Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文包含此服务的所有监视参考信息。
请参阅监视 Azure 流分析,详细了解可为 Azure 流分析收集的数据以及如何使用这些数据。
指标
本部分列出了为此服务自动收集的所有平台指标。 这些指标也是 Azure Monitor 中支持的所有平台指标的全局列表的一部分。
有关指标保留的信息,请参阅 Azure Monitor 指标概述。
Azure 流分析提供大量可用于监视查询和作业性能并对其进行故障排除的指标。 可以在 Azure 门户的“概述”页上的“监视”部分查看这些指标中的数据。

如果要检查特定指标,请选择“监视”部分中的“指标”。 在出现的页面上,选择该指标。

Microsoft.StreamAnalytics/streamingjobs 支持的指标
下表列出了可用于 Microsoft.StreamAnalytics/streamingjobs 资源类型的指标。
- 并非所有列都显示了每个表中。
- 某些列可能超出了页面的查看区域。 选择“展开表”以查看所有可用列。
表标题
- 类别 - 指标组或分类。
- 指标 - 在 Azure 门户中显示的指标显示名称。
- REST API 中的名称 - 在 REST API 中引用的指标名称。
- 单位 - 度量单位。
- 聚合 - 默认的聚合类型。 有效值:平均值(平均)、最小值(最小值)、最大值(最大值)、总计(总和)、计数。
- 维度 - 适用于指标的维度。
- 时间粒度 - 对指标采样的间隔。 例如,
PT1M表示该指标每分钟采样一次,PT30M表示每 30 分钟一次,PT1H表示每小时一次,以此类推。 - DS 导出 - 是否可通过诊断设置将指标导出到 Azure Monitor 日志。 要了解如何导出指标的信息,请参阅在 Azure Monitor 中创建诊断设置。
指标说明
Azure 流分析提供以下指标用于监视作业的运行状况。
| 指标 | 定义 |
|---|---|
| 积压的输入事件数 | 积压的输入事件的数量。 此指标的非零值意味着作业无法跟上传入事件的数量。 如果此值缓慢增长或始终为非零,则应横向扩展作业。 有关详细信息,请参阅了解和调整流单元。 |
| 数据转换错误数 | 无法转换为预期输出架构的输出事件的数量。 若要删除遇到这种情况的事件,可以将错误策略更改为“删除”。 |
| CPU 利用率百分比(预览) | 作业使用的 CPU 百分比。 即使此值非常高(90% 或以上),也不应只根据此指标增加 SU 数量。 如果积压输入事件或水印延迟数量增加,则可以使用此指标来确定是否是 CPU 造成了瓶颈。 此指标可能有间歇性峰值。 建议进行缩放测试,以确定在 CPU 瓶颈导致输入积压或水印延迟增加之前的作业上限。 |
| 提前输入事件数 | 应用程序时间戳早于其到达时间超过 5 分钟的事件。 |
| 失败的函数请求数 | 失败的 Azure 机器学习函数(如果存在)调用数。 |
| 函数事件数 | 发送到 Azure 机器学习函数(如果存在)的事件数。 |
| 函数请求数 | Azure 机器学习函数(如果存在)的调用数。 |
| 输入反序列化错误 | 不可反序列化的输入事件数。 |
| 输入事件字节数 | 流分析作业收到的数据量(以字节为单位)。 可使用此指标验证正在发送到输入源的事件。 |
| 输入事件数 | 从输入事件反序列化的记录数。 此计数不包括导致反序列化错误的传入事件。 流分析可以在内部恢复和自联接等场景中多次引入相同的事件。 如果作业具有简单的传递查询,则不要期望输入事件和输出事件指标相匹配。 |
| 收到的输入源数 | 作业收到的消息数。 对于 Azure 事件中心,消息是单个 EventData 项。 对于 Azure Blob 存储,消息是单个 blob。 请注意,在反序列化之前,将会统计输入源的数目。 如果存在反序列化错误,则输入源数可能大于输入事件数。 否则,输入源数可能小于或等于输入事件数,因为每条消息可能包含多个事件。 |
| 延迟输入事件数 | 到达时间晚于已配置的延迟到达容错时段的事件。 详细了解 Azure 流分析事件顺序注意事项。 |
| 无序事件数 | 收到的无序事件的数目,系统根据事件排序策略来删除这些事件,或者为其提供一个经过调整的时间戳。 该指标可能会受“无序容错时段”设置配置的影响。 |
| 输出事件数 | 流分析作业发送到输出目标的数据量,以事件数来衡量。 |
| 运行时错误 | 与查询处理相关的错误总数。 它排除在引入事件或输出结果时发现的错误。 |
| SU (内存) 利用率百分比 | 作业使用的内存百分比。 如果该指标持续超过 80%,则水印延迟增加,积压的事件数增加,请考虑增加流单元 (SU)。 高利用率指示作业使用的资源数接近分配的最大资源数。 |
| 水印延迟 | 作业中所有输出的所有分区之间的最大水印延迟。 |
指标维度
有关指标维度定义的信息,请参阅多维指标。
此服务具有以下与其指标关联的维度。
| 维度 | 定义 |
|---|---|
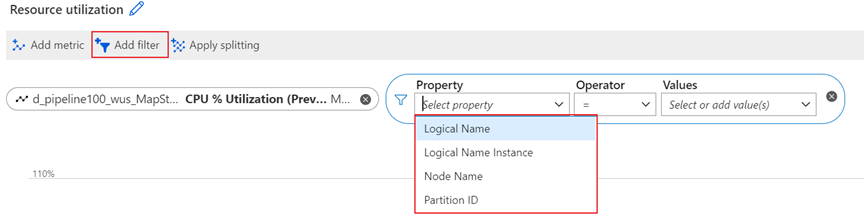
| 逻辑名称 | 流分析 (ASA) 作业的输入或输出名称。 |
| 分区 ID | 来自输入源的输入数据分区的 ID。 例如,如果输入源是事件中心,则分区 ID 是事件中心的分区 ID。 对于易并行作业,输出与输入中的分区 ID相同。 |
| 节点名称 | 作业运行时预配的流式处理节点的标识符。 流式处理节点表示分配给作业的计算和内存资源量。 |

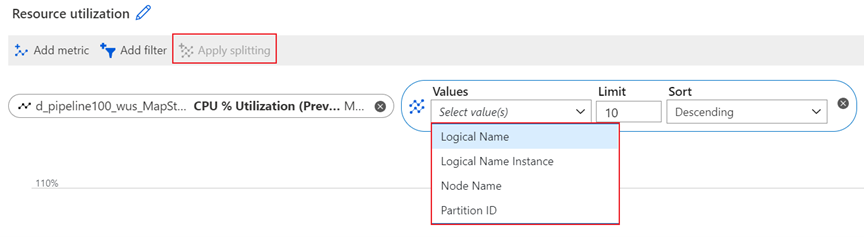
逻辑名称维度
逻辑名称是流分析作业的输入、输出名称。 例如,假设流分析作业有四个输入和输出和五个输出。 在此维度拆分与输入、输出相关的指标时,将看到四个单独的逻辑输入和五个单独的逻辑输出。


逻辑名称维度可用于筛选和拆分以下指标:
- 积压的输入事件数
- 数据转换错误数
- 提前输入事件数
- 输入反序列化错误
- 输入事件字节数
- 输入事件数
- 收到的输入源
- 延迟输入事件数
- 无序事件数
- 输出事件数
- 水印延迟
“节点名称”维度
流式处理节点表示一组用于处理输入数据的计算资源。 每六个流单元 (SU) 为一个节点,服务会代表你自动管理该节点。 有关流单元与流式处理节点之间的关系的详细信息,请参阅了解和调整流单元。
节点名称是流式处理节点级别的维度。 它可以帮你将某些指标深化到特定流式处理节点级别。 例如,可以将 CPU 利用率百分比指标拆分为流式处理节点级别,用于检查单个流式处理节点的 CPU 利用率。

节点名称维度可用于筛选和拆分以下指标:
- 积压的输入事件数
- CPU 利用率百分比(预览版)
- 输入事件数
- 输出事件数
- SU (内存) 利用率百分比
- 水印延迟
“分区 ID”维度
将流式处理数据引入到 Azure 流分析服务进行处理时,输入数据会根据输入源中的分区分发到流式处理节点。 分区 ID 维度是输入源中输入数据分区的 ID。
例如,如果输入源是事件中心,则分区 ID 是事件中心的分区 ID。 输入与输出的分区 ID 相同。

分区 ID 维度可用于筛选和拆分以下指标:
- 积压的输入事件数
- 数据转换错误数
- 提前输入事件数
- 输入反序列化错误
- 输入事件字节数
- 输入事件数
- 收到的输入源
- 延迟输入事件数
- 输出事件数
- 水印延迟
资源日志
本部分列出了可为此服务收集的资源日志类型。 本部分拉取自 Azure Monitor 支持的所有资源日志类别类型列表。
资源日志架构
所有日志均以 JSON 格式存储。 每个项目均具有以下常见字符串字段:
| 名称 | 说明 |
|---|---|
| time | 日志时间戳(采用 UTC)。 |
| ResourceId | 发生操作的资源的 ID,采用大写格式。 其中包括订阅 ID、资源组和作业名称。 例如,/SUBSCRIPTIONS/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/RESOURCEGROUPS/MY-RESOURCE-GROUP/PROVIDERS/MICROSOFT.STREAMANALYTICS/STREAMINGJOBS/MYSTREAMINGJOB。 |
| category | 日志类别,“执行”或“创作”。 |
| operationName | 被记录的操作的名称。 例如,发送事件:SQL 输出写入到 mysqloutput 失败。 |
| 状态 | 操作的状态。 例如,“失败”或“成功”。 |
| level | 日志级别。 例如,“错误”、“警告”或“信息性消息”。 |
| properties | 日志项目的具体详细信息;序列化为 JSON 字符串。 有关详细信息,请参阅本文的以下部分。 |
执行日志属性架构
执行日志包含有关执行流分析作业期间发生的事件的信息。 属性的架构根据事件是数据错误还是一般事件而有所不同。
数据错误
作业处理数据期间出现的任何错误都在此日志类别中。 这些日志通常创建于读取数据、序列化和写入操作期间。 这些日志不包括连接错误。 连接错误被视为泛型事件。 你可以详细了解各种输入和输出数据错误的原因。
| 名称 | 说明 |
|---|---|
| Source | 发生错误的作业输入或输出的名称。 |
| Message | 与错误关联的消息。 |
| 类型 | 错误类型。 例如,DataConversionError、CsvParserError 和 ServiceBusPropertyColumnMissingError 。 |
| 数据 | 包含用于准确找到错误起源的数据。 会根据数据大小截断数据。 |
数据错误根据 operationName 值采用以下架构:
事件读取操作期间会发生序列化事件。 当输入处的数据由于以下原因之一而不满足查询架构时,就会出现这些情况:
事件序列化/反序列化期间类型不匹配:识别导致出错的字段。
无法读取事件,序列化无效:列出输入数据中发生错误的相关位置信息。 包括用于 blob 输入的 blob 名称、偏移量和数据示例。
写入操作期间发生发送事件。 它们标识导致错误的流式处理事件。
泛型事件
泛型事件包含其他所有情况。
| 名称 | 说明 |
|---|---|
| 错误 | (可选)错误信息。 通常情况下,如果有异常信息,则为异常信息。 |
| Message | 日志消息。 |
| 类型 | 消息类型。 映射到错误的内部分类。 例如,JobValidationError 或 BlobOutputAdapterInitializationFailure。 |
| 相关性 ID | GUID 。 从作业开始到作业停止期间所有的执行日志条目具有相同的“相关 ID”值。 |
有关参考,请参阅 Azure Monitor 中支持的所有资源日志类别类型或为 Azure 流分析收集的所有资源日志类别类型列表。
Azure Monitor 日志表
本部分列出了与此服务相关的 Azure Monitor 日志表,日志分析可使用 Kusto 查询来查询这些表。 这些表包含资源日志数据,此外还可能包含其他数据,具体取决于所收集并路由到这些表的内容。
流分析作业
活动日志
链接表列出了可在此服务的活动日志中记录的操作。 这些操作是活动日志中所有可能的资源提供程序操作的子集。
有关活动日志条目架构的详细信息,请参阅活动日志架构。