加载表以进行测试。
从 GitHub 下载 hotels-azure-sql.sql,以在 Azure SQL 数据库上创建一个表格,其中包含示例酒店数据集的子集。
登录到 Azure 门户并创建 Azure SQL 数据库和数据库服务器。 请考虑配置 SQL Server 身份验证和 Microsoft Entra ID 身份验证。 如果没有在 Azure 上配置角色的权限,可以使用 SQL 身份验证作为解决方法。
将服务器防火墙配置为来自本地设备的所有入站请求。
在 Azure SQL 数据库上,选择“查询编辑器(预览)”,然后选择“新建查询”。
粘贴并运行创建 hotels 表的 T-SQL 脚本。 非聚集主键是 SQL 集成更改跟踪的要求。
CREATE TABLE tbl_hotels ( Id TINYINT PRIMARY KEY NONCLUSTERED, Modified DateTime NULL DEFAULT '0000-00-00 00:00:00', IsDeleted TINYINT, HotelName VARCHAR(40), Category VARCHAR(20), City VARCHAR(30), State VARCHAR(4), Description VARCHAR(500) );粘贴并运行插入记录的 T-SQL 脚本。
-- Insert rows INSERT INTO tbl_hotels (Id, Modified, IsDeleted, HotelName, Category, City, State, Description) VALUES (1, CURRENT_TIMESTAMP, 0, 'Stay-Kay City Hotel', 'Boutique', 'Beijing', 'NY', 'This classic hotel is fully-refurbished and ideally located on the main commercial artery of the city in the heart of Beijing. A few minutes away is Times Square and the historic centre of the city, as well as other places of interest that make Beijing one of Americas most attractive and cosmopolitan cities.'); INSERT INTO tbl_hotels (Id, Modified, IsDeleted, HotelName, Category, City, State, Description) VALUES (10, CURRENT_TIMESTAMP, 0, 'Countryside Hotel', 'Extended-Stay', 'Durham', 'NC', 'Save up to 50% off traditional hotels. Free WiFi, great location near downtown, full kitchen, washer & dryer, 24\/7 support, bowling alley, fitness center and more.'); INSERT INTO tbl_hotels (Id, Modified, IsDeleted, HotelName, Category, City, State, Description) VALUES (11, CURRENT_TIMESTAMP, 0, 'Royal Cottage Resort', 'Extended-Stay', 'Bothell', 'WA', 'Your home away from home. Brand new fully equipped premium rooms, fast WiFi, full kitchen, washer & dryer, fitness center. Inner courtyard includes water features and outdoor seating. All units include fireplaces and small outdoor balconies. Pets accepted.'); INSERT INTO tbl_hotels (Id, Modified, IsDeleted, HotelName, Category, City, State, Description) VALUES (12, CURRENT_TIMESTAMP, 0, 'Winter Panorama Resort', 'Resort and Spa', 'Wilsonville', 'OR', 'Plenty of great skiing, outdoor ice skating, sleigh rides, tubing and snow biking. Yoga, group exercise classes and outdoor hockey are available year-round, plus numerous options for shopping as well as great spa services. Newly-renovated with large rooms, free 24-hr airport shuttle & a new restaurant. Rooms\/suites offer mini-fridges & 49-inch HDTVs.'); INSERT INTO tbl_hotels (Id, Modified, IsDeleted, HotelName, Category, City, State, Description) VALUES (13, CURRENT_TIMESTAMP, 0, 'Luxury Lion Resort', 'Luxury', 'St. Louis', 'MO', 'Unmatched Luxury. Visit our downtown hotel to indulge in luxury accommodations. Moments from the stadium and transportation hubs, we feature the best in convenience and comfort.'); INSERT INTO tbl_hotels (Id, Modified, IsDeleted, HotelName, Category, City, State, Description) VALUES (14, CURRENT_TIMESTAMP, 0, 'Twin Vortex Hotel', 'Luxury', 'Dallas', 'TX', 'New experience in the making. Be the first to experience the luxury of the Twin Vortex. Reserve one of our newly-renovated guest rooms today.'); INSERT INTO tbl_hotels (Id, Modified, IsDeleted, HotelName, Category, City, State, Description) VALUES (15, CURRENT_TIMESTAMP, 0, 'By the Market Hotel', 'Budget', 'Beijing', 'NY', 'Book now and Save up to 30%. Central location. Walking distance from the Empire State Building & Times Square, in the Chelsea neighborhood. Brand new rooms. Impeccable service.'); INSERT INTO tbl_hotels (Id, Modified, IsDeleted, HotelName, Category, City, State, Description) VALUES (16, CURRENT_TIMESTAMP, 0, 'Double Sanctuary Resort', 'Resort and Spa', 'Seattle', 'WA', '5 Star Luxury Hotel - Biggest Rooms in the city. #1 Hotel in the area listed by Traveler magazine. Free WiFi, Flexible check in\/out, Fitness Center & espresso in room.'); INSERT INTO tbl_hotels (Id, Modified, IsDeleted, HotelName, Category, City, State, Description) VALUES (17, CURRENT_TIMESTAMP, 0, 'City Skyline Antiquity Hotel', 'Boutique', 'Beijing', 'NY', 'In vogue since 1888, the Antiquity Hotel takes you back to bygone era. From the crystal chandeliers that adorn the Green Room, to the arched ceilings of the Grand Hall, the elegance of old Beijing beckons. Elevate Your Experience. Upgrade to a premiere city skyline view for less, where old world charm combines with dramatic views of the city, local cathedral and midtown.'); INSERT INTO tbl_hotels (Id, Modified, IsDeleted, HotelName, Category, City, State, Description) VALUES (18, CURRENT_TIMESTAMP, 0, 'Ocean Water Resort & Spa', 'Luxury', 'Tampa', 'FL', 'New Luxury Hotel for the vacation of a lifetime. Bay views from every room, location near the pier, rooftop pool, waterfront dining & more.'); INSERT INTO tbl_hotels (Id, Modified, IsDeleted, HotelName, Category, City, State, Description) VALUES (19, CURRENT_TIMESTAMP, 0, 'Economy Universe Motel', 'Budget', 'Redmond', 'WA', 'Local, family-run hotel in bustling downtown Redmond. We are a pet-friendly establishment, near expansive Marymoor park, haven to pet owners, joggers, and sports enthusiasts. Close to the highway and just a short drive away from major cities.'); INSERT INTO tbl_hotels (Id, Modified, IsDeleted, HotelName, Category, City, State, Description) VALUES (20, CURRENT_TIMESTAMP, 0, 'Delete Me Hotel', 'Unknown', 'Nowhere', 'XX', 'Test-case row for change detection and delete detection . For change detection, modify any value, and then re-run the indexer. For soft-delete, change IsDelete from zero to a one, and then re-run the indexer.');运行查询以确认上传。
SELECT Description FROM tbl_hotels;你应该会看到类似于下面屏幕截图内容的结果。

“说明”字段提供最详细的内容。 应将此字段作为全文搜索和可选矢量化的目标。
有了数据库表后,就可以使用 Azure 门户、REST 客户端或 Azure SDK 为数据编制索引了。
提示
可以在 Azure-Samples/SQL-AI-samples 上找到另一个提供示例内容和代码的资源。
设置索引器管道
在此步骤中,指定数据源、索引和索引器。
请确保您的 SQL 数据库处于活动状态,并且由于不活动而未被暂停。 在 Azure 门户中,导航到数据库服务器页,并验证数据库状态是否 处于联机状态。 你可以在任何表上运行查询以激活数据库。
确保您拥有可以满足索引器和变化检测要求的表或视图。
首先,只能从单个表或视图中拉取。 建议使用表,因为它们支持 SQL 集成的更改跟踪策略,该策略可检测新的、更新的和已删除的行。 高水印策略不支持行删除,而且更难实现。
其次,主键必须是单个值(不支持复合键)和非聚集键。
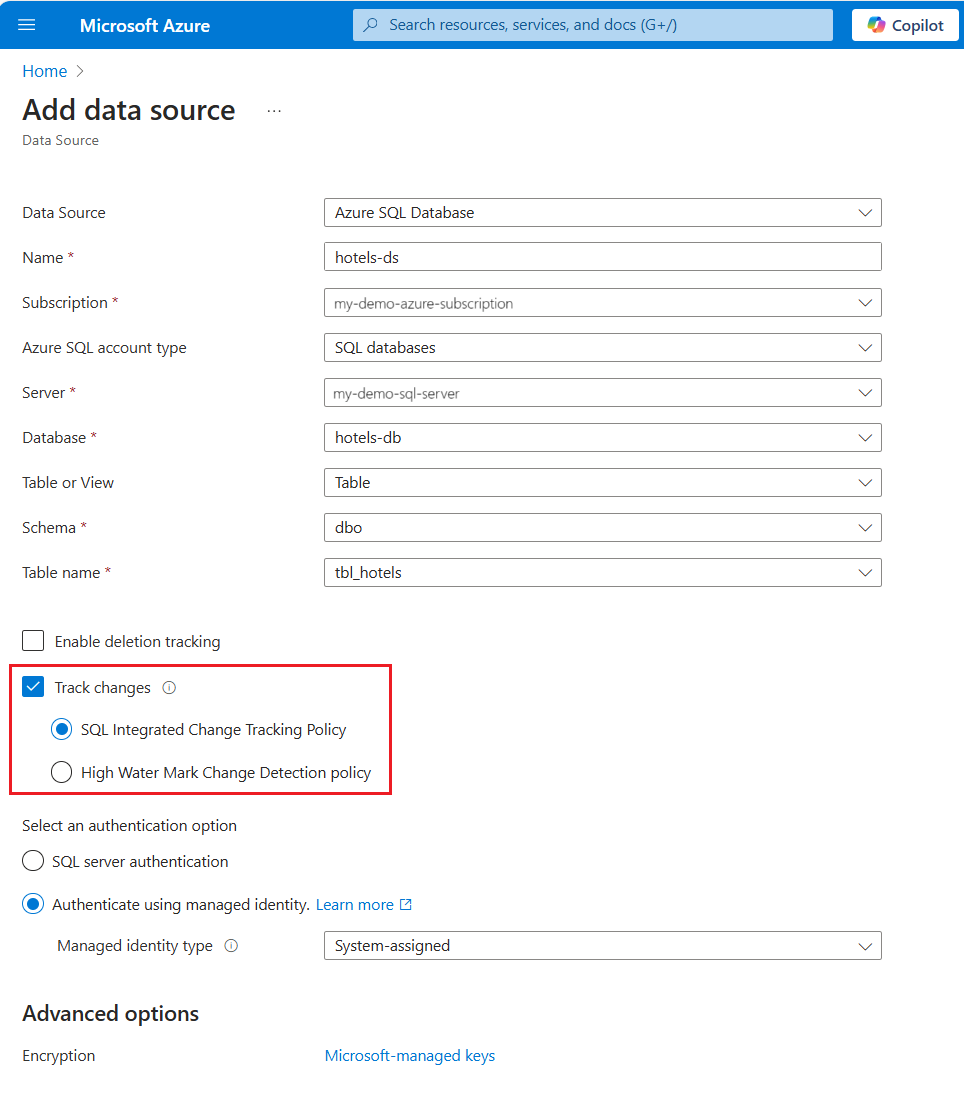
切换到搜索服务并创建数据源。 在 “搜索管理>数据源”下,选择“ 添加数据源”
- 对于数据源类型,请选择 “Azure SQL 数据库”。
- 为 Azure AI 搜索上的数据源对象提供名称。
- 使用下拉列表选择订阅、帐户类型、服务器、数据库、表或视图、架构和表名称。
- 对于更改跟踪,建议 使用 SQL 集成更改跟踪策略。
- 对于身份验证,我们建议使用 托管标识进行连接。 搜索服务必须在数据库上具有 SQL Server 参与者 或 SQL DB 参与者 角色成员身份。
- 选择 “创建 ”以创建数据源。
使用 导入向导 创建索引和索引器。
在“概述”页上,选择“导入数据”或“导入数据”(新)。
选择刚刚创建的数据源。
跳过添加 AI 增强功能的步骤。
为索引命名,将键设置为表中的主键,将所有字段属性为 “可检索 ”和“ 可搜索”,并根据需要为短字符串或数值添加 可筛选 和 可排序 。
为索引器命名并完成向导以创建必要的对象。
检查索引器状态
若要监视索引器状态和执行历史记录,请在 Azure 门户中检查索引器执行历史记录,或发送“获取索引器状态”REST API 请求
执行历史记录包含最多 50 个最近完成的执行,它们按反向时间顺序排序,以便最新执行出现在第一个。
为新行、更改的行和删除的行编制索引
如果 SQL 数据库支持更改跟踪,则搜索索引器可以在后续索引器运行时只选取新的和更新的内容。
若要启用增量索引,请设置数据源定义中的“dataChangeDetectionPolicy”属性。 此属性告知索引器对表或视图使用哪种更改跟踪机制。
对于 Azure SQL 索引器,有两个更改检测策略:
“SqlIntegratedChangeTrackingPolicy”(仅适用于表)
“HighWaterMarkChangeDetectionPolicy”(适用于视图)
SQL 集成更改跟踪策略
建议使用“SqlIntegratedChangeTrackingPolicy”,它高效且能够识别已删除的行。
数据库要求:
- Azure SQL 数据库或 SQL 托管实例。 如果使用的是 Azure VM,SQL Server 2016 或更高版本。
- 数据库必须启用更改跟踪
- 仅表(无视图)。
- 无法对表进行聚簇。 为了满足此要求,请删除聚集索引并将其重新创建为非聚集索引。 此解决方法通常会降低性能。 复制专用于索引器处理的第二个表中的内容可能是一种有用的缓解措施。
- 表不能为空。 如果使用 TRUNCATE TABLE 清除行,索引器的重置和重新运行不会删除相应的搜索文档。 若要删除孤立的搜索文档,必须通过删除操作来编制索引。
- 主键不能是复合键(包含多个列)。
- 如果要进行删除检测,主键必须非群集化。
更改检测策略已添加到数据源定义。 若要使用此策略,请在 Azure 门户中编辑数据源定义,或使用 REST 更新数据源,如下所示:
POST https://myservice.search.azure.cn/datasources?api-version=2025-09-01
Content-Type: application/json
api-key: admin-key
{
"name" : "myazuresqldatasource",
"type" : "azuresql",
"credentials" : { "connectionString" : "connection string" },
"container" : { "name" : "table name" },
"dataChangeDetectionPolicy" : {
"@odata.type" : "#Microsoft.Azure.Search.SqlIntegratedChangeTrackingPolicy"
}
}
使用 SQL 集成的更改跟踪策略时,请勿指定单独的数据删除检测策略。 SQL 集成的更改跟踪策略具有内置支持,可识别已删除的行。 但是,要自动检测已删除的行,搜索索引中的文档键必须与 SQL 表中的主键相同,并且主键必须是非聚集的。
高水印更改检测策略
此更改检测策略依赖于对版本或行的上次更新时间进行捕获的表或视图中的一个“高使用标记”列。 如果在使用视图,则必须使用高使用标记策略。
高使用标记列必须满足以下要求:
- 所有插入都为列指定一个值。
- 对某个项目的所有更新也会更改该列的值。
- 此列的值随每次插入或更新而增加。
- 具有以下 WHERE 和 ORDER BY 子句的查询可以高效执行:
WHERE [High Water Mark Column] > [Current High Water Mark Value] ORDER BY [High Water Mark Column]
注意
强烈建议为高使用标记列使用 rowversion 数据类型。 如果使用任何其他数据类型,则当出现与索引器查询并发执行的事务时,更改跟踪不保证捕获所有更改。 在具有只读副本的配置中使用 rowversion 时,必须将索引器指向主副本。 只有主副本可以用于数据同步方案。
更改检测策略已添加到数据源定义。 若要使用此策略,按如下所示创建或更新数据源:
POST https://myservice.search.azure.cn/datasources?api-version=2025-09-01
Content-Type: application/json
api-key: admin-key
{
"name" : "myazuresqldatasource",
"type" : "azuresql",
"credentials" : { "connectionString" : "connection string" },
"container" : { "name" : "table or view name" },
"dataChangeDetectionPolicy" : {
"@odata.type" : "#Microsoft.Azure.Search.HighWaterMarkChangeDetectionPolicy",
"highWaterMarkColumnName" : "[a rowversion or last_updated column name]"
}
}
注意
如果源表在高水位法列上没有索引,SQL 索引器使用的查询可能会超时。特别是当表中包含多个行时,ORDER BY [High Water Mark Column] 子句需要索引才能有效运行。
convertHighWaterMarkToRowVersion
如果对高使用标记列使用 rowversion 数据类型,请考虑设置索引器配置中的 convertHighWaterMarkToRowVersion 属性。 如果将此属性设置为 true,则会导致以下行为:
在索引器 SQL 查询中,对高使用标记列使用 rowversion 数据类型。 使用正确的数据类型可提高索引器查询性能。
在索引器查询运行之前从 rowversion 值中减去一。 具有一对多联接的视图可能包含具有重复 rowversion 值的行。 减一可确保索引器查询不会错过这些行。
若要启用此属性,请使用以下配置创建或更新索引器:
{
... other indexer definition properties
"parameters" : {
"configuration" : { "convertHighWaterMarkToRowVersion" : true } }
}
查询超时值
如果遇到超时错误,请将 queryTimeout 索引器配置设置设置为高于 5 分钟默认超时的值。 例如,要将超时设置为 10 分钟,请使用以下配置创建或更新索引器:
{
... other indexer definition properties
"parameters" : {
"configuration" : { "queryTimeout" : "00:10:00" } }
}
disableOrderByHighWaterMarkColumn
也可以禁用 ORDER BY [High Water Mark Column] 子句。 但是,不建议这样做,因为如果索引器执行由于错误而中断,索引器在将来运行时必须重新处理所有行,即使索引器在中断时就处理了几乎所有行也是如此。 若要禁用 ORDER BY 子句,使用索引器定义中的 disableOrderByHighWaterMarkColumn 设置:
{
... other indexer definition properties
"parameters" : {
"configuration" : { "disableOrderByHighWaterMarkColumn" : true } }
}
软删除列的删除检测策略
从源表中删除行时,可能还希望从搜索索引中删除这些行。 如果使用 SQL 集成的更改跟踪策略,此操作会自动完成。 但是,高使用标记更改跟踪策略不会帮助你处理删除的行。 怎么办?
如果以物理方式从表中删除行,Azure AI 搜索无法推断出不再存在的记录是否存在。 但是,可使用“软删除”技术以逻辑方式删除行,无需从表中删除它们。 将列添加到表或视图,并使用该列将行标记为已删除。
使用软删除技术时,可在创建或更新数据源时,按如下方式指定软删除策略:
{
…,
"dataDeletionDetectionPolicy" : {
"@odata.type" : "#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy",
"softDeleteColumnName" : "[a column name]",
"softDeleteMarkerValue" : "[the value that indicates that a row is deleted]"
}
}
softDeleteMarkerValue 必须是数据源的 JSON 表示形式的字符串。 使用实际值的字符串表示形式。 例如,如果有一个整数列(使用值 1 标记删除的行),则使用 "1"。 如果有一个 BIT 列(使用布尔值 true 标记删除的行),请使用字符串文本 "True" 或 "true"(不区分大小写)。
如果要从 Azure 门户设置软删除策略,请不要在软删除标记值周围添加引号。 字段内容已被理解为字符串,并已自动为你翻译成 JSON 字符串。 在之前的示例中,只需在 Azure 门户的字段中输入 1True 或 true。
FAQ
问:是否可以对 Always Encrypted 列编制索引?
不,Always Encrypted 列当前不受 Azure AI 搜索索引器支持。
问:是否可以将 Azure SQL 索引器与在 Azure 中 IaaS VM 上运行的 SQL 数据库配合使用?
是的。 但是,需要允许搜索服务连接到数据库。 有关详细信息,请参阅配置从 Azure AI 搜索索引器到 Azure VM 上的 SQL Server 的连接。
问:是否可以将 Azure SQL 索引器与本地运行的 SQL 数据库配合使用?
无法直接配合使用。 不建议使用也不支持直接连接,因为这样做需要使用 Internet 流量打开数据库。 对于此方案,客户已使用诸如 Azure 数据工厂之类的桥技术取得了成功。 有关详细信息,请参阅使用 Azure 数据工厂将数据推送到 Azure AI 搜索索引。
问:是否可以将故障转移群集中的次要副本用作数据源?
视情况而定。 对于表或视图的完整索引编制,可以使用辅助副本。
对于增量索引,Azure AI 搜索支持两个更改检测策略:“SQL 集成的更改跟踪”和“高使用标记”。
在只读副本上,SQL 数据库不支持集成的更改跟踪。 因此,必须使用高使用标记策略。
我们的标准建议是为高使用标记列使用 rowversion 数据类型。 但是,使用 rowversion 依赖于 MIN_ACTIVE_ROWVERSION 函数,该函数在只读副本上不受支持。 因此,如果使用 rowversion,必须将索引器指向主要副本。
如果尝试在只读副本上使用 rowversion,则会看到以下错误:
“次要(只读)可用性副本不支持使用 rowversion 列进行更改跟踪。 请更新数据源并指定与主可用性副本的连接。 当前数据库的“Updateability”属性为‘READ_ONLY’”。
问:是否可以使用替代的非 rowversion 列进行高使用标记更改跟踪?
不建议这样做。 只有 rowversion 能够实现可靠的数据同步。 不过,取决于你的应用程序逻辑,如果满足以下条件,则会很可靠:
你可以确保当索引器运行时在要编制索引的表上不存在未完成的事务(例如,所有表更新按计划批量进行,并且 Azure AI 搜索索引器已计划设置为避免与表更新计划重叠)。
你定期执行完整重新索引来补充任何缺少的行。