Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure 门户中的物理作业关系图可帮助你使用流节点以关系图或表格格式可视化作业的关键指标,例如:CPU 利用率、内存利用率、输入事件、分区 ID 和水印延迟。 它可以帮助你在排查问题时确定问题的原因。
本文演示如何在 Azure 门户中使用物理作业关系图分析作业的性能并快速识别其瓶颈。
重要
此功能目前处于预览状态。 有关 beta 版本、预览版或尚未正式发布的版本的 Azure 功能所适用的法律条款,请参阅 Azure 预览版的补充使用条款。
识别作业的并行度
具有并行化的作业是流分析中可以提供更好性能的可缩放方案。 如果作业不处于并行模式,则其性能很可能会出现某种瓶颈。 确定作业是否处于并行模式非常重要。 物理作业关系图提供一个视觉图形来展示作业并行度。 在物理作业关系图中,如果不同的流节点之间存在数据交互,则该作业是需要更多关注的非并行作业。 下面是非并行作业关系图的示例:

可以考虑通过重新编写查询或使用 Azure 门户中的查询编辑器更新输入/输出配置,来为并行作业优化查询(如以下示例所示)。

用于识别并行作业瓶颈的关键指标
水印延迟和积压输入事件是确定流分析作业性能的关键指标。 如果作业的水印延迟持续增加,并且输入事件积压,则意味着作业无法跟上输入事件的速率并及时生成输出。 从计算资源的角度看,当发生这种情况时,会大量使用 CPU 和内存资源。
物理作业关系图将这些关键指标一起可视化,为你提供它们的整体视图,以方便识别瓶颈。

有关指标定义的详细信息,请参阅 Azure 流分析节点名称维度。
识别不均匀分布的输入事件(数据倾斜)
如果作业已在并行模式下运行,但你观察到高水印延迟,请使用此方法确定原因。
若要找出根本原因,请在 Azure 门户中打开物理作业关系图。 选择“监视”下的“作业关系图(预览版)”,然后切换到“物理关系图”。
在物理关系图中,可以通过查看每个节点中的水印延迟值或选择水印延迟热度地图设置对流节点进行排序(建议方法),来轻松确定是所有分区还是其中的少数分区存在高水印延迟:

应用上面做出的热度地图设置后,左上角会显示存在高水印延迟的流节点。 然后,你可以检查相应流节点收到的输入事件数是否比其他节点要多得多。 对于此示例,streamingnode#0 和 streamingnode#1 收到的输入事件数较多。

可以进一步检查单独为流节点分配了多少分区,以确定更多的输入事件是由于分配了更多分区造成的,还是由于任何特定分区收到了更多输入事件造成的。 对于此示例,所有流节点都有两个分区。 这意味着,streamingnode#0 和 streamingnode#1 中的某个特定分区包含的输入事件数比其他分区更多。
若要在 streamingnode#0 和 streamingnode#1 中找出收到的输入事件数比其他分区更多的分区,请执行以下步骤:
- 在图表部分选择“添加图表”
- 将“输入事件”添加到指标中,将“分区 ID”添加到拆分器中
- 选择“应用”以显示输入事件图表
- 在关系图中勾选“streamingnode#0”和“streamingnode#1”
将看到以下图表,其中包含按两个流节点中的分区筛选的输入事件指标。

可以进一步采取哪些操作?
如示例中所示,分区(0 和 1)的输入数据比其他分区更多。 这种情况称之为“数据倾斜”。 处理出现数据倾斜分区的流节点需要消耗的 CPU 和内存资源比其他节点更多。 这种不平衡会导致性能变慢并增大水印延迟。 还可以在物理关系图中检查两个流节点中的 CPU 和内存使用率。 若要缓解问题,需要更均匀地将输入数据重新分区。
识别 CPU 或内存过载的原因
如果并行作业的水印延迟增大,但未出现前面所述的数据倾斜情况,则原因可能是所有流节点上存在大量数据,从而抑制了性能。 可以使用物理关系图来确定作业是否存在这种特征。
打开物理作业关系图,转到作业 Azure 门户中的“监视”,选择“作业关系图(预览版)”,然后切换到“物理关系图”。 你将看到加载的物理关系图,如下所示。
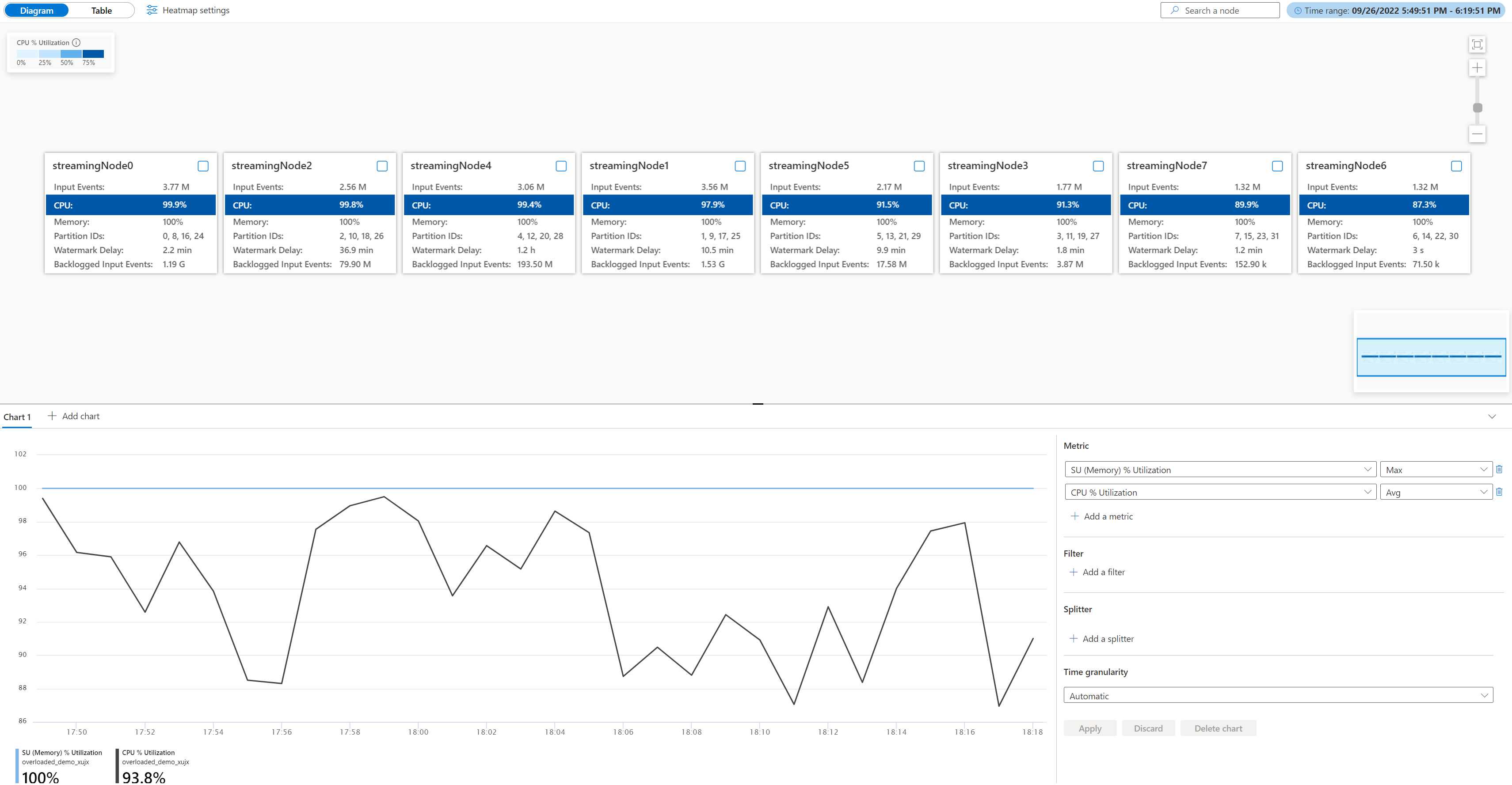
检查每个流节点中的 CPU 和内存利用率,以确定所有流节点中的利用率是否过高。 如果所有流节点中的 CPU 和 SU 利用率过高(超过 80%),则可以确认此作业在每个流节点中处理大量数据。
从上面的案例来看,CPU 利用率大约为 90%,内存利用率已达到 100%。 这表明每个流节点的资源已耗尽,无法处理数据。
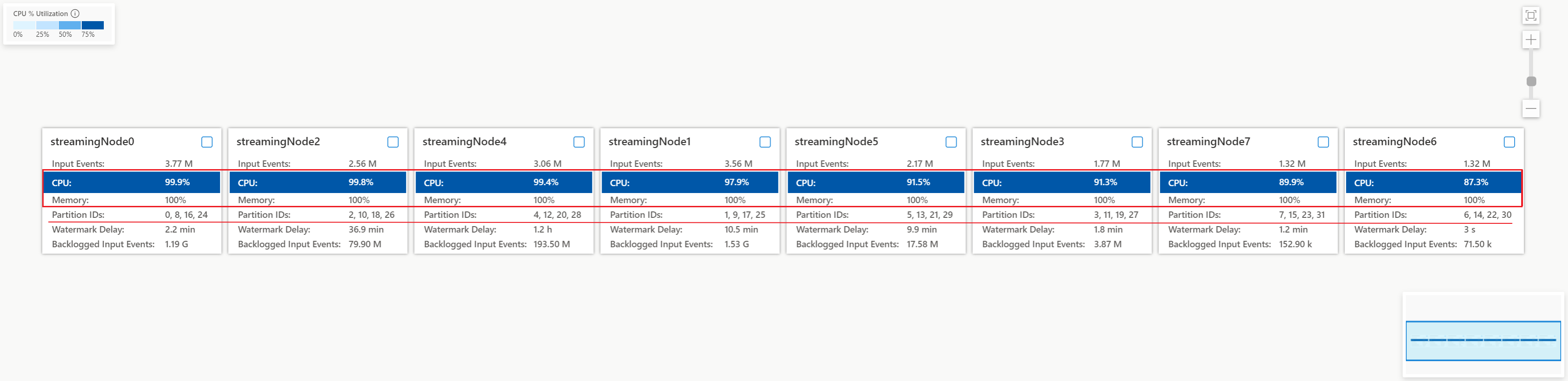
检查为每个流节点分配了多少分区,以便可以确定是否需要创建更多流节点来平衡分区,以减轻现有流节点的负担。
对于本案例,为每个流节点分配了四个分区,这对于一个流节点而言似乎太多。


可以进一步采取哪些操作?
考虑减少每个流节点的分区计数以减少输入数据。 可以通过将流节点计数从 8 个增加到 16 个,将分配给每个流节点的 SU 数倍增为每个节点有两个分区。 或者可以将 SU 的数量变为原来的四倍,使每个流式处理节点处理来自一个分区的数据。
若要详细了解流节点和流单元之间的关系,请参阅了解流单元和流节点。
一个流式节点处理来自一个分区的数据时,如果水印延迟仍在增加,应该怎么办? 将输入重新划分为更多分区,以减少每个分区中的数据量。 有关详细信息,请参阅使用重新分区优化 Azure 流分析作业。