Important
从 2023 年 9 月 20 日起,将无法创建新的异常检测器资源。 异常检测器服务将于 2026 年 10 月 1 日停用。
异常检测器 API是无状态异常情况检测服务。 其结果的准确度和表现可能受以下因素影响:
- 准备时序数据的方式。
- 所使用的异常检测器 API参数。
- API 请求中的数据点数目。
通过本文了解使用 API 针对你的数据获取最佳结果的最佳做法。
何时使用批量(全部数据)点异常检测或最新(最后数据)点异常检测。
异常检测器 API的批处理检测终结点允许通过整个时序数据检测异常。 在此检测模式下,需创建单个统计模型,并将其应用于数据集中的每个点。 如果时序具有以下特征,建议使用批量检测在一个 API 调用中预览数据。
- 周期性时序,偶尔会出现异常。
- 平缓趋势时序,偶尔会出现峰值/谷值。
不建议在实时数据监视中使用批量异常情况检测,也不建议在不具备上述特征的时序数据中使用它。
批量检测仅创建并应用一个模型,对每个点的检测都是在整个序列的上下文中完成的。 如果时序数据上下起伏且没有周期性,则模型可能会错过一些变化点(数据中的峰值和谷值)。 类似地,如果某些变化点的变化不如数据集中后面的变化点的变化那么明显,系统可能会认为它们的变化不够明显,因此不会将它们纳入模型中。
进行实时数据监视时,由于分析的点数量较多,因此批量检测比检测最新点的异常状态要慢。
对于实时数据监视,建议只检测最新数据点的异常状态。 通过持续应用最新点检测,可以更有效、更准确地进行流数据监视。
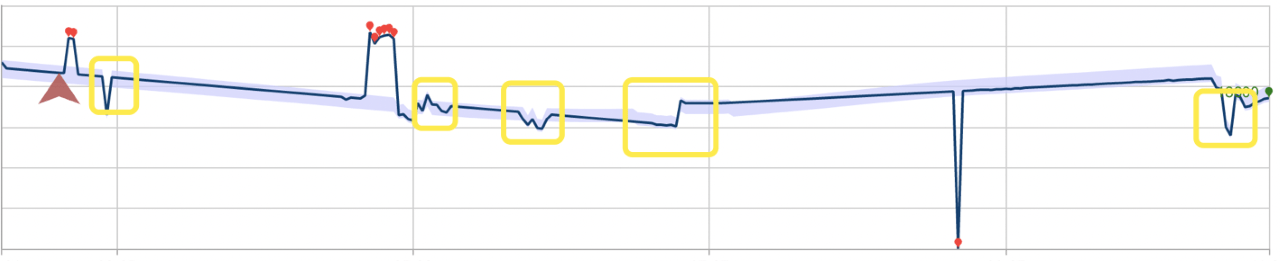
下面的示例描述了这些检测模式可能会对性能造成的影响。 第一张图显示了沿着 28 个先前看到的数据点连续检测最新点异常状态的结果。 红色点为异常。

下面是使用批量异常情况检测的同一数据集。 为此操作构建的模型忽略了几个异常(使用矩形进行了标记)。
数据准备工作
异常检测器 API接受格式化为 JSON 请求对象的时序数据。 时序可以是在一段时间内按顺序记录的任何数值数据。 可以将时序数据的时间窗口发送到 异常检测器 API 终结点,以提升 API 的性能。 可以发送的最少数据点数为 12 个,最多数据点数为 8640 个。 粒度定义为数据采样速率。
发送到异常检测器 API的数据点必须具有有效的协调世界时(UTC)时间戳和数值。
{
"granularity": "daily",
"series": [
{
"timestamp": "2018-03-01T00:00:00Z",
"value": 32858923
},
{
"timestamp": "2018-03-02T00:00:00Z",
"value": 29615278
},
]
}
如果数据按非标准时间间隔采样,可以通过在请求中添加 customInterval 属性来指定该时间间隔。 例如,如果你的序列每 5 分钟进行一次采样,则可将以下内容添加到 JSON 请求:
{
"granularity" : "minutely",
"customInterval" : 5
}
缺少数据点
在均匀分布的时序数据集中,缺失的数据点很常见,尤其是在细粒度的数据集中(例如,采样时间间隔很小,每几分钟对数据进行一次采样)。 缺少的点数少于数据中预期点数的 10% 不会对检测结果产生负面影响。 请考虑根据数据的特征来填补数据中的空白,例如,将其替换为早期的数据点、线性内插值或移动平均值。
聚合分布的数据
异常检测器 API最适用于均匀分布的时序。 如果数据是随机分布的,则应按某个时间单位(例如每分钟、每小时或每天)进行聚合。
对具有周期性模式的数据进行异常情况检测
如果你知道时序数据具有周期性模式(定期出现的模式),则可提高准确度和缩短 API 响应时间。
在构造 JSON 请求时指定 period 可以将异常情况检测延迟降低多达 50%。
period 是一个整数,它指定时序大约采用多少个数据点来重复某个模式。 例如,每天有一个数据点的时序的 period 为 7,而每小时有一个数据点的时序(具有相同的每周模式)的 period 为 7*24。 如果你不确定数据的模式,则无需指定此参数。
为获得最佳结果,请提供四个 period 的数据点,再额外添加一个数据点。 例如,上述具有每周模式的每小时数据应当在请求正文中提供 673 个数据点 (7 * 24 * 4 + 1)。
为实时监视对数据进行采样
如果流数据以较短的间隔(例如秒或分钟)进行采样,那么发送建议的数据点数可能会超过 异常检测器 API 允许的最大上限(8640 个数据点)。 如果你的数据表现出稳定的周期性模式,请考虑以较大的时间间隔(例如小时)发送时序数据的样本。 以这种方式对数据进行采样还可以显著缩短 API 响应时间。