Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Azure Stream Analytics可以将 JSON 格式的数据输出到 JSON 输出的 Azure Cosmos DB,从而对非结构化 JSON 数据启用数据存档和低延迟查询。 本文档包括用于实现此配置的一些最佳做法。 建议在将Azure Cosmos DB用作输出时将作业设置为兼容级别 1.2。
注意
- 目前,流分析仅支持通过 SQL API 连接到Azure Cosmos DB。尚不支持其他Azure Cosmos DB API。 如果将流分析指向Azure Cosmos DB使用其他 API 创建的帐户,则可能无法正确存储数据。
- 建议在将Azure Cosmos DB用作输出时将作业设置为兼容级别 1.2。
Azure Cosmos DB作为输出目标的基础知识
流分析中的Azure Cosmos DB输出支持将流处理结果作为 JSON 输出写入Azure Cosmos DB容器。 流分析不会在数据库中创建容器。 相反,你需要提前创建它们。 然后,可以控制Azure Cosmos DB容器的计费成本。 还可以使用
调整一致性、可用性和延迟
为了符合应用程序要求,Azure Cosmos DB允许微调数据库和容器,并在一致性、可用性、延迟和吞吐量之间进行权衡。
根据方案针对读写延迟需要什么级别的读取一致性,可以在数据库帐户上选择一致性级别。 可以通过纵向扩展容器中的请求单位 (RU) 数来提高吞吐量。 此外,默认情况下,Azure Cosmos DB对容器的每个 CRUD 操作启用同步索引。 此选项是另一个有用的选项,用于控制Azure Cosmos DB中的写入/读取性能。 有关详细信息,请参阅更改数据库和查询的一致性级别一文。
使用流分析进行插入或更新操作
流分析与 Azure Cosmos DB 的集成允许基于给定的 Document ID 列在容器中插入或更新记录。 此操作也称为“插入或更新”。 流分析使用乐观 Upsert 方法。 即仅当由于文档 ID 冲突而插入失败时才进行更新。
在 1.0 兼容级别中,流分析将此更新作为 PATCH 操作执行,因此可以对文档进行部分更新。 流分析添加新属性或增量替换现有属性。 但是,JSON 文档中数组属性值的更改会导致覆盖整个数组。 也就是说,不会合并数组。
在 1.2 版本中,"插入或更新"(upsert)行为被修改为插入或替换文档。 关于兼容性级别 1.2 的部分,后面将进一步描述这种行为。
如果传入的 JSON 文档具有现有的 ID 字段,该字段将自动用作 Azure Cosmos DB 中的 Document ID 列。 任何后续的写入操作都以这种方式进行处理,这会导致以下情况之一:
- 唯一ID 导致插入。
- 出现重复的 ID 并且将“文档 ID”设置为“ID”会导致插入更新。
- 第一个文档之后,重复的 ID 和未设置的 文档 ID 会导致错误。
如果要保存“所有”文档(包括具有重复 ID 的文档),请重命名查询中的 ID 字段(使用“AS”关键字)。 让我们Azure Cosmos DB创建 ID 字段或将 ID 替换为另一列的值(通过使用 AS 关键字或使用 Document ID 设置)。
Azure Cosmos DB中的数据分区
Azure Cosmos DB根据工作负荷自动缩放分区。 因此,建议使用无限制容器对数据进行分区。 当 Stream Analytics 写入无限制的容器时,它使用的并行写入器数量与先前查询步骤或输入分区方案的数量一致。
注意
Azure Stream Analytics仅支持具有顶级分区键的无限制容器。 例如,支持 /region。 不支持嵌套分区键(例如 /region/name)。
你可能会收到以下警告,具体取决于你选择的分区键:
CosmosDB Output contains multiple rows and just one row per partition key. If the output latency is higher than expected, consider choosing a partition key that contains at least several hundred records per partition key.
请务必选择包含许多不同值的分区键属性,并且该属性支持跨这些值均匀分布工作负载。 作为分区的自然项目,涉及同一分区键的请求受到单个分区的最大吞吐量的限制。
属于同一分区键值的文档的存储大小上限为 20 GB(物理分区大小上限为 50 GB)。 理想的分区键可以作为筛选器频繁出现在查询中,并具有足够的基数,以确保解决方案可缩放。
用于流分析查询和Azure Cosmos DB的分区键不需要相同。 完全并行拓扑建议使用 Input 分区键PartitionId作为流分析查询的分区键,但对于Azure Cosmos DB容器的分区键来说,这可能不是推荐的选择。
分区键也是存储过程中的事务的边界,也是Azure Cosmos DB的触发器。 选择分区键时,应确保在事务中同时出现的文档使用相同的分区键值。 文章《Azure Cosmos DB 中的分区》提供了有关选择分区键的更多详细信息。
对于固定的Azure Cosmos DB容器,流式分析在容器满后没有办法可以进行纵向扩展或横向扩展。 这些集合的大小上限为 10 GB,吞吐量上限为 10,000 RU/秒。 若要将数据从固定的容器迁移到无限制容器(例如,吞吐量至少为 1,000 RU/秒,且具有分区键),请使用数据迁移工具或更改源库。
将不再支持写入多个固定容器的功能。 我们不推荐将其用于扩展流分析作业。
使用兼容性级别 1.2 改进了吞吐量
兼容性级别为 1.2 时,流分析支持与 Azure Cosmos DB 进行原生集成,以实现批量写入。 此集成使得写入过程可以有效地连接到Azure Cosmos DB,最大限度地提高吞吐量并高效处理限流请求。
由于插入更新行为的差异,新的兼容性级别提供了一种改进的写入机制。 在 1.2 之前的级别,更新插入行为是插入或合并文档。 在 1.2 版本中,"插入或更新"(upsert)行为被修改为插入或替换文档。
在 1.2 之前的级别中,流分析使用自定义存储过程将每个分区键中的文档批量插入到 Azure Cosmos DB。 批处理在其中作为一个事务写入。 即使只有一条记录遇到暂时性错误(速率限制),也必须对整个批次进行重试。 此行为使即便是限流合理的场景,其运行速度也相对缓慢。
以下示例演示从同一 Azure Event Hubs 输入读取的两个相同的 Stream Analytics 作业。 两个流分析作业均完全分区,通过直接查询并写入到相同的多个 Azure Cosmos DB 容器。 左侧的指标来自配置了兼容性级别 1.0 的作业。 右侧的指标配置为 1.2。 Azure Cosmos DB容器的分区键是来自输入事件的唯一 GUID。
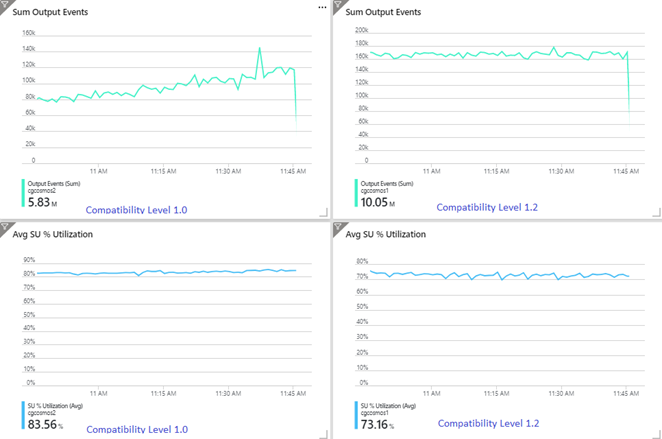
事件中心中的传入事件速率是 Azure Cosmos DB 容器配置的吞吐量(20,000 RU)的两倍,因此预计 Azure Cosmos DB 将出现限流。 但是,使用版本 1.2 的作业一贯以更高的吞吐量写入(即输出事件数/分钟),并且其平均 SU% 利用率更低。 在你的环境中,这种差异将取决于多个因素。 这些因素包括:事件格式的选择、输入事件/消息大小、分区键和查询。
使用 1.2 版本,流分析在利用 Azure Cosmos DB 的 100% 可用吞吐量方面更具智能性,几乎很少因为限流或速率限制而重新提交。 对于其他工作负荷(例如,同时在容器上运行的查询),此行为可以提供更好的体验。 如果您想了解流分析与 Azure Cosmos DB 配合使用时如何横向扩展以接收每秒 1,000 到 10,000 条消息,请尝试此 Azure 示例项目。
Azure Cosmos DB输出的吞吐量与 1.0 和 1.1 相同。 我们强烈建议在流分析中使用兼容性级别 1.2 和 Azure Cosmos DB。
用于 JSON 输出的 Azure Cosmos DB 设置
在流分析中使用Azure Cosmos DB作为输出会生成以下信息提示。
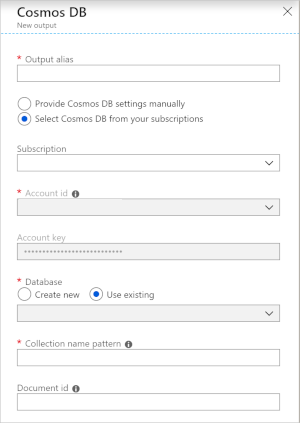
| 字段 | 说明 |
|---|---|
| 输出别名 | 用于在流分析查询中引用此输出的别名。 |
| 订阅 | Azure订阅。 |
| 帐户 ID | Azure Cosmos DB 帐户的名称或终结点 URI。 |
| 帐户密钥 | Azure Cosmos DB帐户的共享访问密钥。 |
| 数据库 | Azure Cosmos DB数据库名称。 |
| 容器名称 | 容器名称,如 MyContainer。 必须存在名为 MyContainer 的容器。 |
| 文档 ID | 可选。 输出事件中用作唯一键的列名称,插入或更新操作必须基于该键。 如果将其留空,则将插入所有事件,且没有更新选项。 |
配置Azure Cosmos DB输出后,可以在查询中将其用作 INTO 语句的目标。 使用 Azure Cosmos DB 输出时,需要显式设置一个分区键。
输出记录必须包含以Azure Cosmos DB分区键命名的区分大小写的列。 若要实现更大的并行化,该语句可能需要使用同一列的 PARTITION BY 子句。
下面是一个示例查询:
SELECT TollBoothId, PartitionId
INTO CosmosDBOutput
FROM Input1 PARTITION BY PartitionId
错误处理和重试
如果流分析将事件发送到Azure Cosmos DB时发生暂时性故障、服务不可用或限制,流分析将无限期重试以成功完成操作。 但它不会尝试对以下失败进行重试:
- 未经授权(HTTP 错误代码 401)
- NotFound(HTTP 错误代码 404)
- Forbidden(HTTP 错误代码 403)
- BadRequest(HTTP 错误代码 400)
常见问题
将向集合添加唯一索引约束,流分析的输出数据违反此约束。 请确保流分析的输出数据不违反唯一约束,或将约束删除。 有关详细信息,请参阅 Azure Cosmos DB 中的 唯一键约束。
PartitionKey列不存在。Id列不存在。