Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文是用于提高关键字搜索的查询和索引性能的提示及最佳做法的集合。 了解哪些因素最有可能影响搜索性能,有助于避免效率低下,充分利用搜索服务。 一些主要因素包括:
- 索引构成(架构和大小)
- 查询设计
- 服务容量(层,以及副本和分区的数量)
注意
您是否在寻找大规模索引的策略? 请参阅在 Azure AI 搜索中为大型数据集编制索引。
索引大小和架构
查询在小型索引上运行更快。 部分是由于要扫描的字段较少,这也与系统缓存内容以供将来查询的方式有关。 第一次查询后,某些内容将保留在内存中,以便更有效地搜索。 由于索引大小会随着时间的推移而不断增加,因此,最佳做法是定期重新访问索引构成(架构和文档),查找是否有缩减内容的机会。 不过,如果索引大小合适,那么唯一可进行的其他校准就是增加容量:添加副本或升级服务层。 “提示:切换到标准 S2 层”部分讨论了纵向扩展与横向扩展决策。
架构复杂性也会对索引和查询性能产生负面影响。 过多字段属性会产生更多的限制和处理要求。 复杂类型需要更长的时间来编制索引和查询。 接下来的几个部分将探讨每种情况。
提示:选择字段归属时要慎重
管理员和开发者在创建搜索索引时常犯的一个错误就是选择字段的所有可用属性,而不只是仅选择所需的属性。 例如,如果字段无需为全文可搜索,请在设置可搜索属性时跳过该字段。
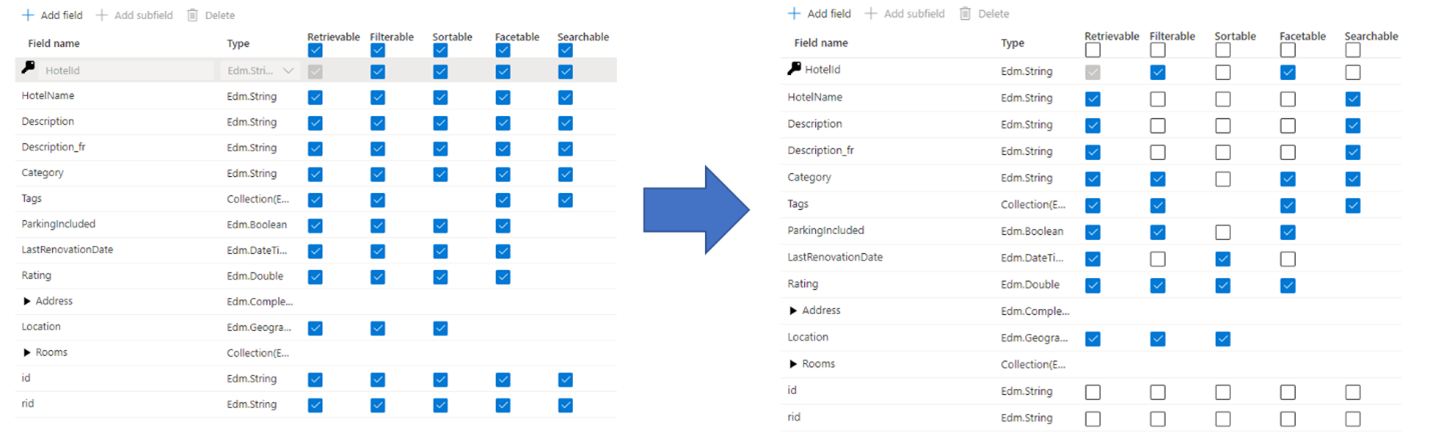
对筛选器、facet 和排序的支持可能会使存储要求增加了三倍。 如果添加建议器,存储要求还会更高。 有关属性对存储的影响的说明,请参阅属性和索引大小。
总之,过度归因的影响包括:
由于处理字段中的内容,然后将其存储在搜索倒排索引中需要额外的工作,导致索引性能下降(仅在包含可搜索内容的字段上设置“可搜索”属性)。
增加每个查询需要涵盖的表面积。 所有标记为可搜索的字段都在全文搜索中进行扫描。
由于额外的存储,增加了运营成本。 筛选和排序需要额外空间以存储原始(非分析)字符串。 在不需要筛选或排序的字段上,避免进行这些设置。
在许多情况下,过度归因会限制该领域的功能。 例如,如果字段是可查找、可筛选和可搜索的字段,则只能在一个字段中存储 16 KB 的文本,而可搜索字段最多可容纳 16 MB 的文本。
注意
避免不必要的字段属性,但不删除对搜索体验至关重要的功能。 筛选器和方面通常是核心功能,使用筛选时,通常需要排序才能生成有序结果。 仅当属性支持实际查询或 UI 要求时,才有意应用属性。
提示:考虑复杂类型的替代项
当数据具有复杂的嵌套结构(如 JSON 文档中的父子元素)时,复杂数据类型很有用。 与非复杂数据类型相比,复杂类型的缺点是对内容编制索引时需要额外的存储空间要求和资源。
在某些情况下,可以将复杂数据结构映射到更简单的字段类型(如“集合”)来避免这种折衷方案。 或者,你可选择将字段层次结构平展为单独的根级别字段。

查询设计
查询组合和复杂性是影响性能的最重要因素之一,查询优化可以显著提高性能。 设计查询时,请考虑以下几点:
可搜索字段的数目。 每个额外的可搜索字段都会为搜索服务带来更多工作量。 你可以使用“searchFields”参数限制在查询时搜索的字段。 最好仅指定重要的字段以提高性能。
要返回的数据量。 检索大量内容会使查询速度变慢。 构造查询时,只返回那些需要呈现结果页的字段,然后在用户选择匹配项后使用 Lookup API 检索其余字段。
使用部分术语搜索。与典型关键字搜索相比,部分术语搜索(如前缀搜索、模糊搜索和正则表达式搜索)的计算成本要高得多,因为它们需要完全索引扫描来生成结果。
Facet 的数量。 将多个 facet 添加到查询中需要对每个查询进行聚合。 要为构面请求更高的“计数”,则还需要服务完成额外的工作。 通常,只需要添加计划在应用程序中呈现的构面,除非必要,否则应避免为构面请求大量计数。
跳过值很高。 将
$skip参数设置为较高的值(例如,以千为单位)会增加搜索延迟,因为引擎将在为每个请求检索大量文档并进行排名。 出于性能原因,最好避免高$skip值并使用其他技术(例如筛选)来检索大量文档。限制高基数字段。 高基数字段是指一个可分面或可筛选的字段,具有大量独特值,因此在计算结果时会消耗大量资源。 例如,将“产品 ID”或“说明”字段设置为可分面和可筛选则视为高基数,因为大多数值在不同文档之间是唯一的。
提示:使用搜索函数而非重载筛选条件
由于查询越来越多地使用复杂的筛选条件,搜索查询的性能将会降低。 以下示例演示如何使用筛选器基于用户标识来剪裁结果:
$filter= userid eq 123 or userid eq 234 or userid eq 345 or userid eq 456 or userid eq 567
在本例中,筛选器表达式用于检查每个文档中的单个字段是否等于用户标识的多个可能值之一。 在实现安全剪裁(将包含一个或多个主体 ID 的字段与代表发出查询的用户的主体 ID 的列表进行对照检查)的应用程序中,此模式最常见。
执行包含大量值的筛选器的更有效方法是使用 search.in 函数,如以下示例中所示:
search.in(userid, '123,234,345,456,567', ',')
提示:为慢速单个查询添加分区
当查询性能速度总体变慢时,添加更多副本通常即可解决此问题。 但如果问题在于单个查询需要花费很长时间才能完成怎么办? 在这种情况下,添加副本将无济于事,但添加更多分区可能会有帮助。 分区在额外的计算资源之间拆分数据。 两个分区会将数据拆分为两半,三个分区会将数据拆分为三份,依此类推。
添加分区有一个正面的副作用,即速度较慢的查询有时会由于并行计算而变得更快。 我们注意到了在低选择性查询(例如匹配许多文档的查询,或分面提供大量文档计数的情况中)的并行化效果。 由于为文档相关性评分或统计文档数目需要消耗大量的计算资源,添加额外的分区有助于加快查询的完成速度。
若要添加分区,请使用 Azure 门户、 PowerShell、 Azure CLI 或管理 SDK。
服务容量
如果查询时间过长或者服务开始丢弃请求,则表示服务已经过载。 如果发生这种情况,可升级服务或添加容量来解决该问题。
搜索服务的层级和副本/分区数量也会对性能产生重大影响。 每个逐步提高的层级都会提供更快的 CPU 和更多的内存,这两者都会对性能产生积极的影响。
提示:创建新的高容量搜索服务
在 2024 年 4 月 3 日之后创建的基本服务和标准服务在受支持的区域中,每个分区的存储量比旧服务更大。 在升级到更高层和更高的计费费率之前,请重新访问层服务限制,看看较新服务的同一层能否提供所需的存储。
提示:切换到标准 S2 层
客户通常从标准 S1 搜索层开始使用。 S1 服务的常见模式是,索引会随时间而增加,便会需要更多的分区。 更多的分区会导致响应时间变慢,因此需添加更多的副本来处理查询负载。 正如你所设想的,运行 S1 服务的成本现在已经超出了初始配置的水平。
此时,要问的一个重要问题是,与逐步增加当前服务的分区或副本数量相比,切换到更高的定价层是否有益?
考虑以下拓扑作为服务的示例,该服务的容量级别在不断提高:
- 标准 S1 层
- 索引大小:190 GB
- 分区计数:8(在 S1 上,分区大小为每个分区 25 GB)
- 副本计数:2
- 总搜索单元:16(8 个分区 x 2 个副本)
假定服务管理员仍会看到较高的延迟,并考虑添加另一个副本。 这会将副本计数从 2 更改为 3,因此,搜索单位计数更改为 24。
但是,如果管理员选择移动到标准 S2 层,拓扑将如下所示:
- 标准 S2 层级
- 索引大小:190 GB
- 分区计数:2(在 S2 上,分区大小为每个分区 100 GB)
- 副本计数:2
- 总搜索单元:4(2 个分区 x 2 个副本)
正如此假设的方案所示,你可以在较低层上进行配置,从而产生与最初选择较高层时相似的成本。 但是,更高的层提供高级存储,使编制索引速度更快。 更高层还具有更多的计算能力和额外的内存。 对于相同的成本,你可以拥有更强大的基础架构来支持相同的索引。
添加内存的一个重要好处是,可以缓存更多的索引,从而降低搜索延迟,并增加每秒的查询数。 借助这种额外的功能,管理员甚至无需增加副本数量,并且支付的费用可能低于继续使用 S1 服务。
提示:考虑正则表达式查询的替代方法
正则表达式查询或简称为正则表达式(regex)可能会非常耗费资源。 虽然它们可能对于高级搜索非常有用,但执行可能需要大量的处理能力,尤其是当正则表达式很复杂或者要搜索大量数据时。 所有这些因素都会导致高搜索延迟。 作为缓解措施,请尝试简化正则表达式或将复杂查询分解为更小、更易于管理的查询。
后续步骤
查看以下与服务性能有关的其他文章: