Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
在Azure AI 搜索中,可通过多种方式运行索引器:
- 创建索引器时立即运行。 这是默认值,除非创建处于“已禁用”状态的索引器。
- 按计划运行以便按固定间隔调用执行。
- 按需运行(使用或不使用“重置”)。
本文介绍如何在有和没有重置的情况下按需运行索引器。 它还描述了索引器执行、持续时间和并发。
索引器如何连接到Azure资源
索引器是少数明确对其他 Azure 资源进行出站调用的子系统之一。 根据所使用的外部数据源,可以使用密钥或角色对连接进行身份验证。
在Azure角色方面,索引器没有单独的标识:使用搜索服务的系统或用户分配的托管标识,以及目标Azure资源上的角色分配,从搜索引擎连接到另一个Azure资源。 如果索引器连接到虚拟网络上的Azure资源,则应为该连接创建共享的专用链接。
注意
索引器使用服务级别权限而不是用户权限运行。 即使您为了限制对特定索引的访问而分配了角色,索引器仍然可以写入搜索服务的任何索引。 有关详细信息,请参阅 每个索引的范围和索引器操作。
索引器执行
搜索服务为每个搜索单元运行一个索引器作业。 每个搜索服务都以一个搜索单位开头,但每个新分区或副本都会增加服务的搜索单位。 可以在 Azure 门户的 Overview 页的 Essential 部分检查搜索单位计数。 如果需要并发处理,请确保搜索单元包含足够的副本。 索引器不会在后台运行,因此,如果服务面临压力,您可能会比平时更频繁地遇到查询速度变慢的情况。
以下屏幕截图显示了搜索单位数,它确定可以一次运行多少个索引器。

索引器开始执行后,无法暂停或停止它。 当没有更多文档可加载或刷新时,或者当达到最长运行时间限制时,索引器执行将停止。
可在假定容量充足的情况下一次运行多个索引器,但每个索引器本身就是一个实例。 在索引器已在执行时启动新实例会生成以下错误:"Failed to run indexer "<indexer name>" error: "Another indexer invocation is currently in progress; concurrent invocations are not allowed."
索引器执行环境
索引器作业在托管的执行环境中运行。 目前有两个环境:
专用执行环境在特定于搜索服务的搜索群集上运行。
多租户环境具有由Azure管理和保护的内容处理器,无需额外付费。 此环境用于卸载计算密集型处理,使服务特定的资源可用于日常操作。 大多数技能组尽可能在多租户环境中执行。 这是默认情况。
“计算密集型处理”是指在内容处理器和索引器作业上运行的用于处理大量文档或大型文档的技能集。 多租户内容处理器上的非技能集处理由预订规则和系统信息决定,并且不受客户控制。
您可以通过将索引器和技能集处理专门绑定到您的搜索群集,来防止在 Standard2 或更高版本的服务上使用多租户环境。
将executionEnvironment索引器定义中的参数设置为始终在专用执行环境中运行索引器。
IP 防火墙 会阻止多租户环境,因此,如果有防火墙, 请创建允许 多租户处理器连接的规则。
索引器限制因环境而异:
| 工作负荷 | 最大持续时间 | 最大任务数 | 执行环境 |
|---|---|---|---|
| 私有执行 | 24 小时 | 每个搜索单元1都会分配一个索引器作业。 | 索引编制不会在后台运行。 相反,搜索服务会将所有索引作业与正在进行的查询和对象管理作(例如创建或更新索引)进行平衡。 运行索引器时,如果索引量很大,应该会出现一定的查询延迟。 |
| 多租户 | 2 小时 2 | 不确定 3 | 由于内容处理群集是多租户的,因此会添加内容处理器来满足需求。 如果在按需或计划执行中遇到延迟,则可能是因为系统正在添加处理器或等待处理器变为可用。 |
1 搜索单位可以是分区和副本的灵活组合,但索引器作业并不相互关联。 换言之,如果你有 12 个单位,则无论搜索单位如何部署,你都可以在专用执行中并发运行 12 个索引器作业。
2 如果需要两个多小时来处理所有数据, 请启用更改检测 并 计划索引器 以 5 分钟间隔运行,以便在由于超时而停止索引时快速恢复索引。 有关更多策略,请参阅 为大型数据集编制索引 。
3“不确定”表示限制不是由作业数目量化的。 某些工作负荷(如技能组处理)可以并行运行,这可能会导致出现许多作业,即使只涉及一个索引器。 尽管环境不施加约束,但搜索服务的索引器限制仍然适用。
无需重置即可运行
运行索引器操作只检测并处理将搜索索引与基础数据源中的更改同步所需的内容。 增量索引首先定位内部高水位标记,以找到上次更新的搜索文档,该文档将成为索引器在数据源中新文档和更新文档上执行索引的起点。
更改检测对于确定数据源中的新增内容或更新内容至关重要。 索引器使用基础数据源的更改检测功能来确定数据源中的新内容或已更新的内容。
Azure 存储通过其 LastModified 属性内置更改检测。
其他数据源(如Azure SQL或Azure Cosmos DB)必须配置为更改检测,然后索引器才能读取新的和更新的行。
如果基础内容未更改,则运行操作不起作用。 在这种情况下,索引器执行历史记录指示已处理 0\0 个文档。
你需要重置索引器,以便能够按照下一部分所述进行完全重新处理。
重置索引器
在初次运行后,索引器通过内部的高水位线跟踪已编制索引的搜索文档。 标记永远不会公开,但索引器在内部知道它上次停止的位置。
如果您需要重新构建索引的全部或部分内容,请使用对象层次结构中不同级别可用的重置 API。
重置后,使用 Run 命令重新处理新文档和现有文档。 对于数据源中没有对应的数据的孤立搜索文档,无法通过重置/运行操作进行删除。 如果需要删除特定文档,请参阅 “删除搜索索引 ”或 “文档 - 索引”中的文档 。
注意
表不能为空。 如果使用 TRUNCATE TABLE 清除行,索引器的重置和重新运行不会删除相应的搜索文档。 若要删除孤立的搜索文档,必须通过删除操作来编制索引。
如何重置并运行索引器
重置会清除高水位标记。 搜索索引中的所有文档都会标记为完全覆盖,而不会内联更新或合并到现有内容中。 对于具有技能集和 扩充缓存的索引器,重置索引也会隐式重置技能集。
当你在重置后执行 "Run" 命令时,实际工作就会发生:
- 在基础源中找到的所有新文档会添加到搜索索引中。
- 在搜索索引中覆盖同时存在于数据源和搜索索引的所有文档。
- 重新生成通过技能组创建的任何扩充内容。 刷新扩充缓存(如果已启用)。
如前所述,重置是一种被动操作:您必须发出运行请求来重新生成索引。
如果重置显式或隐式包含技能,则重置/运行操作适用于搜索索引或知识库、特定文档或投影以及缓存的扩充项。
重置也适用于创建和更新操作。 它不会对搜索索引中的孤立文档触发删除或清理。 有关删除文档的详细信息,请参阅“文档 - 索引”。
重置索引器后,无法撤消此操作。
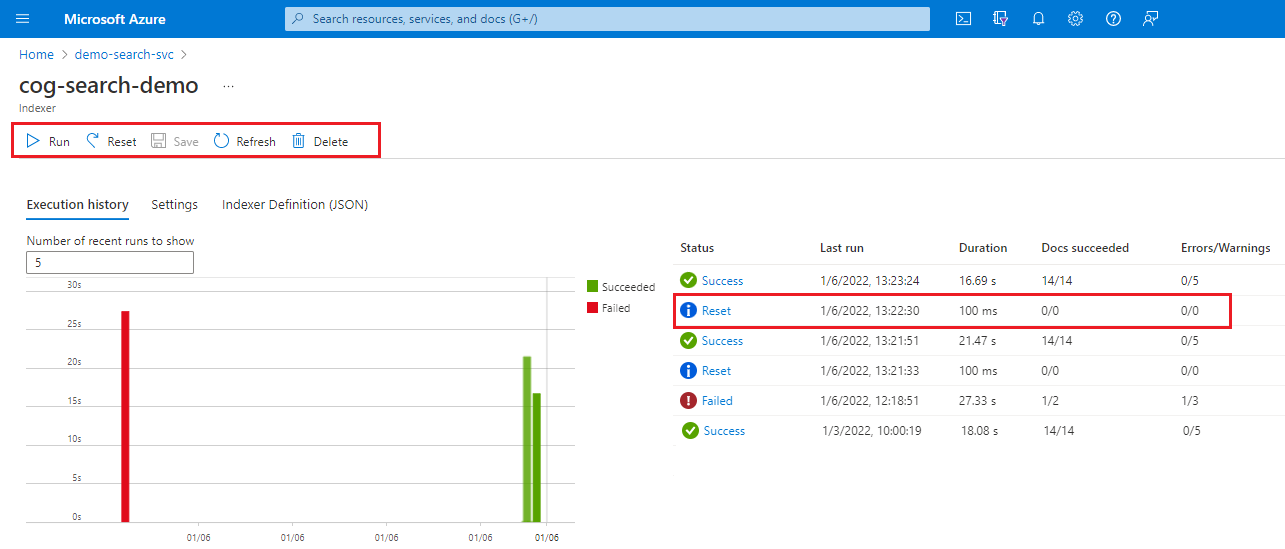
在 Azure 门户中,转到你的搜索服务。
在“概述”页上,选择“索引”选项卡。
选择索引器。
选择“重置”命令,然后选择“是”确认该操作。
刷新页面以显示状态。 你可以选择该项以查看其详细信息。
选择 运行 来开始索引器处理,或者等待下一个计划任务的执行。
如何重置技能(预览)
发送重置技能请求以在下一个索引器运行时选择性地处理一个或多个技能。 对于具有技能集的索引器,可以重置单个技能以强制重新处理该技能,以及依赖于其输出的任何下游技能。 扩充缓存(如果已启用)也会刷新。
对于启用了缓存的索引器,可以显式请求处理索引器无法检测到的技能更新。 例如,如果进行外部更改(如自定义技能的修订),则可以使用此 API 重新运行技能。 输出(如知识存储或搜索索引)使用缓存中的可重用数据以及根据更新的技能的新内容进行刷新。
建议 使用最新的预览 API。
POST /skillsets/[skillset name]/resetskills?api-version=2026-05-01-preview
{
"skillNames" : [
"#1",
"#5",
"#6"
]
}
可按以上示例中所示指定单个技能,但如果其中任一技能需要未列出的技能(#2 到 #4)的输出,则除非缓存可以提供必要的信息,否则未列出的技能将会运行。 若要做到这一点,技能 #2 到 #4 的已缓存扩充不得依赖于 #1(列为要重置的技能)。
如果未指定任何技能,则执行整个技能组;如果已启用缓存,则还会刷新缓存。
请注意,接下来请运行索引器来调用实际处理。
如何重置文档(预览版)
索引器 - 重置文档(预览版)接受文档键列表,以便可以刷新特定文档。 如果已指定重置参数,这些参数将成为要处理哪些内容的唯一决定因素,而不管基础数据发生了其他哪些更改。 例如,如果自上次索引器运行以来添加或更新了 20 个 Blob,但你只重置了一个文档,则只会处理该文档。
基于每个文档,搜索文档中的所有字段都会使用数据源中的值和元数据进行刷新。 无法选取要刷新的字段。
如果文档已通过技能组扩充并包含缓存的数据,则只会对指定的文档调用该技能组,并为已重新处理的文档更新缓存。
首次测试此 API 时,以下 API 可帮助你验证并测试行为。 建议使用最新的预览版 API。
使用预览 API 版本调用“索引器 - 获取状态”,以检查重置状态和执行状态。 可以在状态响应的末尾找到有关重置请求的信息。
使用预览 API 版本调用“索引器 - 重置文档”,以指定要处理的文档。
POST https://[service name].search.azure.cn/indexers/[indexer name]/resetdocs?api-version=2026-05-01-preview { "documentKeys" : [ "1001", "4452" ] }API 接受两种类型的文档标识符作为输入:用于唯一标识搜索索引中的文档的文档键,以及唯一标识数据源中的文档的数据源文档标识符。 正文应包含文档键列表 或 索引器在数据源中查找的数据源文档标识符列表。 调用 API 时,会将要重置的文档密钥或数据源文档标识符添加到索引器元数据。 在下一次计划或按需运行索引器时,索引器仅处理重置文档。
如果使用文档键来重置文档,并且文档密钥在索引器字段映射中被引用,索引器将使用字段映射在基础数据源中找到相应的字段。
请求中提供的文档键是搜索索引中的值,这些值可能不同于数据源中的相应字段。 如果你不确定键值,请发送查询以返回值。 可以使用
select来仅返回文档键字段。对于被解析为多个搜索文档的 blob(其中 parsingMode 设置为 jsonLines 或 jsonArrays,或 delimitedText),文档键由索引器生成,可能对您来说是未知的。 在此情况下,查询文档键以返回正确的值。
如果希望索引器停止尝试处理重置文档,可以将“documentKeys”或“datasourceDocumentIds”设置为空列表“[]”。 这会导致索引器根据高水位线恢复正常索引操作。 将忽略无效的文档键或不存在的文档键。
调用运行索引器(任何 API 版本)来处理指定文档。 仅为这些特定文档编制索引。
再次调用运行索引器以从上次的高水位标记开始处理。
调用搜索文档,用于检查已更新的值,如果你不确定值,此 API 还会返回文档键。 如果你要限制在响应中显示的字段,请使用
"select": "<field names>"。
覆盖文档键列表
多次调用重置文档 API 并使用不同的键,会将新键添加到已重置的文档键列表中。 如果调用 API 并将 overwrite 参数设置为 true,则会用新的列表覆盖当前列表:
POST https://[service name].search.azure.cn/indexers/[indexer name]/resetdocs?api-version=2026-05-01-preview
{
"documentKeys" : [
"200",
"630"
],
"overwrite": true
}
检查重置状态“currentState”
若要检查重置状态并查看哪些文档键已排队等待处理,请执行以下步骤。
使用预览 API 调用“获取索引器状态”。
预览版 API 将返回
currentState部分,该部分位于响应的末尾。"currentState": { "mode": "indexingResetDocs", "allDocsInitialTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "allDocsFinalTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "resetDocsInitialTrackingState": null, "resetDocsFinalTrackingState": null, "resyncInitialTrackingState": null, "resyncFinalTrackingState": null, "resetDocumentKeys": [ "200", "630" ] }查看“模式”:
对于“重置技能”,“模式”应设置为
indexingAllDocs(因为通过 AI 扩充填充的字段所在的所有文档都可能会受影响)。对于重新同步索引器,应将“mode”设置为
indexingResync。 索引器检查所有文档,并重点介绍数据源中感兴趣的数据以及目标索引中感兴趣的字段。对于“重置文档”,“模式”应设置为
indexingResetDocs。 索引器会将此状态保持到“重置文档”调用中提供的所有文档键都被处理完毕。在此操作进行期间,不会执行任何其他索引器作业。 在文档键列表中查找所有文档需要破解每个文档,以查找键并根据该键进行匹配,如果数据集较大,这可能需要一段时间。 如果 Blob 容器包含数百个 Blob,而你想要重置的文档放在最后,则索引器只有在事先检查了所有其他 Blob 之后,才能找到匹配的 Blob。重新处理文档后,再次运行“获取索引器状态”。 索引器将恢复
indexingAllDocs模式,并且在下次运行时,将处理任何新文档或已更新的文档。
检查 S3 HD 搜索服务的索引器运行时配额
适用于标准 3 级高密度(S3 HD)定价层上的搜索服务。
为了帮助你监视相对于 24 小时窗口的索引器运行时间, 获取服务统计信息 和 获取索引器状态 现在返回响应中的详细信息。
跟踪累积运行时配额
跟踪搜索服务的累积索引器运行时使用情况,并确定当前 24 小时时段内剩余的运行时配额。
将 GET 请求发送到搜索服务资源提供程序。 有关设置 REST 客户端和获取访问令牌的帮助,请参阅 “连接到搜索服务”。
GET {{search-endpoint}}/servicestats?api-version=2026-05-01-preview
Content-Type: application/json
Authorization: Bearer {{accessToken}}
响应包括 indexersRuntime 属性、显示过去 24 小时内的开始时间和结束时间、使用的秒数、剩余的秒数和累积运行时。
跟踪索引器运行时配额
返回单个索引器的相同信息。
GET {{search-endpoint}}/indexers/hotels-sample-indexer/search.status?api-version=2026-05-01-preview
Content-Type: application/json
Authorization: Bearer {{accessToken}}
响应包括一个 runtime 属性,其中显示了开始时间和结束时间、使用的秒数和剩余的秒数。
后续步骤
重置 API 用于告知下次索引器运行的范围。 在实际处理中,你需要调用按需运行索引器,或者允许计划任务完成工作。 运行完成后,索引器将恢复正常处理,不管是按计划的处理还是按需处理。
重置并重新运行索引器作业后,可以从搜索服务监视状态,或者通过资源日志记录获取详细信息。