Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
全文搜索是一种信息检索方法,它匹配索引中存储的纯文本。 例如,给定查询字符串“hotels in San Diego on the beach”(圣地亚哥海滩酒店),搜索引擎将基于这些词查找标记化字符串。 为了使扫描更高效,查询字符串要进行词法分析:将所有术语转换为小写,删除例如“the”这样的一些停用词,并将术语精简到原根形式。 找到匹配的词时,搜索引擎将检索文档,按相关性顺序对文档进行排名,并返回排名靠前的结果。
查询执行可能比较复杂。 本文面向需要更深入了解 Azure AI 搜索中全文搜索工作原理的开发人员。 对于文本查询,Azure AI 搜索在大多数情况下无缝地提供预期的结果,但有时,您可能会获得似乎有些“不对劲”的结果。 在这些情况下,在 Lucene 查询执行的四个阶段(查询分析、词法分析、文档匹配和评分)中具有背景,可帮助你确定对生成所需结果的查询参数或索引配置的特定更改。
注意
Azure AI 搜索使用 Apache Lucene 进行全文搜索,但 Lucene 集成并不详尽。 我们有选择地公开和扩展 Lucene 的功能,以支持 Azure AI 搜索的重要场景。
体系结构概述和关系图
查询执行包括四个阶段:
- 查询解析
- 词法分析
- 文档检索
- 计分
全文搜索查询首先会分析查询文本以提取搜索词和运算符。 有两个分析程序,因此你可以在速度和复杂性之间进行选择。 接下来是分析阶段。在此阶段,单个查询词有时会分解并重新构造成新的形式。 此步骤有助于扩大可能被视为潜在匹配的范围。 然后,搜索引擎会扫描索引以查找具有匹配词的文档,并为每个匹配项评分。 然后,根据分配给每个匹配文档的相关性评分将结果集排序。 排名列表中位于顶部的项将返回到调用的应用程序。
下图演示了用于处理搜索请求的组件:
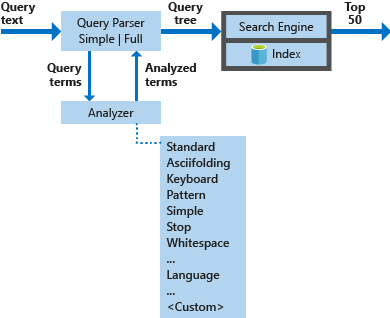
| 关键组件 | 功能说明 |
|---|---|
| 查询分析器 | 将查询词与查询运算符区分开来,并创建要发送到搜索引擎的查询结构(查询树)。 |
| 分析器 | 针对查询词执行词法分析。 此过程可以涉及转换、删除或扩展查询词。 |
| 索引 | 一个有效的数据结构,用于存储和组织从索引文档中提取的可搜索词。 |
| 搜索引擎 | 根据倒排索引的内容检索文档并为其评分。 |
搜索请求的剖析
搜索请求是一个完整的规范,描述了应在结果集中返回哪些内容。 最简单的形式是一个空查询,没有任何条件。 比较现实的搜索请求示例包含参数、多个查询词,其范围可能限定为某些字段,另外,可能还包含筛选表达式和排序规则。
以下示例是可以使用 REST API 发送到 Azure AI 搜索的搜索请求:
POST /indexes/hotels/docs/search?api-version=2026-04-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
对于此请求,搜索引擎执行以下操作:
查找价格至少为60美元,且低于300美元的文档。
执行查询。 在此示例中,搜索查询由短语和术语组成:
"Spacious, air-condition* +\"Ocean view\""(用户通常不输入标点符号,但通过在示例中包括它,我们可以解释分析器如何处理它。对于此查询,搜索引擎将扫描“searchFields”中指定的说明和标题字段,以查找包含
"Ocean view"的文档,此外还会根据字词"spacious"或者以前缀"air-condition"开头的字词执行搜索。 “searchMode”参数用于匹配任一字词(默认);如果未明确指定字词 (+),则匹配所有字词。根据与给定地理位置的距离将酒店结果集排序,然后将结果返回到调用方应用程序。
本文的大部分内容都与处理搜索查询有关: "Spacious, air-condition* +\"Ocean view\"" 筛选和排序不属于本文的介绍范畴。 有关详细信息,请参阅搜索 API 参考文档。
第 1 阶段:查询分析
如前所述,查询字符串是请求的第一行:
"search": "Spacious, air-condition* +\"Ocean view\"",
查询分析器将运算符(例如 * 和 + 示例中)与搜索词分开,并将搜索查询解构为受支持的类型的 子查询 :
- 针对独立字词(例如 spacious)的字词查询
- 针对带引号字词(例如 ocean view)的短语查询
- 对于后接有前缀运算符的词语(例如 air-condition)
*
有关支持的查询类型的完整列表,请参阅 Lucene 查询语法。
与子查询关联的运算符确定是“必须”还是“应该”满足该查询,才将某个文档视为匹配项。 例如,由于 +"Ocean view" 运算符,+ 是“必须”。
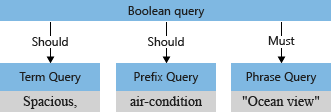
查询分析器将子查询重新构造为 查询树 (表示查询的内部结构),该查询将传递给搜索引擎。 在查询分析的第一个阶段中,查询树如下所示:
支持的分析器:简单和完整 Lucene
Azure AI 搜索公开两种不同的查询语言: simple (默认值)和 full。 通过使用搜索请求设置 queryType 参数,可让查询分析器知道你选择的查询语言,这样,它就知道如何解释运算符和语法。
简单查询语言直观且可靠,通常适合在不使用客户端处理的情况下解释用户输入 as-is。 它支持 Web 搜索引擎中常见的查询运算符。
完整 Lucene 查询语言:可通过设置
queryType=full获取该语言。它添加了对更多运算符和查询类型(例如通配符、模糊查询、正则表达式和限定字段的查询)的支持,从而扩展了默认的简单查询语言。 例如,在简单查询语法中发送的正则表达式将解释为查询字符串而不是表达式。 本文中的示例请求使用完整 Lucene 查询语言。
searchMode 对分析器的影响
影响分析的另一个搜索请求参数是“searchMode”参数。 该参数控制布尔查询的默认运算符:any(默认)或 all。
如果“searchMode=any”(默认设置),则 spacious 与 air-condition 之间的空间分隔符为 OR (||),因此,示例查询文本等效于:
Spacious,||air-condition*+"Ocean view"
显式运算符(例如 + 中的 +"Ocean view")在布尔查询构造中没有歧义(必须匹配)。 剩余字词的解释方式不太明确:spacious 和 air-condition。 搜索引擎是否应该查找与海景、宽敞和空调相关的匹配项? 或者,是否应该查找 ocean view 加上任意一个剩余的字词?
默认情况下(“searchMode=any”),搜索引擎采用更广泛的解释。 需匹配任一字段,以反映“或者”的语义。 上面所示的初始查询树包含两个“should”运算符,显示了默认行为。
假设我们现在设置“searchMode=all”。 在这种情况下,空格被解释为“and”运算。 若要符合匹配条件,文档中必须包含这两个剩余术语。 生成的示例查询将如下所示进行解释:
+Spacious,+air-condition*+"Ocean view"
此查询的修改查询树,其中匹配的文档是所有三个子查询的交集,如下所示:

注意
选择“searchMode=any”而非“searchMode=all”是运行代表性查询做出的最佳决策。 经常使用运算符(搜索文档存储时就经常这样做)的用户可能会发现,如果“searchMode=all”能够告知布尔查询构造,则结果会更直观。 有关“searchMode”和运算符之间的交互的详细信息,请参阅 简单查询语法。
第 2 阶段:词法分析
构造查询树之后,词法分析器将处理字词查询和短语查询。 分析器接受分析器提供给它的文本输入,处理文本,并发回标记化的字词,以便在查询树中整合。
词法分析最常见的形式是 语言分析,它根据特定于给定语言的规则转换查询词。 这涉及:
- 将查询词减少到单词的根形式。
- 删除非必要词(停用词,如英语中的“the”或“and”)。
- 将复合词分解为组件部件。
- 将大写单词转换为小写。
所有这些操作往往会消除用户提供的文本输入与存储在索引中的字词之间的差异。 此类操作超出了文本处理的范围,需要精通语言本身。 为了添加这一层语言认知力,Azure AI 搜索支持 Lucene 和 Microsoft 提供的众多语言分析器。
注意
根据你的方案,分析要求的范围可能从最小到详细。 可以通过选择一个预定义的分析器或创建自己的 自定义分析器来控制词法分析的复杂性。 可将分析器的分析范围限定为可搜索的字段,并且可将分析器指定为字段定义的一部分。 这样,便可以根据每个字段运行不同的词法分析。 如果未指定,则使用 标准 Lucene 分析器。
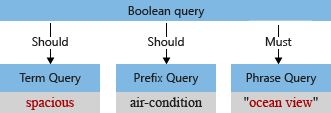
在本示例中,分析之前的初始查询树包含“Spacious,”一词,其中使用了大写的 S 以及一个逗号。查询分析程序会将逗号解释为查询字词的一部分(逗号不被视为查询语言运算符)。
当默认分析器处理术语时,它将小写“海洋视图”和“空间”,并删除逗号字符。 修改后的查询树如下所示:
测试分析器的行为
可以使用分析 API 测试分析器的行为。 提供要分析的文本以查看给定分析器生成的术语。 例如,若要查看标准分析器如何处理文本“air-condition”,可以发出以下请求:
{
"text": "air-condition",
"analyzer": "standard"
}
标准分析器会将输入文本分解成以下两个标记,使用起始和结束偏移(用于命中项突出显示)以及文本的位置(用于短语匹配)等属性来批注输入文本:
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
词法分析的例外情况
词法分析仅适用于需要完整术语的查询类型,无论是字词查询还是短语查询。 它不适用于包含不完整字词的查询类型(前缀查询、通配符查询和正则表达式查询)或模糊查询。 这些查询类型(包括示例中带有术语 air-condition* 的前缀查询)将直接添加到查询树中,绕过分析阶段。 针对这些类型的查询字词执行的唯一转换操作是转换为小写。
第 3 阶段:文档检索
文档检索是指在索引中查找与匹配词相符的文档。 此阶段最好通过一个示例来理解。 让我们从具有以下简单架构的酒店索引开始:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
进一步假设此索引包含以下四个文档:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
如何为术语编制索引
了解索引的一些基本知识有助于理解检索。 存储的单位是一个倒排索引,每个可搜索字段对应一个索引。 在倒排索引中,有一个来自所有文档的所有字词的排序列表。 每个字词映射到出现该字词的文档列表,以下示例清晰演示了这种映射。
要在倒排索引中生成字词,搜索引擎将针对文档内容执行词法分析,这类似于查询处理期间执行的操作:
- 文本输入将传递到分析器后再进行小写处理并去除标点符号等操作,具体取决于分析器的配置。
- 令牌是词法分析的输出。
- 将词语添加到索引。
我们经常(但不是非要这样做)使用相同的分析器来执行搜索和索引编制操作,使查询词看上去更像是索引中的字词。
注意
Azure AI 搜索允许通过附加的 indexAnalyzer 和 searchAnalyzer 字段参数来指定使用不同的分析器执行索引和搜索。 如果未指定,则使用通过analyzer属性设置的分析器用于索引编制和搜索。
用于示例文档的倒排索引
继续使用前面的示例,对于标题字段,倒排索引如下所示:
| 术语 | 文档列表 |
|---|---|
| atman | 1 |
| 海滩 | 2 |
| 酒店 | 1, 3 |
| 海洋 | 4 |
| playa | 3 |
| 度假村 | 2 |
| 撤退 | 4 |
在标题字段中,只有 酒店 显示在两个文档中:1 和 3。
对于 说明 字段,索引如下所示:
| 术语 | 文档列表 |
|---|---|
| 空气 | 3 |
| 和 | 4 |
| 海滩 | 1 |
| 已调节 | 3 |
| 舒适的 | 3 |
| 距离 | 1 |
| 岛 | 2 |
| kauaʻi | 2 |
| 位于 | 2 |
| 北 | 2 |
| 海洋 | 1, 2, 3 |
| 的 | 2 |
| on | 2 |
| 安静 | 4 |
| 房间 | 1, 3 |
| 僻静的 | 4 |
| 海岸 | 2 |
| 宽敞的 | 1 |
| the | 1, 2 |
| 到 | 1 |
| 视图 | 1, 2, 3 |
| 步行 | 1 |
| 替换为 | 3 |
匹配查询词与索引词
给定上面的倒排索引,让我们回到示例查询,了解如何为我们的示例查询找到匹配的文档。 回想一下,最终的查询树如下所示:
在查询执行过程中,会针对可搜索字段单独执行各个查询。
字词查询“spacious”匹配文档 1 (Hotel Atman)。
前缀查询“air-condition*”不匹配任何文档。
此行为有时会使开发人员感到困惑。 尽管 air-conditioned 一词在文档中存在,但它已被默认分析器拆分成两个词。 前面已经提到,不会分析包含部分字词的前缀查询。 因此,前缀为‘air-condition’的术语在倒排索引中查找时没有找到。
短语查询“ocean view”将在原始文档中查找字词“ocean”和“view”并检查字词的近似性。 文档 1、2 和 3 与说明字段中的此查询匹配。 请注意,文档 4 的标题中包含“ocean”一词,但不被视为匹配项,因为我们正在寻找“海洋视图”短语,而不是单个单词。
注意
除非使用 searchFields 参数限制了字段集(如示例搜索请求中所示),否则,将针对 Azure AI 搜索索引中的所有可搜索字段单独执行搜索查询。 将返回与任一选定字段匹配的文档。
总的来说,对于有问题的查询,匹配的文档为 1、2 和 3。
阶段 4:计分
将为搜索结果集中的每个文档分配一个相关性评分。 相关性评分的作用是提高能够为搜索查询所表示的用户问题提供最佳答案的文档的排名。 评分是根据匹配的字词的统计属性计算的。 评分公式的核心是术语频率反转文档频率。 在包含不常见和常见字词的查询中,TF/IDF 会提升包含不常见字词的结果。 例如,在包含所有 Wikipedia 文章的假想索引中,对于匹配查询 the president 的文档,匹配 president 的文档的相关性被视为高于匹配 the 的文档。
评分示例
回想一下与示例查询匹配的三个文档:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
文档 1 与查询的匹配程度最高,因为其说明字段中同时出现了字词 spacious 和所需的短语 ocean view。 后面的两个文档仅匹配词组 ocean view。 你可能会惊讶地发现,文档 2 和 3 的相关性分数不同,即使它们以相同的方式匹配查询。 这是因为评分公式的组件多于 TF/IDF。 在本例中,为文档 3 分配的评分略高,因为其说明更短。 请学习 Lucene 的实际评分公式,了解字段长度和其他因素如何影响相关性评分。
某些查询类型(通配符、前缀和正则表达式)始终为总体文档分数提供常量分数。 这允许通过查询扩展找到的匹配项包含在结果中,而不会影响排名。
一个示例说明了其中的重要性。 通配符搜索(包括前缀搜索)在定义中不明确,因为输入是一个部分字符串,其中包含大量不同字词的潜在匹配项。 考虑输入“tour*”,匹配项包括“tours”、“tourettes”和“tourmaline”。 由于这些结果的性质,我们无法合理推断出哪些字词的相关性高于其他字词。 因此,在对通配符、前缀和正则表达式的查询进行评分时,我们将忽略术语频率。 在包含不完整和完整字词的多部分搜索请求中,为避免对潜在的意外匹配产生偏见,来自不完整输入的结果将以固定评分形式合并。
相关性优化
在 Azure AI 搜索中,可以使用两种方法优化相关性评分:
评分配置文件可以根据一组规则提升结果排名列表中的文档。 在本示例中,我们可以认为标题字段中匹配的文档的相关性高于说明字段中匹配的文档。 此外,如果我们的指数对每个酒店都有价格字段,我们可以推广价格较低的文档。 详细了解如何将计分概要文件添加到搜索索引。
术语提升(只能在完整的 Lucene 查询语法中使用)提供了一个可应用于查询树任何部分的提升运算符
^。 在本示例中,我们可以不搜索前缀 air-condition*,而是搜索确切的字词 air-condition 或前缀,但是,由于在字词查询中应用了提升运算符,与该确切字词匹配的文档会获得更高的排名:air-condition^2||air-condition*。 详细了解查询中的字词增强。
在分布式索引中进行评分
Azure AI 搜索中的所有索引会自动拆分成多个分片,使我们能够在服务纵向扩展或纵向缩减期间,快速地在多个节点之间分配索引。 发出某个搜索请求时,会单独针对每个分片发出该请求。 然后,来自每个分片的结果会合并,并按评分排序(如果未定义其他排序)。 需要了解的是,评分函数会在该分片中所有文档内,将查询词频与其反向文档频率加权,而不是在所有分片中进行加权!
这意味着,如果相同的文档驻留在不同的分片中,其相关性评分可能不同。 幸运的是,随着索引中的文档数由于字词分布越来越均匀而不断增多,这种差异往往会消失。 无法假定任何给定文档将放置在哪个分片上。 但是,假设文档密钥不会更改,它始终分配给同一分片。
一般而言,如果顺序稳定性非常重要,则文档评分并不是用于文档排序的最佳属性。 例如,假设两个文档具有相同的评分,则无法保证以后运行同一个查询时,会先显示哪个文档。 文档评分只能让你大致了解某个文档的相关性相对于结果集中其他文档的高低程度。
结论
商业搜索引擎的成功提高了人们对在私有数据中运行全文搜索的预期。 对于几乎所有类型的搜索体验,我们现在都会预期引擎理解我们的意图,即使搜索词拼写不当或者不完整。 我们甚至预期可以根据近似的字词或者我们从未指定的同义词执行匹配。
从技术角度看,全文搜索非常复杂,需要采用高深的语言分析和系统性方法,通过提取、扩展和转换查询词进行处理并提供相关的结果。 考虑到固有的复杂性,有许多因素会影响查询的结果。 因此,在尝试处理意外结果时投入一些时间来了解全文搜索的机制可以获得实实在在的好处。
本文探讨了 Azure AI 搜索上下文中的全文搜索。 我们希望本文提供了足够的背景知识,可让你识别潜在的原因和解决常见的查询问题。
后续步骤
生成示例索引,试用不同的查询并查看结果。 有关说明,请参阅在 Azure 门户中生成和查询索引。
如需在搜索应用程序中优化排名,请查看评分模型。
应用 特定于语言的词法分析器。
配置自定义分析器,针对特定的字段尽量简化处理或者进行专门处理。