依赖于复制以实现高可用性、低延迟或两者的分布式数据库必须平衡 PACELC 定理定义的读取一致性、可用性、延迟和吞吐量。 强一致性模型的线性化是数据可编程性的标准。 但是,它会增加写入延迟,因为数据必须跨大距离复制和提交。 强一致性也会减少故障期间的可用性,因为数据无法在每个区域中复制和提交。 最终一致性提供更高的可用性和更好的性能,但更难对应用程序进行编程,因为数据可能在所有区域中都不一致。
目前市场上大多数分布式 NoSQL 数据库仅提供强一致性和最终一致性。 Azure Cosmos DB 提供五个妥善定义的级别。 按最强到最弱的顺序,级别分别为:
有关默认一致性级别的详细信息,请参阅配置默认一致性级别或覆盖默认一致性级别。
每个级别平衡可用性和性能。 下图显示了一致性级别作为范围。
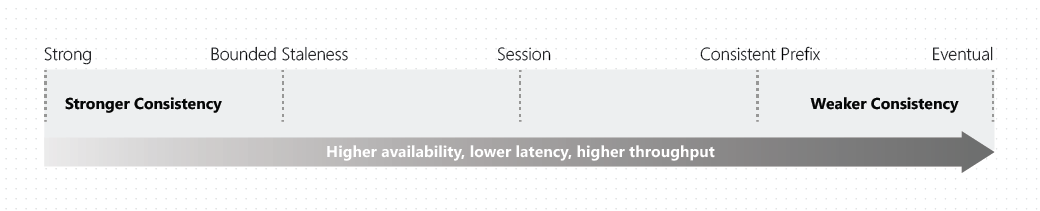
一致性级别和 Azure Cosmos DB API
Azure Cosmos DB 支持常用数据库的线路协议兼容 API,包括 MongoDB、Apache Cassandra、Apache Gremlin 和 Azure 表存储。 对于 Gremlin 或表的 API,Azure Cosmos DB 使用帐户上配置的默认一致性级别。 若要了解一致性级别映射,请参阅适用于 Apache Cassandra 的 API 的 Cassandra 一致性映射 ,以及 MongoDB 的用于 MongoDB 的用于 MongoDB 的 API 一致性映射 。
读取一致性的范围
读取一致性适用于逻辑分区中的单个读取作。 远程客户端、存储过程或触发器可以发出读取作。
配置默认一致性级别
随时在 Azure Cosmos DB 帐户上配置默认一致性级别。 在帐户中配置的默认一致性级别适用于该帐户下的所有 Azure Cosmos DB 数据库和容器。 针对某个容器或数据库发出的所有读取和查询默认使用指定的一致性级别。 更改帐户级别的一致性时,请重新部署应用程序并进行任何必要的代码修改以应用这些更改。 详细了解 如何配置默认一致性级别。 还可以替代特定请求的默认一致性级别。 在 重写默认一致性级别 文章中了解详细信息。
提示
重写默认一致性级别仅适用于 SDK 客户端中的读取。 默认情况下,为强一致性配置的帐户仍会同步写入数据并将其复制到帐户中的每个区域。 当 SDK 客户端实例或请求用会话或较弱一致性替代此一致性时,将使用单个副本执行读取。 有关详细信息,请参阅 一致性级别和吞吐量。
重要
通过重启应用程序,在更改默认一致性级别后重新创建任何 SDK 实例。 此步骤可确保 SDK 使用新的默认一致性级别。
与一致性级别关联的保证
Azure Cosmos DB 保证 100 个读取请求% 满足所选一致性级别的一致性保证。 Azure Cosmos DB 中使用 TLA - 临时作逻辑 - 规范语言在 Azure/azure-cosmos-tla GitHub 存储库中提供了五个一致性级别的精确定义。
以下部分描述了五个一致性级别的语义。
非常一致性
非常一致性提供可线性化保证。 线性化意味着同时为请求提供服务。 保证读取操作返回项的最新提交版本。 客户端永远不会看到未提交或不完整的写入。 始终保证用户读取最新确认的写入。
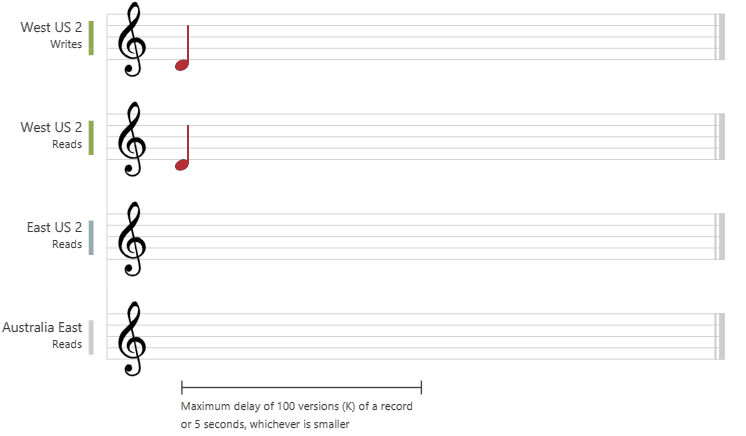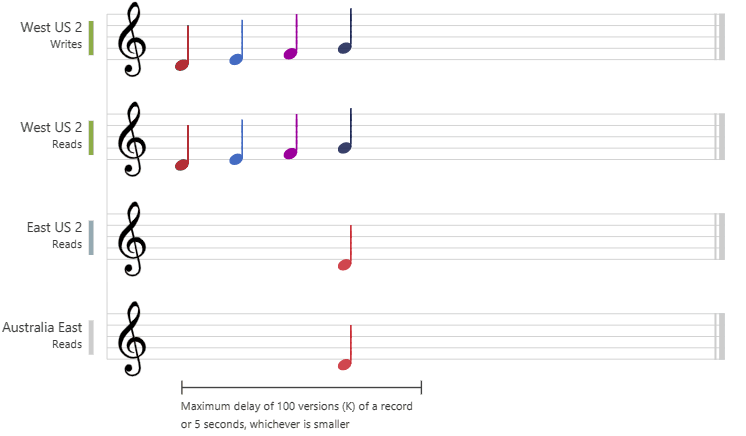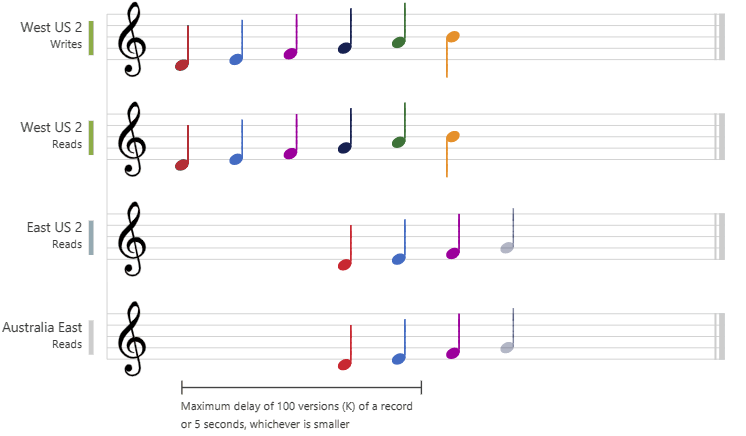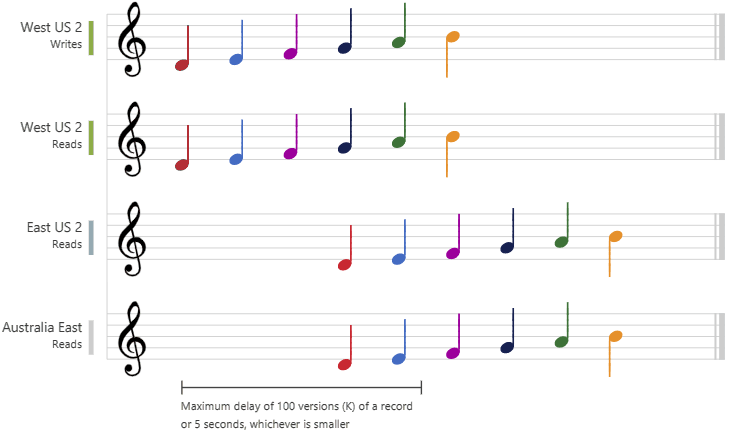
下图显示了与音乐笔记的强烈一致性。 将数据写入“中国北部 2”区域后,当你从其他区域读取这些数据时,将会获得最新的值:

动态仲裁
在正常情况下,对于具有强一致性的帐户,当所有区域确认记录复制时,都会将写入视为已提交。 如果帐户有三个或更多区域,则当某些区域缓慢或不响应时,系统可以降低仲裁所需的区域数。 即使几个区域出现问题,这也有助于保持高度一致性。 此时,无响应区域会从仲裁区域集中取出,以保持强一致性。 仅当它们与其他区域保持一致并按预期执行时,才会添加回它们。 可能从仲裁集中取出的区域数取决于区域总数。 例如,在三个或四个区域帐户中,多数分别为两个或三个区域,因此在任一情况下只能删除一个区域。 对于五个区域帐户,多数为三个,因此最多可以删除两个无响应区域。 此功能称为“动态仲裁”,可以改善具有三个或更多区域的帐户的写入可用性和复制延迟。
注意
从仲裁集中删除区域作为动态仲裁的一部分时,这些区域将无法再提供读取,直到读取到仲裁中。
有限过期一致性
对于具有两个或更多区域的单区域写入帐户,数据将从主要区域复制到所有次要(只读)区域。 对于具有两个或更多区域的多区域写入帐户,数据将从最初写入的区域复制到所有其他可写区域。 在这两种情况下,虽然并不常见,但有时复制滞后于一个区域到另一个区域。
在有限过期一致性中,任何两个区域之间的数据延迟始终小于指定量。 数量可以是“K”个项版本(即“更新”)或“T”时间间隔,以先达到者为准。 换言之,如果选择有限过期,则可以通过两种方式配置任何区域中数据的最大“过期”值:
- 项的版本数 (K)
- 时间间隔 (T) 读取操作可以滞后于写入操作
有限过期主要有利于具有两个或更多区域的单区域写入帐户。 如果某个区域中的数据延迟(按物理分区确定)超过了配置的过期值,将会限制该分区的写入,直到过期值重新处于配置的上限范围内。
对于单区域帐户,有限过期提供与会话和最终一致性相同的写入一致性保证。 使用有限过期,数据会复制到单区域中的本地多数副本(包含四个副本的副本集中的三个副本)。
重要
使用有限过期一致性时,过期检查仅在区域之间进行,而不是在某个区域内进行。 在给定区域中,无论一致性级别如何,数据始终复制到本地多数(四个副本集中的三个副本)。
使用有限过期时的读取将通过从该区域内的两个可用副本进行读取,返回该区域内的最新可用数据。 由于区域内的写入始终复制到本地多数副本(四个副本中的三个),因此,查询两个副本将返回该区域中可用的最新数据。
重要
使用有限过期一致性时,从非主要区域的读取可能不会显示来自所有区域的最新数据。 但是,在允许的过期限制内,它们始终返回该区域中可用的最新数据。
有限过期最适合使用某个单区域写入帐户(具有两个或两个以上区域)的多区域分布式应用程序,其中需要跨区域的准强一致性。 对于具有两个或更多区域的多区域写入帐户,应用程序服务器应将读取和写入定向到托管应用程序服务器的同一区域。 多写入帐户中的有限过期是一种反模式。 该级别需要依赖于区域之间的复制延迟,如果数据是从写入数据的同一区域中读取的,这就无关紧要。
下图以乐谱形式演示了有限过期一致性。 将数据写入“中国北部 2”区域后,“中国东部 2”和“澳大利亚东部”区域将会根据所配置的最大滞后时间或最大操作数目读取写入的值:
会话一致性
在会话一致性的单个客户端会话中,可以保证读取遵守“读取你的写入内容”和“读取后写入”。 此保证假定单个“编写器”会话或共享多个编写器的会话令牌。
与所有弱于非常一致性的级别一样,写入内容将复制到本地区域中的至少三个副本(在包含四个副本的集中),并异步复制到所有其他区域。
每次执行写入操作后,客户端将从服务器接收更新的会话令牌。 客户端缓存令牌,并将其发送到服务器,以便在指定区域进行读取操作。 如果对其发出读取操作的副本包含指定的令牌(或时间更新的令牌)的数据,则返回请求的数据。 如果副本不包含该会话的数据,客户端将对该区域中的另一个副本重试请求。 如果需要,客户端将对其他可用区域重试读取,直到检索到指定的会话令牌的数据。
重要
在会话一致性中,客户端使用会话令牌保证它永远不会读取与旧会话对应的数据。 如果客户端使用旧会话令牌,但数据库中提供了较新的数据,则系统会返回最新版本。 即使使用过时的令牌,你也会始终获得最新的数据。 会话令牌用作最低版本屏障,而不是用作要从数据库中检索的数据的特定版本(可能是历史版本)。
Azure Cosmos DB 中的会话令牌是分区绑定的,这意味着它们只与一个分区相关联。 为了确保可以读取写入,请使用上次为相关项生成的会话令牌。
如果客户端未启动对物理分区的写入,它就不会在其缓存中包含会话令牌,并且对该物理分区的读取会表现为具有最终一致性的读取。 同样,如果重新创建了客户端,也会重新创建其会话令牌的缓存。 在此处,读取操作也将遵循与最终一致性相同的行为,直到后续的写入操作重新生成客户端的会话令牌缓存。
重要
如果将会话令牌从一个客户端实例传递到另一个客户端实例,则不应修改令牌的内容。
会话一致性是单区域和多区域分布式应用程序的最广泛使用的一致性级别。 它提供与最终一致性相当的写入延迟、可用性和读取吞吐量。 会话一致性还提供一致性保证,从而满足用于在用户上下文中操作的应用程序的需求。 下图以乐谱形式演示了会话一致性。 “中国北部 2 写入器”和“中国东部 2 读取器”正在使用同一个会话(会话 A),因此它们会同时读取相同的数据。 而“中国北部 2”区域使用“会话 B”,因此,它稍后会接收数据,但接收数据的顺序与写入顺序一致。

一致前缀一致性
与所有弱于非常一致性的级别一样,写入内容将复制到本地区域中的至少三个副本(在包含四个副本的集中),并异步复制到所有其他区域。
在一致的前缀中,作为单个文档写入进行的更新将实现最终一致性。
对于在事务中作为批处理进行的更新,返回时将与提交它们的事务一致。 多文档事务中的写入操作始终一起可见。
假设在事务 T1 和 T2 中,以事务方式依次对文档 Doc1 和文档 Doc2 执行两个写入操作(全有或全无操作)。 当客户端在任何副本中执行读取时,如果副本滞后,则用户会看到“Doc1 v1 和 Doc2 v1”或“Doc1 v2 v2”或“Doc1 v2 v2”或“Doc1 v2 v1”,或“Doc1 v2 和 Doc2 v1”以获取相同的读取或查询作。
下图以乐谱形式演示了一致前缀一致性。 在所有区域中,读取永远不会看到事务写入批的无序写入:

最终一致性
与所有弱于非常一致性的级别一样,写入内容将复制到本地区域中的至少三个副本(在包含四个副本的集中),并异步复制到所有其他区域。
在最终一致性中,客户端对指定区域内四个副本中的任何一个发出读取请求。 此副本可能会滞后,并且可能会返回过时或不返回任何数据。
最终一致性是最弱的一致性形式,因为客户端可能会读取早于过去读取的值。 最终一致性非常适合于应用程序不需要任何顺序保证的情况。 示例包括 Retweets、Likes 或非线程注释的计数。 下图以乐谱形式演示了最终一致性。

一致性保证的实践
在实践中,你可能会获得更严格的一致性保证。 读取操作的一致性保证对应于所请求的数据库状态的新旧程度和顺序。 读取一致性与写入和更新作的排序和传播相关联。
如果数据库上没有写入作,则 具有最终、 会话或 一致的前缀一致性 级别的读取作可能会产生与具有强一致性级别的读取作相同的结果。
如果帐户配置了强一致性以外的一致性级别,则可以找出客户端可能会为工作负荷获得强且一致的读取的可能性。 通过查看 概率有限过期(PBS) 指标来找出这种概率。 此指标在 Azure 门户中公开。 有关详细信息,请参阅 “监视概率有限过期(PBS)”指标。
概率有限过期显示了最终一致性的最终程度。 此指标可深入了解与 Azure Cosmos DB 帐户上当前配置的一致性级别相比,获得更强一致性的频率。 换句话说,可看到获得写入和读取区域组合的一致读取的概率(以毫秒计量)。
一致性级别和延迟
保证所有一致性级别的读取延迟在 99 百分位时小于 10 毫秒。 平均读取延迟(第 50 百分位)通常为 4 毫秒或更少。
保证所有一致性级别的写入延迟在 99 百分位时小于 10 毫秒。 平均写入延迟(第 50 百分位)通常为 5 毫秒或更少。 跨多个区域且具有强一致性的 Azure Cosmos DB 帐户是此保证的例外。
写入延迟和非常一致性
对于配置了与多个区域具有非常一致性的 Azure Cosmos DB 帐户,写入延迟等于任意两个最远区域区域之间的往返时间 (RTT) 的两倍,加上第 99 个百分位数处的 10 毫秒。 区域之间的高网络 RTT 会增加 Azure Cosmos DB 请求延迟,因为强一致性仅在确保作提交到帐户中的所有区域后才能完成作。
确切的 RTT 延迟取决于光速距离和 Azure 网络拓扑。 Azure 网络不会为 Azure 区域之间的 RTT 提供延迟服务级别协议(SLA),但它发布 Azure 网络往返延迟统计信息。 对于 Azure Cosmos DB 帐户,将在 Azure 门户中显示复制延迟。 转到“指标”部分并选择“ 一致性 ”选项,使用 Azure 门户。 使用 Azure 门户可以监视与你的 Azure Cosmos DB 帐户关联的各个区域之间的复制延迟。
重要
由于写入延迟较高,默认会阻止跨 5,000 英里(8,000 公里)的帐户保持高度一致性。 若要启用此功能,请联系支持人员。
一致性级别和吞吐量
对于强过期和有限过期,读取针对四个副本集(少数仲裁)中的两个副本执行,以确保一致性保证。 会话、一致前缀和最终一致性使用单副本读取。 因此,对于相同数量的请求单位,强过期和有限过期的读取吞吐量是其他一致性级别的一半。
对于给定类型的写入作(如插入、替换、更新插入或删除),请求单位的写入吞吐量在所有一致性级别上都是相同的。 为了保持高度一致性,必须在每个区域(全局多数)提交更改,而对于所有其他一致性级别,将使用本地多数(四个副本集中的三个副本)。
| 一致性级别 | 仲裁读取 | 仲裁写入 |
|---|---|---|
| 非常 | 本地少数 | 全局多数 |
| 有限过期 | 本地少数 | 本地多数 |
| 会话 | 单个副本(使用会话令牌) | 本地多数 |
| 一致前缀 | 单个副本 | 本地多数 |
| 最终 | 单个副本 | 本地多数 |
注意
本地少数读取的 RU 成本是较弱一致性级别的两倍,因为读取是从两个副本进行的,以确保强过期一致性级别的一致性保证。
一致性级别和数据持续性
在多区域分布式数据库环境中,一致性级别直接影响到区域范围的服务中断期间的数据持续性。 开发业务连续性计划时,了解应用程序在从中断事件恢复期间可以容忍的最新数据更新的最大期限。 可能会丢失的更新的时间段称为 恢复点目标 (RPO)。
此表显示区域范围的服务中断期间一致性模型和数据持续性之间的关系。
| Regions | 复制模式 | 一致性级别 | RPO |
|---|---|---|---|
| 1 | 单个或多个写入区域 | 任何一致性级别 | < 240 分钟 |
| >1 | 单个写入区域 | 会话、一致的前缀或最终 | < 15 分钟 |
| >1 | 单个写入区域 | 有限过期 | K 和 T |
| >1 | 单个写入区域 | 非常 | 0 |
| >1 | 多个写入区域 | 会话、一致的前缀或最终 | < 15 分钟 |
| >1 | 多个写入区域 | 有限过期 | K 和 T |
K = 项的 K 版本数(更新)。
T = 自上次更新以来的时间间隔 T 。
对于单区域帐户, K 和 T 的最小值为 10 个写入作或 5 秒。 对于多区域帐户, K 和 T 的最小值为 100,000 个写入作或 300 秒。 使用有限过期时,此值定义数据的最低恢复点目标 (RPO)。
非常一致性和多个写入区域
具有多个写入区域的 Azure Cosmos DB 帐户无法使用强一致性,因为分布式系统无法提供零的恢复点目标(RPO)和零的恢复时间目标(RTO)。 此外,与多个写入区域的强一致性不会改善写入延迟,因为必须复制写入并将其提交到帐户中的所有区域。 此设置会导致与单写入区域帐户相同的写入延迟。
进一步阅读
若要详细了解一致性的概念,请阅读以下文章: