Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文介绍 Azure AI 搜索中用于分析查询和索引性能的工具、行为和方法。
本文仅适用于 经典搜索、全文搜索方案。
制定基准数字
在所有大型实现中,将 Azure AI 搜索服务投入生产之前,对其执行性能基准测试非常重要。 不仅应测试预期的搜索查询负载,还应测试预期的数据引入工作负载(如果可能,请同时运行这两个工作负载)。 具有基准数字有助于验证正确的搜索层、服务配置和预期的查询延迟。
为避免分布式服务体系结构的影响,请尝试测试单个副本和单个分区的服务配置。
注意
与“标准”层相比,“存储优化”层(L1 和 L2)的查询吞吐量应更低,延迟应更高。
使用资源日志记录
可供管理员使用的最重要诊断工具是资源日志记录。 资源日志记录是有关搜索服务的操作数据和指标的集合。 资源日志记录是通过 Azure Monitor 启用的。 使用 Azure Monitor 并存储数据会产生费用,但如果为服务启用此功能,将有助于调查性能问题。
下图显示了查询请求和响应中的事件链。 无论是在网络传输、处理应用服务层中的内容期间,还是在搜索服务上,其中的任何一个都可能发生延迟。 资源日志记录的主要好处是:从搜索服务角度记录活动,这意味着日志有助于确定性能问题是由查询或索引的问题引起,还是其他一些故障点引起。
资源日志记录为存储日志信息提供了选项。 建议使用 Log Analytics,由此可对数据执行高级 Kusto 查询,从而解答有关使用情况和性能的许多问题。
在搜索服务门户页面上,您可以通过“诊断设置”启用日志记录,然后选择“日志”以对 Log Analytics 发起 Kusto 查询。 要了解如何将资源日志发送到 Log Analytics 工作区以在其中使用日志查询对其进行分析,请参阅从 Azure 资源收集和分析资源日志。
限制行为
当搜索服务的容量用尽时,会发生限制。 在查询或索引过程中可能会出现节流。 从客户端来看,API 调用在受到限制后会出现 503 HTTP 响应。 在索引过程中,还可能会收到 207 HTTP 响应,这表示一个或多个项未能编制索引。 此错误表示搜索服务接近容量。
作为一条经验法则,尝试量化节流的程度和任何模式。 例如,如果 500,000 个搜索查询中有一个受到限制,可能不值得调查。 然而,如果在一段时间内大量查询被限制,这将是一个更大的问题。 观察一段时间内的限流情况还能帮您识别更有可能发生限流的时间段,并帮助您决定如何最好地适应这种情况。
为了解决大多数限流问题,一种简单的方法是在搜索服务中增加更多资源(通常是用于基于查询的限流的副本,或用于基于索引的限流的分区)。 但增加副本或分区会增加成本,这就是为什么了解限制发生的原因很重要。 接下来的几节将会解释研究导致节流的条件。
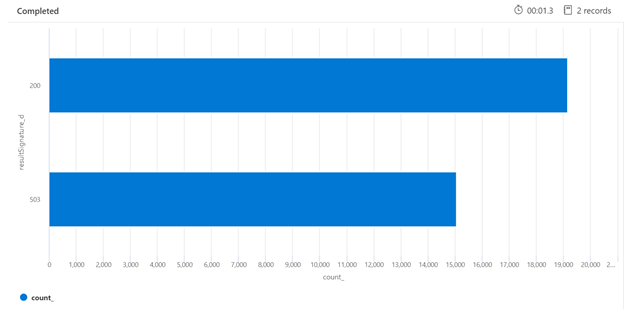
下面是一个 Kusto 查询示例,可识别来自已加载的搜索服务的 HTTP 响应的明细。 所呈现的 7 天时段条形图显示,与成功(200 个)响应的数量相比,有较大百分比的搜索查询受到了限制。
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
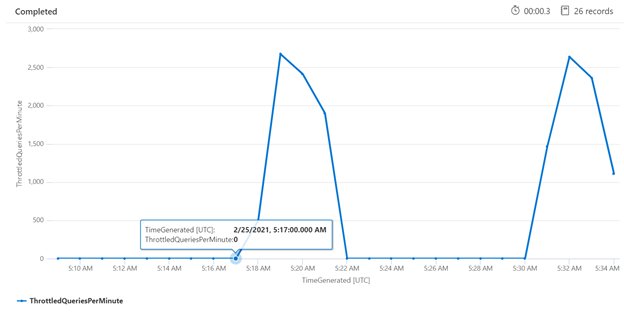
检查特定时间段内的限流有助于确定限流更频繁发生的时间点。 在下面的示例中,时序图用于显示在指定期限内发生的受限制的查询数。 在本例中,受限查询与执行性能基准测试的时间相关联。
let ['_startTime']=datetime('2024-02-25T20:45:07Z');
let ['_endTime']=datetime('2024-03-03T20:45:07Z');
let intervalsize = 1m;
AzureDiagnostics
| where TimeGenerated > ago(7d)
| where resultSignature_d != 403 and resultSignature_d != 404 and OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete")
| summarize
ThrottledQueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete") and resultSignature_d == 503)/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
测试单个查询
在某些情况下,测试单个查询以查看其执行情况会很有用。 若要执行此操作,必须能够查看搜索服务完成工作所需的时间,以及从客户端发出往返请求并返回到客户端的时间。 诊断日志可用于查找各个操作,但使用 REST 客户端可以更轻松地完成这一切。
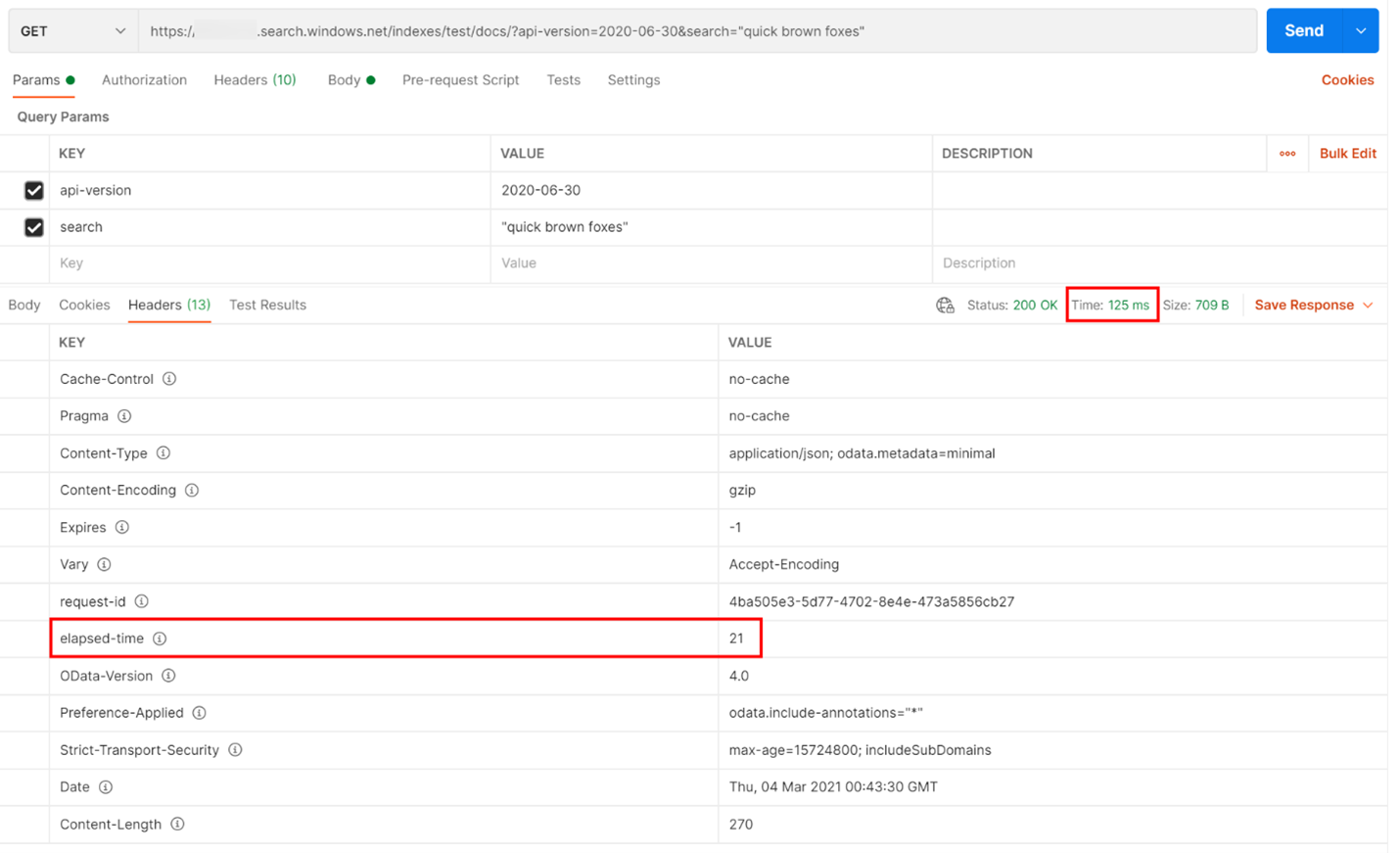
在下面的示例中,执行了基于 REST 的搜索查询。 Azure AI 搜索在每个响应中均包含完成查询所用的毫秒数(显示在在“标头”选项卡的“运行时间”中)。 在响应顶部的状态旁边,你将找到往返持续时间,在本例中为 125 毫秒(ms)。 在结果部分中,选择了“标头”选项卡。 使用下图中用红色框突出显示的这两个值,我们看到搜索服务耗时 21 毫秒完成搜索查询,而整个客户端往返请求耗时 125 毫秒。 将这两个数字相减,我们可以确定将搜索查询传输到搜索服务以及将搜索结果传输回客户端需要额外耗时 104 毫秒。
此方法可帮助你将网络延迟与影响查询性能的其他因素区分开来。
查询频率
搜索服务可能限制请求的一个原因是查询数量庞大,即查询量以每秒查询数 (QPS) 或每分钟查询数 (QPM) 来衡量。 随着您的搜索服务接收更多的 QPS,通常情况下,响应这些查询所需时间会越来越长,直到无法应对为止,此时将返回一个限流的 503 HTTP 响应。
以下 Kusto 查询显示了单位为 QPM 的查询量,以及单位为毫秒的查询平均持续时间 (AvgDurationMS) 和每个查询中返回的文档平均数量 (AvgDocCountReturned)。
AzureDiagnostics
| where OperationName == "Query.Search" and TimeGenerated > ago(1d)
| extend MinuteOfDay = substring(TimeGenerated, 0, 16)
| project MinuteOfDay, DurationMs, Documents_d, IndexName_s
| summarize QPM=count(), AvgDuractionMs=avg(DurationMs), AvgDocCountReturned=avg(Documents_d) by MinuteOfDay
| order by MinuteOfDay desc
| render timechart
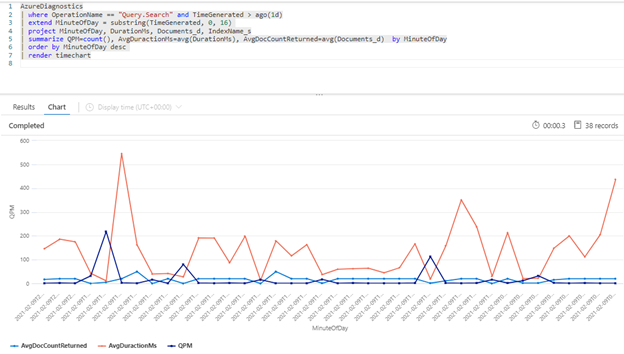
提示
若要显示此图表后面的数据,请删除此行 | render timechart 然后重新运行查询。
对查询的索引影响
查看性能时要考虑的一个重要因素是,索引使用的资源与搜索查询相同。 如果正在为大量内容编制索引,则当服务尝试同时容纳这两种工作负载时,可以预计延迟会增加。
如果查询速度变慢,请查看索引活动的时机,以确定它是否导致查询性能下降。 例如,可能是索引器运行的是每日或每小时的作业,而此作业与搜索查询性能降低相关联。
本节提供一组可帮助你可视化搜索和索引速度的查询。 对于这些示例,时间范围已设置在查询中。 在 Azure 门户中运行查询时,请确保指明“在查询中指定”。
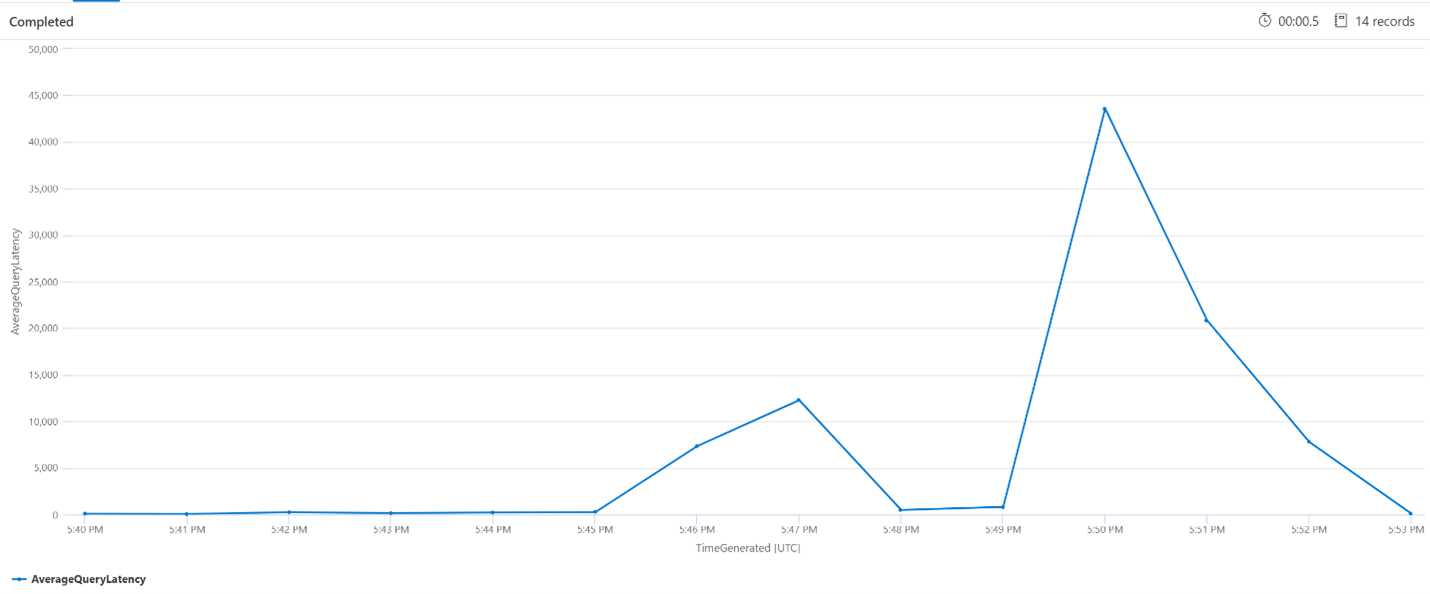
平均查询延迟
在下面的查询中,时间间隔大小为 1 分钟,用于显示搜索查询的平均延迟。 在该图中,可以看到直到下午 5:45 平均延迟很低,并且持续到下午 5:53。
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime']..['_endTime']) // Time range filtering
| summarize AverageQueryLatency = avgif(DurationMs, OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))
by bin(TimeGenerated, intervalsize)
| render timechart
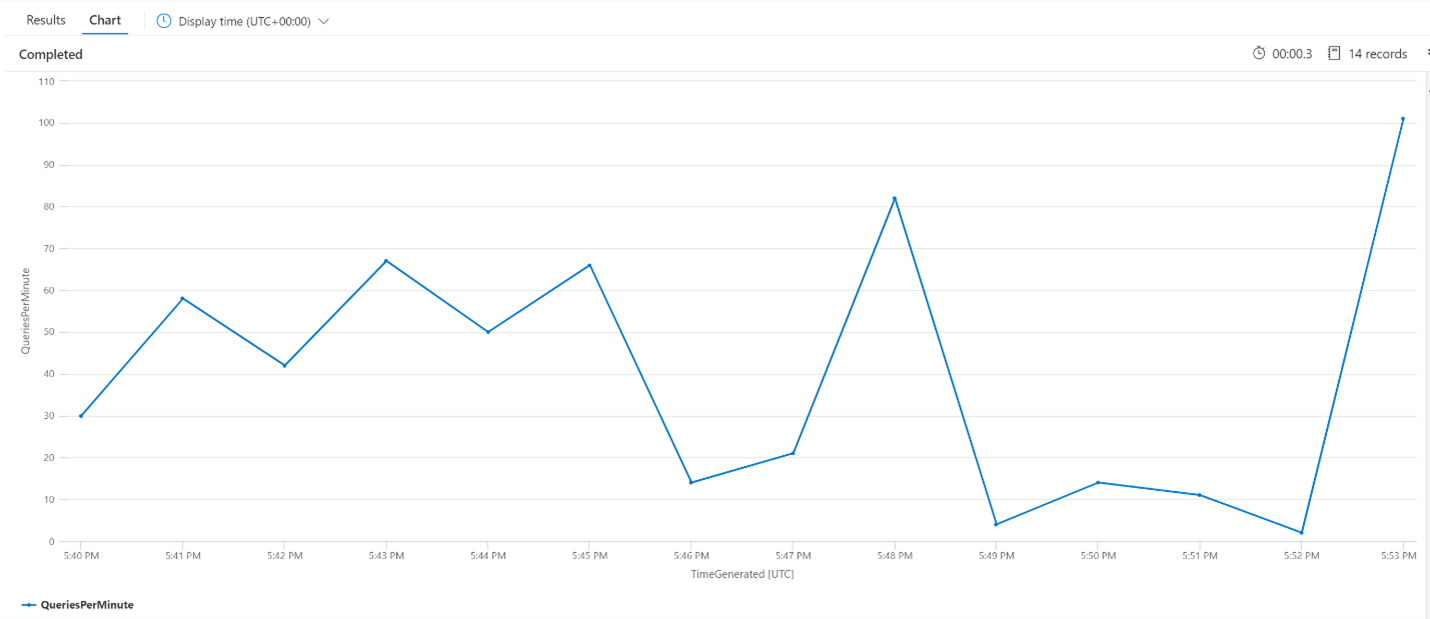
平均每分钟查询数 (QPM)
以下查询查看每分钟平均查询数,以确保不会出现可能影响延迟的搜索请求高峰。 从图表中可以看出存在一些波动,但没有任何迹象表明请求计数峰值。
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize QueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
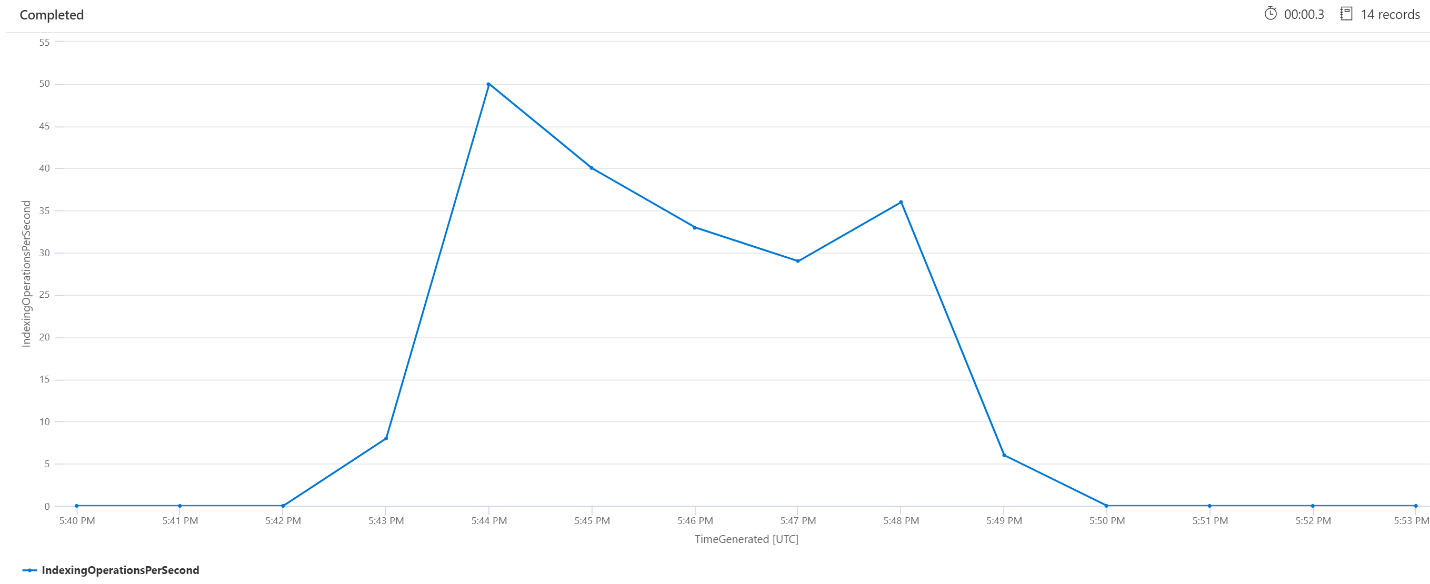
每分钟的索引操作次数 (OPM)
下面我们将介绍每分钟索引操作的数量。 在该图中,可以看到从下午 5:42 开始对大量数据编制索引,并在下午 5:50 结束。 该编制索引操作在搜索查询开始出现延迟前 3 分钟开始,并在搜索查询不再延迟前 3 分钟结束。
从此见解中,我们可以看到搜索服务在大约 3 分钟后变得繁忙,致使索引编制影响了查询延迟。 我们还可以看到,在索引编制完成后,搜索服务又花费了 3 分钟来完成新编制索引内容的所有工作,以及解决查询延迟问题。
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize IndexingOperationsPerSecond=bin(countif(OperationName == "Indexing.Index")/ (intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
后台服务处理
常见情况是查询或索引延迟偶尔出现峰值。 由于索引或查询率高,可能会出现峰值,但合并操作期间也可能出现。 搜索索引以区块或分片存储。 系统会定期将较小的分片合并为大型分片,这有助于优化服务性能。 此合并过程还会清除以前标记为要从索引中删除的文档,从而恢复存储空间。
合并分片的速度很快,但会占用大量资源,因此可能会降低服务性能。 如果你注意到短暂的查询延迟突发,并且这些突发与最近对编制索引内容的更改同时发生,则可以认为延迟是由分片合并操作所引起。
后续步骤
查看以下与分析服务性能相关的文章。