Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
查询加速使应用程序和分析框架可以通过仅检索执行给定操作所需的数据来大幅优化数据处理。 这减少了获取对存储数据的关键见解所需的时间和处理能力。
概述
查询加速接受筛选谓词和列投影,使应用程序能够在从磁盘读取数据时筛选行和列。 只有满足谓词条件的数据才会通过网络传输到应用程序。 这会减少网络延迟和计算成本。
可以使用 SQL 来指定查询加速请求中的行筛选器谓词和列投影。 一个请求仅处理一个文件。 因此,不支持 SQL 的高级关系功能(例如加入和按聚合分组)。 查询加速支持将 CSV 和 JSON 格式的数据作为每个请求的输入。
查询加速功能并不局限于 Data Lake Storage(启用了分层命名空间的存储帐户)。 查询加速与未在其上启用分层命名空间的存储帐户中的 Blob 兼容。 这意味着,当你处理已作为 blob 存储在存储帐户中的数据时,同样可以减少网络延迟和计算成本。
有关如何在客户端应用程序中使用查询加速的示例,请参阅使用 Azure Data Lake Storage 查询加速来筛选数据。
数据流
下图说明了典型应用程序如何使用查询加速来处理数据。
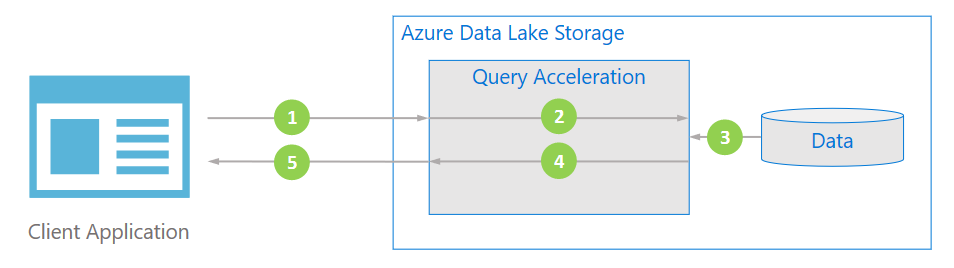
客户端应用程序通过指定谓词和列投影来请求文件数据。
查询加速分析指定的 SQL 查询并分发工作以分析和筛选数据。
处理器从磁盘读取数据,使用适当的格式分析数据,然后通过应用指定的谓词和列投影来筛选数据。
查询加速合并响应分片以流式传输回客户端应用程序。
客户端应用程序接收并分析流式传输的响应。 应用程序无需筛选任何其他数据,并且可以直接应用所需的计算或转换。
提高性能并降低成本
查询加速通过减少应用程序传输和处理的数据量来优化性能。
为了计算聚合值,应用程序通常会检索文件中的“所有”数据,然后在本地处理并筛选这些数据。 对分析工作负载的输入/输出模式进行的分析显示,应用程序通常只需要其读取的数据的 20% 即可执行任何给定计算。 即使在应用分区修剪等技术后,此统计信息也是正确的。 这意味着,80% 的数据在网络上进行不必要的传输,并由应用程序进行不必要的分析和筛选。 此模式旨在删除不需要的数据,但会产生大量的计算成本。
即使 Azure 具有业界领先的网络(在吞吐量和延迟方面),通过该网络进行不必要的数据传输对应用程序性能而言仍然是昂贵的。 通过在存储请求期间筛选掉不需要的数据,查询加速消除了这一成本。
此外,分析和筛选不需要的数据所需的 CPU 负载要求你的应用程序预配更多更大的 VM,以便完成其工作。 将此计算负载转移到查询加速后,应用程序可以显著节省成本。
可从查询加速中受益的应用程序
查询加速设计用于分布式分析框架和数据处理应用程序。
分布式分析框架(如 Apache Spark 和 Apache Hive)包括框架中的存储抽象层。 这些引擎还包括查询优化器,可以在为用户查询确定最佳查询计划时纳入基础 I/O 服务功能的知识。 这些框架正在开始集成查询加速。 因此,这些框架的用户将看到降低的查询延迟和更低的总拥有成本,而无需对查询进行任何更改。
查询加速还适用于数据处理应用程序。 这些类型的应用程序通常执行可能不会直接产生分析见解的大规模数据转换,因此它们不会始终使用已建立的分布式分析框架。 这些应用程序通常与基础存储服务具有更直接的关系,因此它们可以直接受益于查询加速等功能。
有关应用程序如何集成查询加速的示例,请参阅使用 Azure Data Lake Storage 查询加速来筛选数据。
定价
由于 Azure Data Lake Storage 服务中增加了计算负载,因此用于使用查询加速的定价模型不同于正常的 Azure Data Lake Storage 事务模型。 查询加速对扫描的数据量以及返回给调用方的数据量收费。 有关详细信息,请参阅 Azure Data Lake Storage 定价。
尽管对计费模型进行了更改,但查询加速的定价模型旨在降低工作负荷的总拥有成本,因为降低了更昂贵的 VM 成本。