添加一行代码, mlflow.<library>.autolog() 以自动跟踪生成 AI 应用。 自动跟踪适用于 现时支持的 20 多个库和框架 。
注释
在无服务器计算群集上,不会自动启用 genAI 跟踪框架的自动记录。 必须通过为要跟踪的特定集成调用适当的 mlflow.<library>.autolog() 函数来显式启用自动记录。
先决条件
Databricks 建议使用 MLflow 3 获取最新的 GenAI 跟踪功能。
在 Databricks 笔记本中运行以下命令,以安装 mlflow 要使用的包和集成包。 此示例使用 OpenAI:
MLflow 3
- mlflow[databricks]>=3.1:具有 GenAI 功能和 Databricks 连接的核心 MLflow 功能。
- openai>=1.0.0:仅需要在此页上运行 基本自动跟踪示例 (如果使用其他 LLM 提供程序,请改为安装各自的 SDK)。
- 其他库:为要使用的集成安装特定库。
安装基本要求:
%pip install --upgrade "mlflow[databricks]>=3.1" openai>=1.0.0
# Also install libraries you want to trace (langchain, anthropic, etc.)
dbutils.library.restartPython()
MLflow 2.x
- mlflow[databricks]>=2.15.0,3.0.0<:具有 Databricks 连接的核心 MLflow 功能。
- openai>=1.0.0:仅需要在此页上运行 基本自动跟踪示例 (如果使用其他 LLM 提供程序,请改为安装各自的 SDK)。
- 其他库:为要使用的集成安装特定库。
安装基本要求:
%pip install --upgrade "mlflow[databricks]>=2.15.0,<3.0.0" openai>=1.0.0
# Also install libraries you want to trace (langchain, anthropic, etc.)
dbutils.library.restartPython()
配置凭据
Databricks 笔记本
在 Databricks 笔记本中,设置任何必要的 LLM API 密钥:
import os
os.environ["OPENAI_API_KEY"] = "your-api-key"
# Add other provider keys as needed
# os.environ["ANTHROPIC_API_KEY"] = "your-api-key"
# os.environ["MISTRAL_API_KEY"] = "your-api-key"
外部环境
如果位于外部环境中,请设置 Databricks 凭据和 LLM API 密钥:
export DATABRICKS_HOST="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-databricks-token"
# Add other provider keys as needed
#export OPENAI_API_KEY="your-openai-api-key"
# export ANTHROPIC_API_KEY="your-anthropic-api-key"
# export MISTRAL_API_KEY="your-mistral-api-key"
自动跟踪示例
MLflow 自动跟踪 20 多个受支持的框架。 下面介绍如何为连接到 Databricks Foundation 模型 API 的 OpenAI 代理启用自动跟踪。
import mlflow
import os
from openai import OpenAI
# Databricks Foundation Model APIs use Databricks authentication.
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/databricks-sdk-autolog-example")
# Enable auto-tracing for OpenAI (which will trace Databricks Foundation Model API calls)
mlflow.openai.autolog()
# Create OpenAI client configured for Databricks
client = OpenAI(
api_key=os.environ.get("DATABRICKS_TOKEN"),
base_url=f"{os.environ.get('DATABRICKS_HOST')}/serving-endpoints"
)
# Query Llama 4 Maverick using OpenAI client
response = client.chat.completions.create(
model="databricks-llama-4-maverick",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What are the key features of MLflow Tracing?"}
],
max_tokens=150,
temperature=0.7
)
print(response.choices[0].message.content)
# Your calls to Databricks Foundation Model APIs are automatically traced!
自动跟踪多个框架
可以对同一代理中的多个框架使用自动跟踪。 查看所有 受支持的框架。
以下代码将直接 OpenAI API 调用、LangChain 链和自定义逻辑组合在一个跟踪中,以便于调试和监视。
%pip install --upgrade langchain langchain-openai
import mlflow
import openai
from mlflow.entities import SpanType
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# Enable auto-tracing for both OpenAI and LangChain
mlflow.openai.autolog()
mlflow.langchain.autolog()
# Create OpenAI client
client = openai.OpenAI()
@mlflow.trace(span_type=SpanType.CHAIN)
def multi_provider_workflow(query: str):
# First, use OpenAI directly for initial processing
analysis = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Analyze the query and extract key topics."},
{"role": "user", "content": query}
]
)
topics = analysis.choices[0].message.content
# Then use LangChain for structured processing
llm = ChatOpenAI(model="gpt-4o-mini")
prompt = ChatPromptTemplate.from_template(
"Based on these topics: {topics}\nGenerate a detailed response to: {query}"
)
chain = prompt | llm
response = chain.invoke({"topics": topics, "query": query})
return response
# Run the function
result = multi_provider_workflow("Explain quantum computing")
合并手动跟踪和自动跟踪
与 @mlflow.trace 自动跟踪一起使用,为以下方案创建统一跟踪:
- 一个工作流中的多个 LLM 调用
- 具有不同提供程序的多代理系统
- LLM 调用之间的自定义逻辑
import mlflow
import openai
from mlflow.entities import SpanType
mlflow.openai.autolog()
# Create OpenAI client
client = openai.OpenAI()
@mlflow.trace(span_type=SpanType.CHAIN)
def run(question):
messages = build_messages(question)
# MLflow automatically generates a span for OpenAI invocation
response = client.chat.completions.create(
model="gpt-4o-mini",
max_tokens=100,
messages=messages,
)
return parse_response(response)
@mlflow.trace
def build_messages(question):
return [
{"role": "system", "content": "You are a helpful chatbot."},
{"role": "user", "content": question},
]
@mlflow.trace
def parse_response(response):
return response.choices[0].message.content
run("What is MLflow?")
运行此代码将生成一个跟踪,该跟踪将手动范围与自动 OpenAI 跟踪相结合:
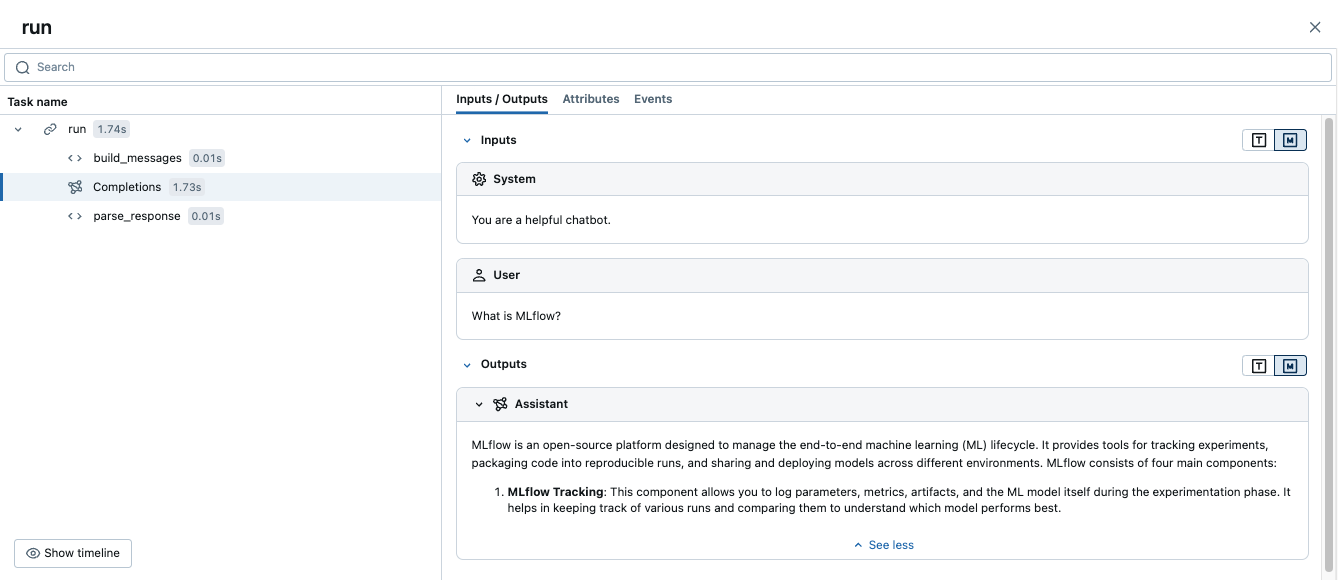
高级示例:多个 LLM 调用
以下示例演示如何自动跟踪在单个工作流中捕获多个 LLM 调用。
当应用程序需要做出顺序决策(例如先分析查询,然后基于该分析生成响应)时,此模式非常有用。
import mlflow
import openai
from mlflow.entities import SpanType
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Create OpenAI client
client = openai.OpenAI()
@mlflow.trace(span_type=SpanType.CHAIN)
def process_user_query(query: str):
# First LLM call: Analyze the query
analysis = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Analyze the user's query and determine if it requires factual information or creative writing."},
{"role": "user", "content": query}
]
)
analysis_result = analysis.choices[0].message.content
# Second LLM call: Generate response based on analysis
if "factual" in analysis_result.lower():
# Use a different model for factual queries
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Provide a factual, well-researched response."},
{"role": "user", "content": query}
]
)
else:
# Use a different model for creative queries
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Provide a creative, engaging response."},
{"role": "user", "content": query}
]
)
return response.choices[0].message.content
# Run the function
result = process_user_query("Tell me about the history of artificial intelligence")
这将创建一个跟踪,其中包含:
- 父范围
process_user_query - OpenAI 调用的两个子范围
后续步骤
- 自动跟踪集成 - 浏览所有 20 多个受支持的库和框架
- 使用修饰器进行手动跟踪 - 添加自定义范围以捕获业务逻辑以及自动跟踪 LLM 调用