Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文介绍如何使用数据库设计器在 Azure Synapse 中修改现有的湖数据库。 使用数据库设计器,无需编写任何代码即可轻松创建和部署数据库。
先决条件
- 创建湖数据库需要对 Synapse 工作区拥有 Synapse 管理员或 Synapse 参与者权限。
- 使用“从数据湖创建表”选项时,你需要拥有对数据湖的“存储 Blob 数据参与者”权限。
修改数据库属性
在 Azure Synapse Analytics 工作区“主页”中心,选择左侧的“数据”选项卡 。 此时会打开“数据”选项卡,其中显示了你工作区中现有的数据库列表。
将鼠标悬停在“数据库”部分,选择要修改的数据库旁边的省略号“...”,然后选择“打开”。
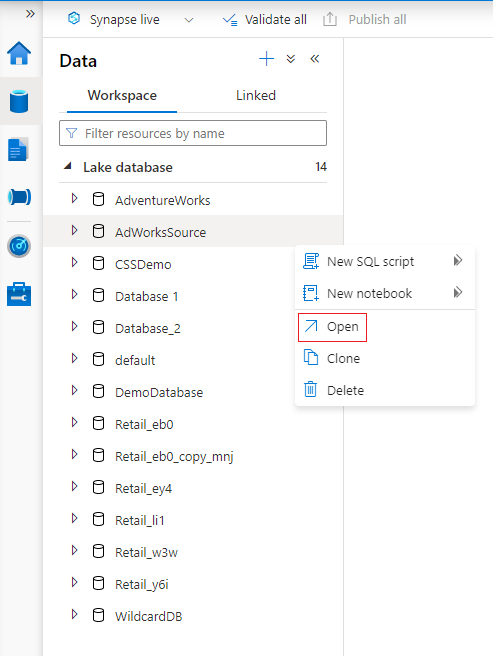
此时会打开数据库设计器选项卡,其中的画布上加载了选定的数据库。
数据库设计器具有“属性”窗格,可以通过选择选项卡右上角的“属性”图标打开该窗格。
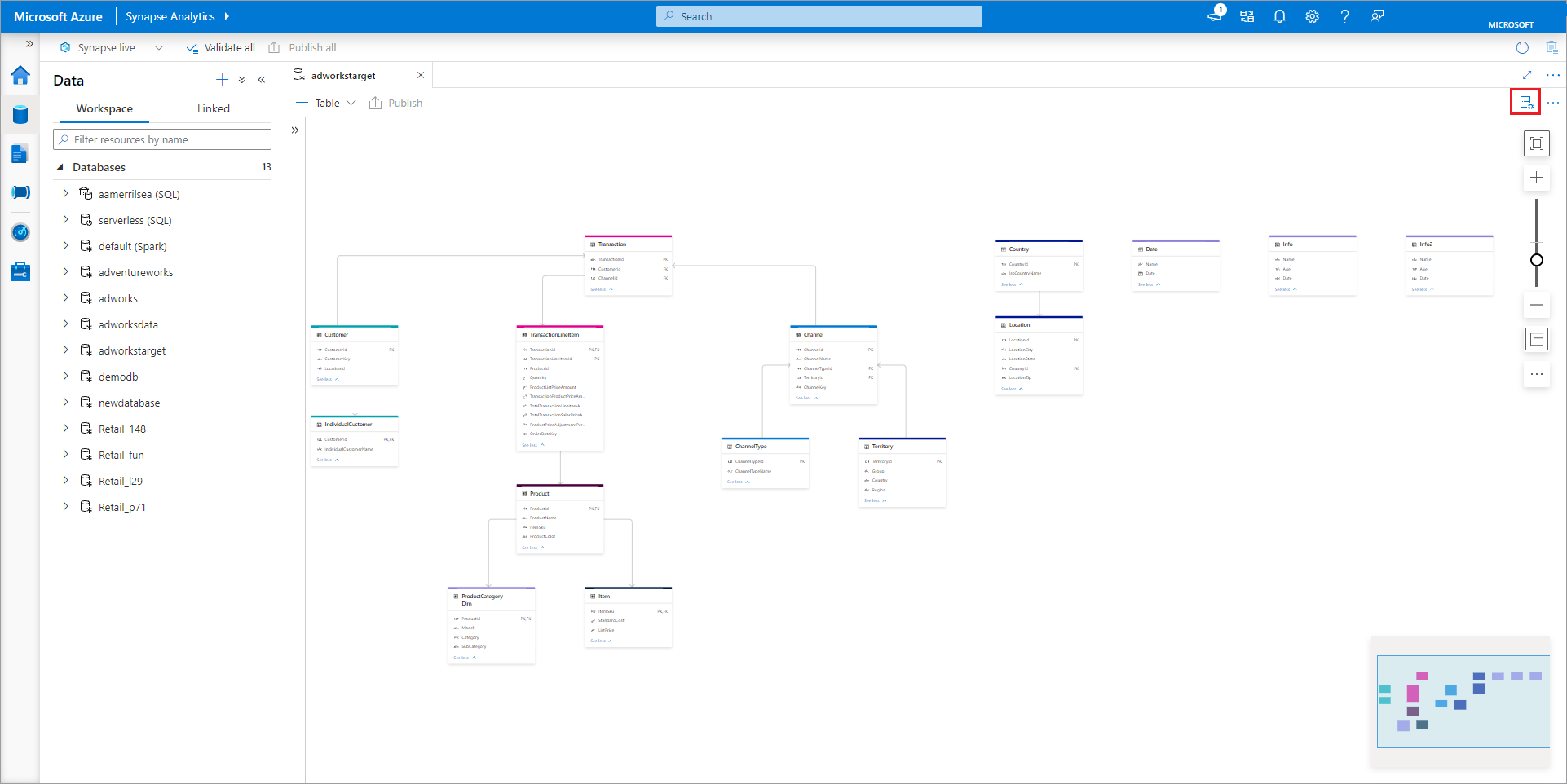
- 名称:发布数据库后无法编辑名称,因此请确保选择的名称正确。
- 说明:为数据库提供说明是可选操作,但它可以帮助用户了解数据库的用途。
- “数据库的存储设置”部分包含数据库中表的默认存储信息。 默认设置将应用于数据库中的每个表,除非表本身替代了这些设置。
- “链接服务”是用于在 Azure Data Lake Storage 中存储数据的默认链接服务。 将显示与 Synapse 工作区关联的默认链接服务,但你可以将“链接服务”更改为所需的任何 ADLS 存储帐户。
- “输入文件夹”用于在该链接服务中设置默认容器和文件夹路径,方法是使用文件浏览器或使用铅笔图标手动编辑路径。
- 数据格式:Azure Synapse 中的湖数据库支持使用 parquet 格式和带分隔符的文本作为数据存储格式。
若要将表添加到数据库,请选择“+ 表”按钮。
- 选择“自定义”会在画布中添加一个新表。
- 选择“从模板”会打开库,然后你可以选择在添加新表时要使用的数据库模板。
- 选择“从数据湖”可以使用湖中已有的数据导入表架构。
选择“自定义”。 画布上将出现一个名为 Table_1 的新表。
然后你可以自定义 Table_1,包括表名、说明、存储设置、列和关系。 请参阅下面的“自定义数据库中的表”部分。
依次选择“+ 表”、“从数据湖”,从数据湖添加一个新表 。
此时会显示“从数据湖创建外部表”窗格。 在该窗格中填写以下详细信息,然后选择“继续”。
- 外部表名:要为创建的表指定的名称。
- 链接服务:包含数据文件所在的 Azure Data Lake Storage 位置的链接服务。
- 输入文件或文件夹:使用文件浏览器在湖中导航到并选择一个要用于创建表的文件。
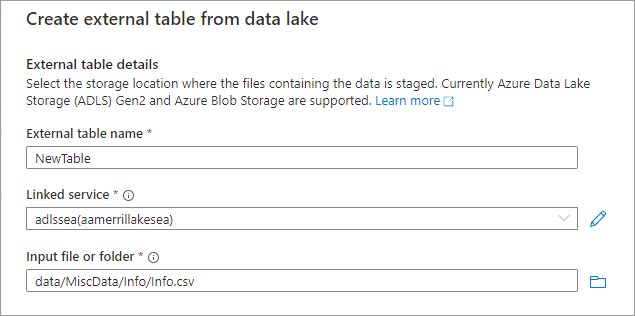
- 在下一个屏幕上,Azure Synapse 将显示文件预览并检测架构。
- 你将进入“新建外部表”页,可以在其中更新与数据格式相关的任何设置,以及使用“预览数据”来检查 Azure Synapse 是否正确识别了文件 。
- 如果对设置感到满意,请选择“创建”。
- 具有所选名称的新表将添加到画布中,“表的存储设置”部分将显示你指定的文件。
自定义数据库后,接下来可以发布它了。
在发布数据库之前,系统会验证它是否存在错误。 发现的任何错误都将显示在通知选项卡中,并且还会提供有关如何修正错误的说明。
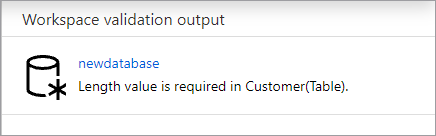
发布过程将在 Azure Synapse 元存储中创建数据库架构。 发布后,数据库和表对象将对其他 Azure 服务可见,并允许数据库中的元数据流入 Power BI 之类的应用。
自定义数据库中的表
使用数据库设计器可以全面自定义数据库中的任何表。 选择某个表时,会显示三个选项卡,每个选项卡包含与该表的架构或元数据相关的设置。
常规
“常规”选项卡包含特定于该表本身的信息。
名称:表的名称。 可将表名自定义为数据库中的任何唯一值。 不允许使用多个同名的表。
继承自(可选):如果该表是从数据库模板创建的,则会显示此值。 无法编辑此值,它会告知用户它是从哪个模板表派生的。
说明:表的说明。 如果该表是从数据库模板创建的,则此字段将包含对该表所代表的概念的说明。 此字段是可编辑的,可对其进行更改,以匹配与你的业务要求相符的说明。
“显示文件夹”提供该表作为数据库模板分组到的业务领域文件夹的名称。 对于自定义表,此值为“其他”。
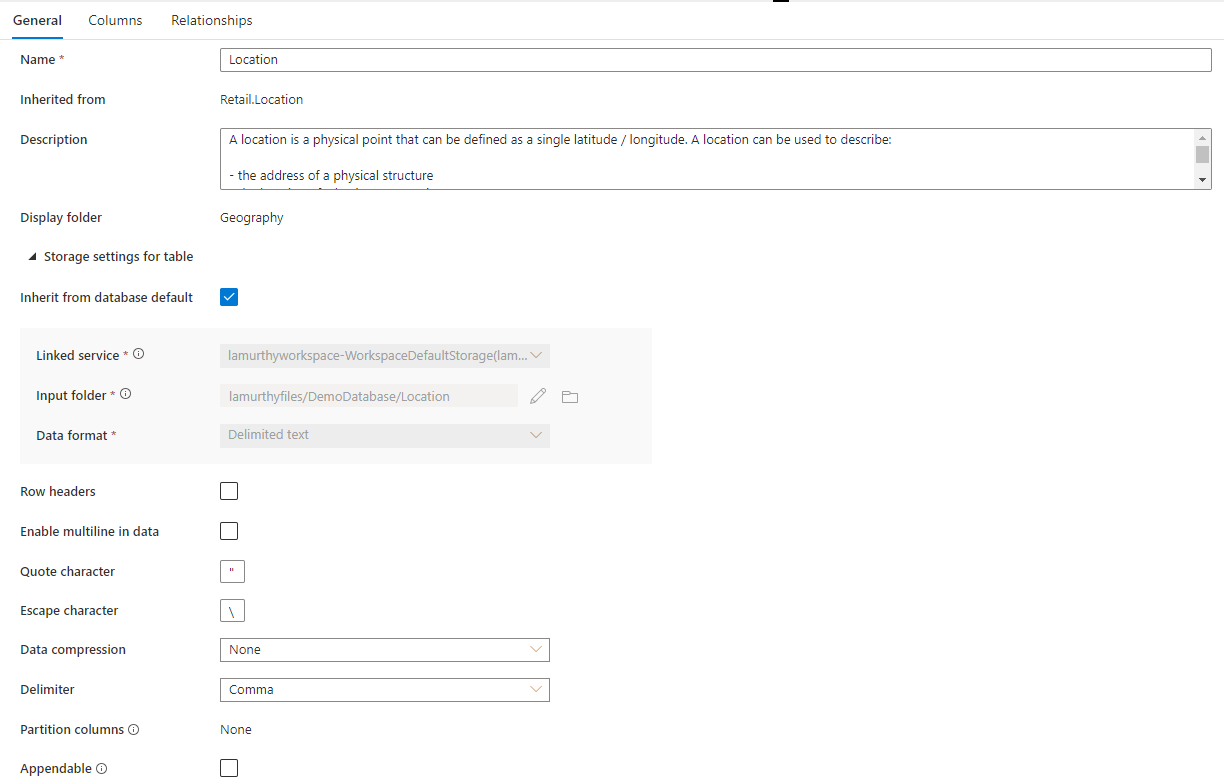
此外,还有一个名为“表的存储设置”的可折叠部分,其中提供了该表使用的基础存储信息设置。
默认从数据库继承:一个复选框,用于确定下面的存储设置是从数据库“属性”选项卡中设置的值继承的,还是单独设置的 。 如果你要自定义存储值,请取消选中此框。
- “链接服务”是用于在 Azure Data Lake Storage 中存储数据的默认链接服务。 更改此项可选择其他 ADLS 帐户。
- 输入文件夹:ADLS 中的文件夹,加载到此表的数据将驻留在其中。 可以使用铅笔图标浏览文件夹位置或手动编辑它。
- 数据格式:“输入文件夹”中数据的数据格式。Azure Synapse 中的湖数据库支持使用 parquet 格式和带分隔符的文本作为数据存储格式 。 如果数据格式与该文件夹中的数据不匹配,则对表的查询将会失败。
对于“带分隔符的文本”数据格式,还提供了其他设置:
- 行标题:如果数据具有行标题,请选中此框。
- 在数据中启用多行:如果数据在字符串列中有多个行,请选中此框。
- “引号字符”指定带分隔符的文本文件的自定义引号字符。
- “转义字符”指定带分隔符的文本文件的自定义转义字符。
- 数据压缩:对数据使用的压缩类型。
- 分隔符:数据文件中使用的字段分隔符。 支持的值为:逗号 (,)、制表符 (\t) 和竖线 (|)。
- 分区列:将在此处显示分区列的列表。
- 可追加:如果要从 SQL 无服务器查询 Dataverse 数据,请勾选此框。
对于 Parquet 数据,提供了以下设置:
- 数据压缩:对数据使用的压缩类型。
列
“列”选项卡列出了表的列,可在其中进行修改。 此选项卡上有两个列列表:“标准列”和“分区列” 。 “标准列”是用于存储数据的任何列(主键),否则不用于数据分区。 “分区列”也存储数据,但用于根据列中包含的值将基础数据分区到文件夹中。 每个列具有以下属性。
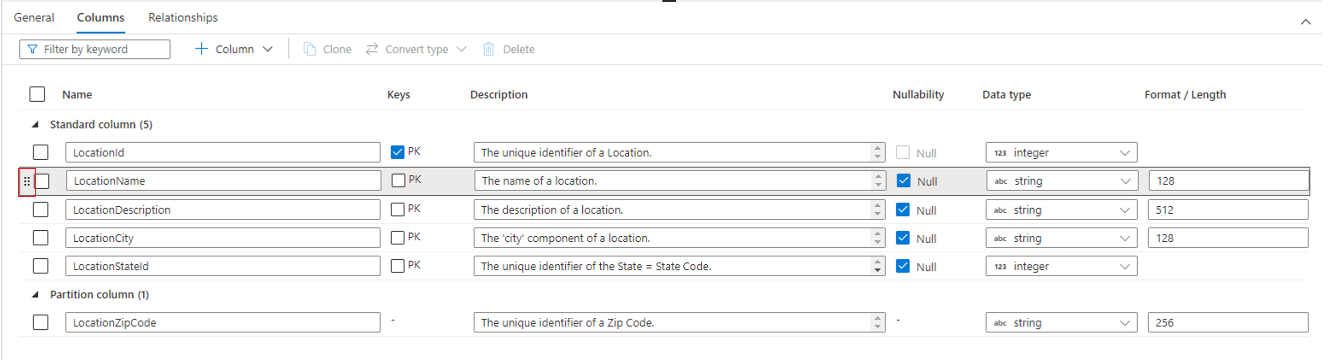
- 名称:列的名称。 在表中必须唯一。
- “键”指示列是表的主键 (PK) 还是外键 (FK)。 不适用于分区列。
- 说明:列的说明。 如果该列是从数据库模板创建的,则会显示该列所代表的概念的说明。 此字段是可编辑的,可对其进行更改,以匹配与你的业务要求相符的说明。
- 可为 Null 性:指示此列中是否可以包含 null 值。 不适用于分区列。
- 数据类型:根据可用的 Spark 数据类型列表设置列的数据类型。
- 格式/长度:用于根据数据类型自定义列的格式或最大长度。 日期和时间戳数据类型附带格式下拉列表,而其他类型(例如字符串)附带最大长度字段。 并非所有数据类型都有值,因为某些类型是固定长度的。 “列”选项卡顶部是一个命令栏,可用于与列进行交互。
- 按关键字筛选:将列列表筛选为与指定的关键字匹配的项。
- “+ 列”可用于添加新列。 有三个可能的选项。
- 新建列:创建一个新的自定义标准列。
- 从模板:打开浏览窗格,可在其中识别数据库模板中要包含在表中的列。 如果数据库不是使用数据库模板创建的,则不会显示此选项。
- 分区列:添加一个新的自定义分区列。
- 克隆:复制所选的列。 克隆的列始终与所选列的类型相同。
- 转换类型:用于将所选的标准列更改为分区列,或反之 。 如果选择了多个不同类型的列,或者所选列由于设置了“PK”或“可为 Null 性”标志而不符合转换条件,则此选项将灰显 。
- 删除:从表中删除所选的列。 此操作不可逆。
还可以通过使用在将鼠标悬停在上图中所示的列上时或单击它时会显示在列名左侧的双垂直省略号进行拖放,来重新排列列的顺序。
分区列
分区列用于根据这些列中的值对数据库中的物理数据进行分区。 分区列提供了将磁盘上的数据分布到性能更高的块的简单方法。 Azure Synapse 中的分区列始终位于表架构的末尾。 此外,在创建分区文件夹时,将从上到下使用这些列。 例如,如果分区列是 Year 和 Month,则最终会在 ADLS 中创建如下所示的结构:
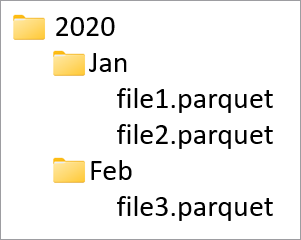
其中 file1 和 file2 包含 Year 和 Month 值分别为 2020 和 Jan 的所有行。 随着在表中添加更多的分区列,将在此层次结构中添加更多的文件,从而使分区的整体文件大小变得更小。
Azure Synapse 不会通过向表添加分区列来强制实施或创建此层次结构。 必须使用 Synapse Pipelines 或 Spark 笔记本将数据加载到表中,以便创建分区结构。
关系
使用“关系”选项卡可以指定数据库中表之间的关系。 数据库设计器中的关系是信息性的,不会对基础数据强制实施任何约束。 关系由其他 Microsoft 应用程序读取,可用于加速转换或让业务用户深入了解表的关联方式。 “关系”窗格包含以下信息。
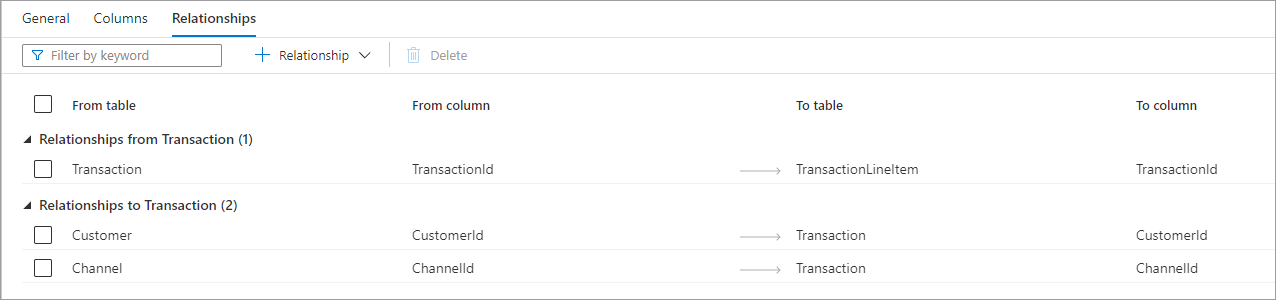
- “从(表)的关系”表示一个或多个表具有已关联到该表的外键。 有时这称为父关系。
- “到(表)的关系”表示某个表具有外键并已关联到其他表。 有时这称为子关系。
- 这两种关系类型都具有以下属性。
- 从表:关系中的父表,或者“一”端。
- 从列:关系所基于的父表中的列。
- 到表:关系中的子表,或者“多”端。
- 到列:关系所基于的子表中的列。 “关系”选项卡顶部是一个命令栏,可用于与关系进行交互
- 按关键字筛选:将列列表筛选为与指定的关键字匹配的项。
- “+ 关系”可用于添加新的关系。 共有两个选项。
- 从表:创建从你正在处理的表到其他表的新关系。
- 到表:创建从其他表到你正在处理的表的新关系。
- 从模板:打开浏览窗格,在其中可以从数据库模板中选择要包含在数据库中的关系。 如果数据库不是使用数据库模板创建的,则不会显示此选项。
后续步骤
使用以下链接继续探索数据库设计器功能。