Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文介绍:
- 可以为此服务收集的监视数据的类型。
- 如何分析这些数据。
如果具有依赖于 Azure 资源的关键应用程序和业务流程,则需要监视并获取系统的警报。 Azure Monitor 服务会从系统的每个组件收集并聚合指标和日志。 Azure Monitor 提供可用性、性能和复原能力视图,并在出现问题时向你发送通知。 可以使用 Azure 门户、PowerShell、Azure CLI、REST API 或客户端库来设置和查看监视数据。
- 有关 Azure Monitor 的详细信息,请参阅 Azure Monitor 概述。
- 有关监视 Azure 资源的常规方法的详细信息,请参阅使用 Azure Monitor 监视 Azure 资源。
警告
不再支持用于 Service Fabric SDK 的 Application Insights。
Azure Service Fabric 监视
Azure Service Fabric 具有以下可以监视的层:
- 应用程序监视:节点上运行的应用程序。 可以使用 Application Insights 密钥或 SDK、EventStore 或 ASP.NET Core 日志记录来监视应用程序。
- 平台(群集)监视:平台或群集节点(包括容器指标)的客户端指标、日志和事件。 Linux 或 Windows 节点的指标和日志不同。
- 基础结构(性能)监视:服务运行状况和性能计数器基础结构。
可以监视应用程序的使用方式、Service Fabric 平台所采取的操作、带性能计数器的资源利用率以及群集的总体运行状况。 Azure Monitor 日志和 Application Insights 提供与 Service Fabric 的内置集成。
- 若要了解最佳做法,请参阅 Azure Service Fabric 的监视和诊断最佳做法。
- 有关如何查看 Service Fabric 事件和运行状况报告、查询 EventStore API 和监视性能计数器的教程,请参阅教程:在 Azure 中监视 Service Fabric 群集。
Service Fabric Explorer
Service Fabric Explorer 是一款适用于 Windows、macOS 和 Linux 的桌面应用程序,并且是一种用于检验和管理 Azure Service Fabric 群集的开源工具。 若要实现自动化,可以通过 Service Fabric Explorer 执行的每个操作也可以通过 PowerShell 或 REST API 执行。
应用程序监视
应用程序监视跟踪应用程序的功能和组件的使用方式。 监视应用程序可以确保捕获影响用户的问题。 应用程序监视主要负责用户开发应用程序及其服务,因为它对应用程序的业务逻辑是唯一的。 监视应用程序可能对以下情况有帮助:
- 应用程序遇到了多少流量? - 是否需要缩放服务来满足用户需求,或解决应用程序中的潜在瓶颈?
- 服务到服务调用是否成功并已进行跟踪?
- 应用程序的用户执行哪些操作? - 收集遥测可指导将来的功能开发和更好地诊断应用程序错误
- 应用程序正在引发未经处理的异常?
- 容器内运行的服务中发生了什么情况?
由于应用程序监视位于应用程序的上下文中,因此其最大的优点在于,开发人员可以使用他们喜欢的任意工具和框架! 可以在使用 Application Insights 进行事件分析中了解有关使用 Azure Monitor Application Insights 进行应用程序监视的 Azure 解决方案的更多信息。
我们还提供了介绍如何为 .NET应用程序设置此监视的教程。 本教程介绍如何安装正确的工具、在应用程序中编写自定义遥测的示例以及在 Azure 门户中查看应用程序诊断和遥测。
应用程序日志记录
检测代码不仅是获取用户见解的一种方式,也是了解应用程序中是否存在问题以及诊断需要修复的内容的唯一方法。 尽管在技术上可将调试器连接到生产服务,但这种做法并不常见。 因此,提供详细的检测数据非常重要。
某些产品可自动检测代码。 尽管这些解决方案能够正常运行,但针对业务逻辑,几乎始终都要执行手动检测。 最后,必须提供足够的信息来对应用程序进行取证式的调试。 Service Fabric 应用程序可以使用任何记录框架进行检测。 本部分将介绍几种用于检测代码的不同方法,并说明何时应该在不同的方法之间做出选择。
Application Insights SDK:Application Insights 具有现成的与 Service Fabric 的丰富集成。 用户可以添加 AI Service Fabric nuget 包并接收可以在 Azure 门户中查看的已创建和收集的数据和日志。 另外,建议用户添加其自己的遥测数据,以便诊断和调试其应用程序并跟踪哪些服务及其应用程序的哪些部分使用得最多。 该 SDK 中的 TelemetryClient 类提供了许多方式来用于在应用程序中跟踪遥测数据。 有关详细信息,请参阅使用 Application Insights 进行事件分析和可视化。
请在我们提供的有关监视和诊断 .NET 应用程序的教程中查看有关如何进行检测以及向应用程序添加 Application Insights 的示例。
EventSource:在 Visual Studio 中通过模板创建 Service Fabric 解决方案时,将生成 EventSource 派生类(ServiceEventSource 或 ActorEventSource)。 会创建一个模板,可将应用程序或服务的事件添加到其中。 EventSource 名称必须唯一,应该将它重命名,不要使用默认的模板字符串 MyCompany-solution-<project>。 使用多个同名的 EventSource 定义会导致运行时出现问题。 每个定义的事件必须具有唯一标识符。 如果标识符不唯一,将发生运行时失败。 某些组织为标识符预先分配了值范围,避免不同的开发团队之间发生冲突。 有关详细信息,请参阅 Vance 的博客或 MSDN 文档。
ASP.NET Core 日志记录:必须认真规划如何检测代码。 适当的检测计划有助于避免代码基变得不稳定,从而需要重新检测代码。 为了降低风险,可以选择一个检测库,例如,Azure ASP.NET Core 中包含的 Microsoft.Extensions.Logging。 ASP.NET Core 提供一个可在所选提供程序中使用的 ILogger 接口,同时尽量减轻对现有代码的影响。 可以在 Windows 和 Linux 上的 ASP.NET Core 中以及整个 .NET Framework 中使用代码,从而将检测代码标准化。
有关如何使用这些建议的示例,请参阅向 Service Fabric 应用程序添加日志记录。
平台(群集)监视
由于用户自己编写代码,用户可以控制来自其应用程序的遥测,但是来自 Service Fabric 平台的诊断怎么办? Service Fabric 的目标之一是确保应用程序能够灵活应对硬件故障。 为了实现此目的,可以通过平台的系统服务功能检测基础结构问题,并快速将工作负荷故障转移到群集中的其他节点。 但在此特殊情况下,系统服务本身出现问题该怎么办? 或者,在尝试部署或移动工作负荷时,如果违反服务位置的规则该怎么办? Service Fabric 为这些以及更多内容提供诊断,以确保你了解群集中发生的活动。 群集监视的一些示例场景包括:
有关平台(群集)监视的详细信息,请参阅监视群集。
Service Fabric 事件
Service Fabric 提供了一组全面、现成可用的诊断事件,可以通过 EventStore 或平台公开的操作事件通道进行访问。 这些 Service Fabric 事件说明了平台在节点、应用程序、服务和分区等不同实体上执行的操作。 Windows 和 Linux 群集上都有相同的事件。
Service Fabric 事件通道:在 Windows 上,Service Fabric 事件可从单个 ETW 提供程序获取,其中包含一组相关的
logLevelKeywordFilters,用于在操作通道和数据和消息传送通道之间进行选取。 这就是我们根据需要筛选传出 Service Fabric 事件的方式。 在 Linux 中,Service Fabric 事件通过 LTTng 传入一个存储表中,可在其中按需筛选事件。 这些通道包含组织有序的结构化事件用于更好地了解群集的状态。 创建群集时默认会启用“诊断”并创建一个 Azure 存储表,来自这些通道的事件将发送到其中,方便将来进行查询。EventStore 是一项功能,它通过 Service Fabric 客户端库 REST API 在 Service Fabric Explorer 中以编程方式显示 Service Fabric 平台事件。 可以查看群集中每个节点、服务和应用程序的快照视图,以及基于事件时间的查询。 EventStore API 仅适用于在 Azure 上运行的 Windows 群集。 在 Windows 计算机上,这些事件被传输到 EventLog,以便你能够在事件查看器中查看 Service Fabric 事件。
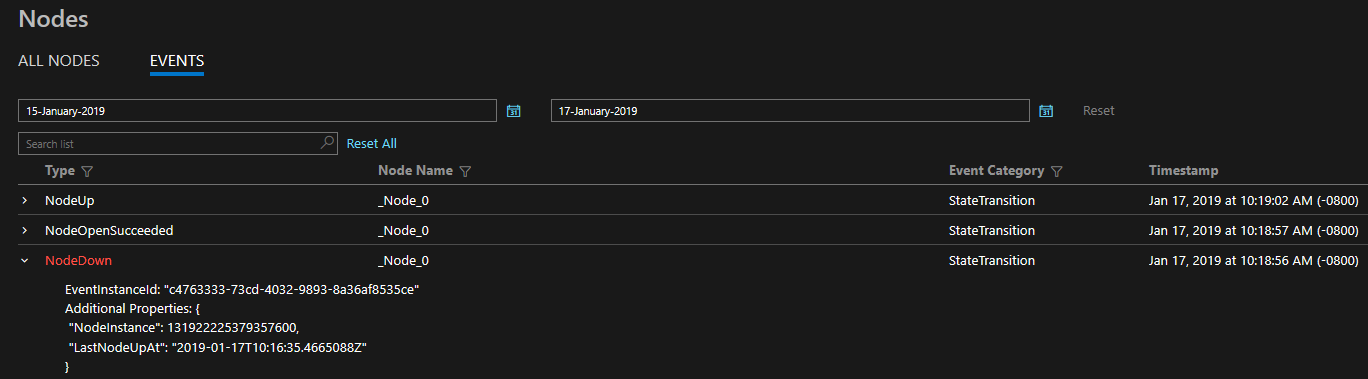
诊断以一系列现成的全面的事件集的形式提供。 这些 Service Fabric 事件说明了平台在节点、应用程序、服务、分区等不同实体上执行的操作。在上述最后一个场景中,如果节点发生故障,平台将发出 NodeDown 事件,可以立即通过所选的监控工具通知你。 故障转移期间,其他常见示例包括 ApplicationUpgradeRollbackStarted 或 PartitionReconfigured。
Windows 和 Linux 群集上都有相同的事件。
事件通过 Windows 和 Linux 上的标准通道发送,并且可以由任何支持这些事件的监视工具读取。 Azure Monitor 解决方案是 Azure Monitor 日志。 请随时阅读有关 Azure Monitor 日志集成的更多信息,其中包括针对群集的自定义操作仪表板,以及可以从中创建警报的一些示例查询。 平台级别事件和日志生成提供了更多群集监视概念。
运行状况监视
Service Fabric 平台包含运行状况模型,针对群集中的实体状态提供可扩展的运行状况报告。 每个节点、应用程序、服务、分区、副本或实例都具有持续可更新的运行状况。 运行状况可能是“正常”、“警告”或“错误”。 将 Service Fabric 事件视为群集对各种实体所做的动词,将运行状况视为每个实体的形容词。 每次特定实体的运行状况转换时,也会发出事件。 这样,就可以在所选监视工具中为运行状况事件设置查询和警报,就像任何其他事件一样。
此外,我们甚至允许用户重写实体的运行状况。 如果应用程序正在进行升级且验证测试失败,则可以使用运行状况 API 写入 Service Fabric 运行状况,以指示应用程序未正常运行,并且 Service Fabric 将自动回滚升级! 有关运行状况模型的详细信息,请参阅 Service Fabric 运行状况监视简介
监视器
监视器通常是一个独立的服务,用于监视各个服务的运行状况和负载、ping 终结点,以及报告群集中的异常运行状况事件。 这有助于防止出现仅基于单个服务的性能所检测不到的错误。 监视器也是一个托管代码的好选择,无需用户交互即可执行补救措施,例如每隔特定时间就清理一次存储中的日志文件。 如果需要完全实现的开源 SF 监视服务,其中包括易于使用的监视器可扩展性模型,同时在 Windows 和 Linux 群集中都能运行,请参阅 FabricObserver 项目。 FabricObserver 是生产就绪软件。 建议将 FabricObserver 部署到测试和生产群集,并通过其插件模型或者通过分支并编写自己的内置观察器对其扩展,以满足你的需求。 建议采用前一种(插件)方法。
基础结构(性能)监视
既然我们已介绍了应用程序和平台中的诊断,那么如何知道硬件按预期方式正常运行? 监视底层基础结构是了解群集状态和资源利用率的重要组成部分。 测量系统性能取决于多种因素,主观上取决于工作负荷。 这些因素通常通过性能计数器来衡量。 这些性能计数器可以来自各种来源,包括操作系统、.NET Framework 或 Service Fabric 平台本身。 在某些情况下,它们将是有用的
- 能否有效地利用硬件? 是否要以 90% 的 CPU 使用率或 10% 的 CPU 使用率使用硬件。 这在扩展群集或优化应用程序进程时非常方便。
- 是否可以主动预测基础结构问题? - 许多问题在发生之前,都会出现性能骤然发生变化(下降)的前兆,因此,可以使用网络 I/O 和 CPU 利用率等性能计数器来主动预测和诊断问题。
可以在性能指标中找到应在基础结构级别收集的性能计数器列表。
若要监视群集级别的事件,建议使用 Azure Monitor 日志。 使用工作区配置 Log Analytics 代理后,可以收集:
- 性能指标,例如 CPU 使用率。
- .NET 性能计数器,例如进程级别 CPU 利用率。
- Service Fabric 性能计数器,例如可靠服务中的异常数。
- 容器指标,例如 CPU 使用率。
资源类型
Azure 使用资源类型和 ID 的概念来标识订阅中的所有内容。 同样的,Azure Monitor 根据资源类型(也称为“命名空间”)将核心监视数据组织为指标和日志。 不同的指标和日志可用于不同的资源类型。 服务可能与多种资源类型关联。
资源类型也是 Azure 中运行的每个资源的资源 ID 的一部分。 例如,虚拟机的一种资源类型是 Microsoft.Compute/virtualMachines。 有关服务及其关联资源类型的列表,请参阅资源提供程序。
有关 Azure Service Fabric 的资源类型的详细信息,请参阅 Service Fabric 监视数据参考。
数据存储
对于 Azure Monitor:
- 指标数据存储在 Azure Monitor 指标数据库中。
- 日志数据存储在 Azure Monitor 日志存储中。 Log Analytics 是 Azure 门户中可以查询此存储的工具。
- Azure 活动日志是一个单独的存储区,在 Azure 门户中有自己的接口。
- 可选择将指标和活动日志数据路由到 Azure Monitor 日志数据库存储,以便可使用 Log Analytics 查询数据并将其与其他日志数据关联。
有关 Azure Monitor 如何存储数据的详细信息,请参阅 Azure Monitor 数据平台。
Azure Monitor 平台指标
Azure Monitor 为许多服务提供平台指标。 有关可以为 Azure Monitor 中的所有资源收集的所有指标的列表,请参阅 Azure Monitor 中支持的指标。
此服务不会收集平台指标。
基于非 Azure Monitor 的指标
此服务提供 Azure Monitor 指标数据库中不包含的其他指标。
来宾 OS 指标
在 Service Fabric 群集节点上运行的来宾操作系统 (OS) 的指标必须通过在来宾 OS 上运行的一个或多个代理进行收集。 来宾 OS 指标包括性能计数器,该性能计数器跟踪来宾 CPU 百分比或内存使用率,这两者经常用于自动缩放或警报功能。
最佳做法是使用并配置 Azure Monitor 代理,以便通过自定义指标 API 将来宾 OS 性能指标发送到 Azure Monitor 指标数据库。 可以使用相同的代理将来宾 OS 指标发送到 Azure Monitor 日志。 然后,可以使用 Log Analytics 查询这些指标和日志。
注意
Azure Monitor 代理取代了用于来宾 OS 路由的 Azure 诊断扩展和 Log Analytics 代理。 有关详细信息,请参阅 Azure Monitor 代理概述。
资源日志
借助资源日志,可以深入了解 Azure 资源已执行的操作。 日志是自动生成的,但必须将日志路由到 Azure Monitor 日志以保存或查询它们。 日志按类别组织。 给定的命名空间可以有多个可供收集的资源日志类别。
此服务不会收集资源日志,但可以在“监视 Azure 资源中的数据”中找到相关信息。
Service Fabric 日志和事件
Service Fabric 可以收集以下日志:
- 对于 Windows 群集,可以使用诊断代理和 Azure Monitor 日志来设置群集监视。
- 对于 Linux 群集,Azure Monitor 日志也是建议用于 Azure 平台和基础结构监视的工具。 Linux 平台诊断需要不同的配置。 有关详细信息,请参阅 Syslog 中的 Service Fabric Linux 群集事件。
- 可以将 Azure Monitor 代理配置为将来宾 OS 日志发送到 Azure Monitor 日志,你可以从中使用 Log Analytics 对其进行查询。
- 可以将 Service Fabric 容器日志写入 stdout 或 stderr,使之在 Azure Monitor 日志中可用。
其他日志记录解决方案
尽管我们推荐的两个解决方案(Azure Monitor 日志和 Application Insights)以内置方式集成了 Service Fabric,但许多事件会通过 ETW 提供程序写出,并且可随其他日志记录解决方案一起扩展。 此外,还应考虑 Elastic Stack(尤其是考虑在脱机环境中运行群集时)、Dynatrace 或其他任何偏好的平台。 有关集成合作伙伴的列表,请参阅 Azure Service Fabric 监视合作伙伴。
选择任何平台时都应考虑的关键点包括:用户界面的舒适度、查询功能的舒适度、可用的自定义可视化效果和仪表板、平台提供的用于增强监视体验的其他工具。
Azure 活动日志
活动日志包含订阅级事件,这些事件跟踪从资源外部看到的每个 Azure 资源的操作;例如,创建新资源或启动虚拟机。
收集:活动日志事件会自动生成并收集在单独的存储中,以便在 Azure 门户中查看。
路由:可将活动日志数据发送到 Azure Monitor 日志,以便可以将它们与其他日志数据一起进行分析。 其他位置(例如 Azure 存储、Azure 事件中心和某些 Azure 监视合作伙伴)也可用。 有关如何路由活动日志的详细信息,请参阅 Azure 活动日志概述。
分析监视数据
有许多工具可用于分析监视数据。
Azure Monitor 工具
Azure Monitor 支持以下基本工具:
指标资源管理器,它是 Azure 门户中的工具,可用于查看和分析 Azure 资源的指标。 有关详细信息,请参阅使用 Azure Monitor 指标资源管理器分析指标。
Log Analytics,它是 Azure 门户中的一种工具,支持使用 Kusto 查询语言 (KQL) 来查询和分析日志数据。 有关详细信息,请参阅 Azure Monitor 日志查询入门。
活动日志,它在 Azure 门户中具有用于执行查看和基本搜索的用户界面。 要进行更深入的分析,必须将数据路由到 Azure Monitor 日志,并在 Log Analytics 中运行更复杂的查询。
支持更复杂可视化效果的工具包括:
- 仪表板,它支持将不同类型的数据合并到 Azure 门户的单个窗格中。
- 工作簿,它们是可在 Azure 门户中创建的可自定义报表。 工作簿可以包括文本、指标和日志查询。
- Power BI,它是一项业务分析服务,可提供跨各种数据源的交互式可视化效果。 可将 Power BI 配置为自动从 Azure Monitor 导入日志数据,以利用这些可视化效果。
有关常见 Service Fabric 监视分析场景的概述,请参阅使用 Service Fabric 诊断常见情况。
Azure Monitor 导出工具
可以使用以下方法将数据从 Azure Monitor 中提取到其他工具中:
指标:使用适用于指标的 REST API 从 Azure Monitor 指标数据库提取指标数据。 API 支持使用筛选表达式优化检索到的数据。 有关详细信息,请参阅 Azure Monitor REST API 参考。
日志:使用 REST API 或关联的客户端库。
要开始使用适用于 Azure Monitor 的 REST API,请参阅 Azure 监视 REST API 演练。
Kusto 查询
可使用 Kusto 查询语言 (KQL) 来分析 Azure Monitor 日志/Log Analytics 存储中的监视数据。
重要
在门户的服务菜单中选择“日志”时,会打开 Log Analytics,并且其查询范围设置为当前服务。 此范围意味着日志查询将仅包含来自该资源类型的数据。 如果希望运行的查询包含来自其他 Azure 服务的数据,请从“Azure Monitor”菜单中选择“日志”。 有关详细信息,请参阅 Azure Monitor Log Analytics 中的日志查询范围和时间范围。
有关任何服务的常见查询的列表,请参阅 Log Analytics 查询界面。
示例查询
以下查询返回 Service Fabric 事件,包括对节点执行的操作。 有关其他有用的查询,请参阅 Service Fabric 事件。
返回过去一小时内记录的操作事件:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
返回 HealthState == 3(错误)的运行状况报告,并从 EventMessage 字段中提取更多属性:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
获取与特定服务和节点聚合的 Service Fabric 操作事件:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
警报
在监视数据中发现特定情况时,Azure Monitor 警报会主动向你发出通知。 有了警报,你就可以在客户注意到你的系统中的问题之前找出和解决问题。 有关详细信息,请参阅 Azure Monitor 警报。
Azure 资源的常见警报具有许多来源。 有关 Azure 资源常见警报的示例,请参阅示例日志警报查询。 Azure Monitor 基线警报 (AMBA) 站点提供了 Azure 登陆区域 (ALZ) 方案的关键警报指标、仪表板和指南。
通用警报模式对 Azure Monitor 警报通知的使用体验进行了标准化。 有关详细信息,请参阅常见警报架构。
警报类型
可以针对 Azure Monitor 数据平台中的任何指标或日志数据源发出警报。 警报具有许多不同类型,具体取决于要监视的服务以及要收集的监视数据。 不同类型的警报各有优缺点。 有关详细信息,请参阅选择正确的监视警报类型。
以下列表介绍了可以创建的 Azure Monitor 警报类型:
- 指标警报会定期评估资源指标。 指标可以是平台指标、自定义指标、Azure Monitor 中的日志转换为的指标或 Application Insights 指标。 指标警报还可以应用多个条件和动态阈值。
- 日志警报支持用户使用 Log Analytics 查询按照预定义的频率评估资源日志。
- 当发生匹配所定义条件的新活动日志事件时,会触发活动日志警报。 资源运行状况警报和服务运行状况警报是报告服务和资源运行状况的活动日志警报。
还可以为某些 Azure 服务创建以下类型的警报:
- Application Insights 资源上的智能检测警报会就 Web 应用程序中的潜在性能问题和故障异常自动向你发出警报。 可以在 Application Insights 资源上迁移智能检测,以便为不同的智能检测模块创建警报规则。
- Prometheus 警报:针对 Prometheus 指标的警报,这些指标存储在适用于 Prometheus 的 Azure Monitor 托管服务中。 该警报规则基于 PromQL,它是一种开源查询语言。 你的服务可能不支持此类型警报。 目前,Prometheus 用于具有来宾操作系统的有限服务集,例如 Azure 虚拟机和 Azure 容器实例。
- 对于某些 Azure 资源(包括虚拟机、Azure Kubernetes 服务 [AKS] 资源和 Log Analytics 工作区),提供了现成可用的建议警报规则。
监视多个资源
通过将相同的指标警报规则应用于同一 Azure 区域中的多个相同类型资源,可以进行大规模的监视。 将为每个受监视的资源发送单独通知。 有关受支持的 Azure 服务和云,请参阅使用一项警报规则监视多个资源。
Service Fabric 警报规则
下表列出了 Service Fabric 的一些警报规则。 这些警报只是示例。 可以为 Service Fabric 监视数据参考或 Service Fabric 事件列表中列出的任何指标、日志条目或活动日志条目设置警报。
| 警报类型 | 条件 | 说明 |
|---|---|---|
| 节点事件 | 节点关闭 | ServiceFabricOperationalEvent,其中 EventID >= 25622,EventID <= 25626。 这些事件 ID 位于节点事件参考中。 |
| 应用程序事件 | 应用程序升级回滚 | ServiceFabricOperationalEvent,其中 EventID == 29623 或 EventID == 29624。 这些事件 ID 位于应用程序事件参考中。 |
| 资源运行状况 | 升级服务不可访问/不可用 | 群集进入 UpgradeServiceUnreachable 状态。 |
顾问建议
如果在资源操作期间出现严重情况或即将发生变化,则门户中的“概述”页面上会显示一个警报。
可以在“监视”下的“顾问建议”中找到警报的详细信息和建议补丁。 在正常操作期间,不会显示任何顾问建议。
有关 Azure 顾问的详细信息,请参阅 Azure 顾问概述。
建议的设置
现已了解监视和示例场景的每个区域,以下是 Azure 监视工具的摘要以及监视上述所有区域所需的设置。
- 使用 Application Insights 监视的应用程序
- 使用诊断代理和 Azure Monitor 日志监视的群集
- 使用 Azure Monitor 日志进行基础结构监视
此外,还可使用并修改示例 ARM 模板以自动部署所有必要的资源和代理。
相关内容
- 有关为 Service Fabric 创建的指标、日志和其他重要值的参考,请参阅 Service Fabric 监视数据参考。
- 有关监视 Azure 资源的一般详细信息,请参阅使用 Azure Monitor 监视 Azure 资源。
- 请参阅 Service Fabric 事件列表。