Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
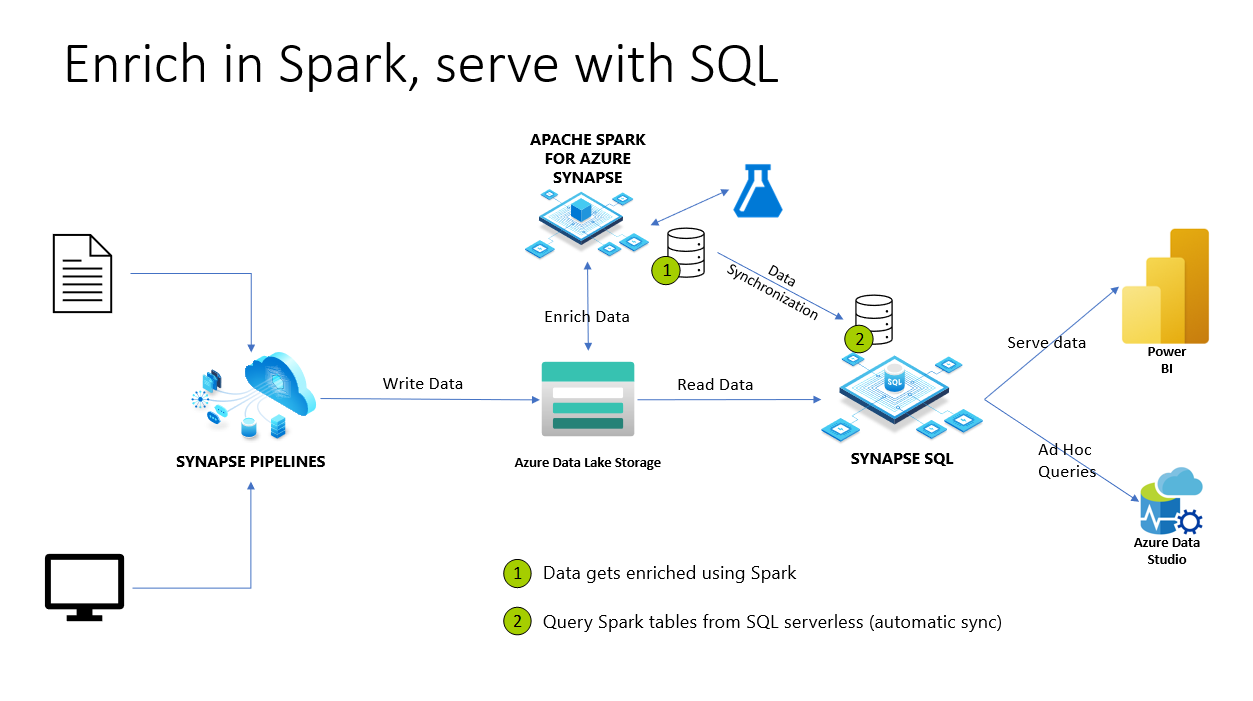
在 Azure Synapse Analytics 中,Spark 数据库 和 表 与无服务器 SQL 池共享。 使用 Spark 创建的 Lake 数据库、Parquet 和 CSV 作为后端的表会自动在无服务器 SQL 池中可用。 此功能允许使用无服务器 SQL 池浏览和查询使用 Spark 池准备的数据。 在下图中,可以看到一个高级体系结构概述来利用此功能。 首先,Azure Synapse Pipelines 将数据从本地(或其他)存储移动到 Azure Data Lake Storage。 Spark 现在可以扩充数据,并创建数据库和表,这些表将同步到无服务器 Synapse SQL。 稍后,用户可以在扩充数据的基础上执行即席查询,或将其用于 Power BI,例如。
完全管理员访问权限 (sysadmin)
将这些数据库和表从 Spark 同步到无服务器 SQL 池后,可以使用无服务器 SQL 池中的这些外部表来访问相同的数据。 但是,由于保持与 Spark 池对象的一致性,无服务器 SQL 池中的对象是只读的。 此限制使只有具有 Synapse SQL 管理员或 Synapse 管理员角色的用户才能在无服务器 SQL 池中访问这些对象。 如果非管理员用户尝试对同步的数据库/表执行查询,他们将收到如下错误: External table '<table>' is not accessible because content of directory cannot be listed. 尽管他们有权访问基础存储帐户上的数据。
由于无服务器 SQL 池中的同步数据库是只读的,因此无法修改它们。 如果尝试,创建用户或授予其他权限将失败。 若要读取同步的数据库,必须具有特权服务器级权限(如 sysadmin)。 使用 Azure Synapse Link for Dataverse 和 Lake 数据库表时,无服务器 SQL 池中的外部表也存在此限制。
对已同步数据库的非管理员访问权限
需要读取数据和创建报表的用户通常没有完全管理员访问权限(sysadmin)。 此用户通常是数据分析师,他们只需要使用现有表读取和分析数据。 它们不需要创建新对象。
具有最小权限的用户应能够:
- 连接到从 Spark 复制的数据库
- 通过外部表选择数据并访问基础 ADLS 数据。
执行下面的代码脚本后,它将允许非管理员用户具有连接到任何数据库的服务器级权限。 它还允许用户查看所有架构级别对象(如表或视图)中的数据。 可以在存储层上管理数据访问安全性。
-- Creating Azure AD login (same can be achieved for Azure AD app)
CREATE LOGIN [login@contoso.com] FROM EXTERNAL PROVIDER;
go;
GRANT CONNECT ANY DATABASE to [login@contoso.com];
GRANT SELECT ALL USER SECURABLES to [login@contoso.com];
GO;
注释
这些语句应在 master 数据库上执行,因为这些语句都是服务器级权限。
创建登录名并授予权限后,用户可以在同步的外部表上运行查询。 还可以将此缓解措施应用于 Microsoft Entra 安全组。
可以通过特定架构管理对象上的更多安全性,并锁定对特定架构的访问。 解决方法需要额外的 DDL。 对于此方案,可以创建新的无服务器数据库、架构和视图,这些视图将指向 ADLS 上的 Spark 表数据。
可以通过 ACL 或 Microsoft Entra 用户/组的常规 存储 Blob 数据所有者/读取者/参与者角色 来管理对存储帐户上的数据的访问。 对于服务主体(Microsoft Entra 应用),请确保使用 ACL 设置。
注释
- 如果要禁止在数据之上使用 OPENROWSET,可以使用
DENY ADMINISTER BULK OPERATIONS to [login@contoso.com];有关详细信息,请访问 DENY 服务器权限。 - 如果要禁止使用特定架构,可以使用
DENY SELECT ON SCHEMA::[schema_name] TO [login@contoso.com];有关详细信息,请访问 DENY 架构权限。
后续步骤
有关详细信息,请参阅 SQL 身份验证。