Important
截至2026年5月18日,Azure AI 指标顾问已退休。
建议使用以下替代方法:
- Azure Monitor,作为官方Azure 3P 产品,通过多个接口提供异常检测和分析功能。
- 开源异常检测器,此开源项目提供与 Kensho、Azure 指标顾问和 Azure 异常检测器在后端中相同的异常检测功能。
本教程中,您将学习如何:
- 如何编写有效的数据加入查询
- 常见错误及其规避方法
先决条件
创建“指标顾问”资源
若要了解指标顾问的功能,可能需要在Azure门户中创建指标顾问资源来部署指标顾问实例。
数据架构要求
Azure AI 指标顾问是用于时序异常情况检测、诊断和分析的服务。 作为由 AI 提供支持的服务,它使用你的数据来训练所使用的模型。 服务接受具有以下各列的聚合数据表:
- 度量值(必需):度量值是一个基本术语或单位特定的术语,是指标的可量化值。 它指一个或多个包含数值的列。
-
时间戳(可选):可以有零列或一列,其类型为
DateTime或String。 如果未设置此列,则时间戳将设置为每个引入周期的开始时间。 设置时间戳的格式,如下所示:yyyy-MM-ddTHH:mm:ssZ。 - 维度(可选):维度是一个或多个分类值。 这些值的组合标识特定的单变量时序(例如国家/地区、语言、租户等)。 维度列可以是任意数据类型。 处理大量的列和值时要格外小心,应避免处理过多的维度。
如果使用数据源(如Azure Data Lake Storage或Azure Blob 存储),则可以聚合数据,使其与预期的指标架构保持一致。 这是因为这些数据源使用文件作为指标输入。
如果使用数据源(如Azure SQL或Azure 数据资源管理器),则可以使用聚合函数将数据聚合到预期的架构中。 这是因为这些数据源支持通过运行查询来从源获取指标数据。
“指标顾问”中的数据引入原理
将指标接入指标顾问通常有两种方法:
- 将指标预先聚合到预期的架构中,并将数据存储到某些文件中。 在加入过程中填写路径模板,“指标顾问”将从该路径持续获取新文件,并对指标执行检测。 这是数据源(如Azure Data Lake和Azure Blob 存储)的常见做法。
- 如果要从 Azure SQL Server、Azure 数据资源管理器 或其他支持使用查询脚本的数据源引入数据,则需要确保正确构造查询。 本文将指导如何编写有效的查询以按预期加入指标数据。
什么是时间间隔?
根据业务需求,指标需要以某种精确度进行监视。 例如,业务关键绩效指标 (KPI) 以天为单位进行监控。 但是,服务性能指标常常按分钟/小时的粒度进行监视。 因此,从源收集指标数据的频率各有不同。
“指标顾问”按每个时间间隔持续收集指标数据,该时间间隔等同于指标的粒度。指标顾问每次会在此特定时间间隔内运行您编写的查询,以摄取数据。 根据此数据引入机制,查询脚本不应返回数据库中存在的所有指标数据,而需将结果限制为单个时间间隔内。
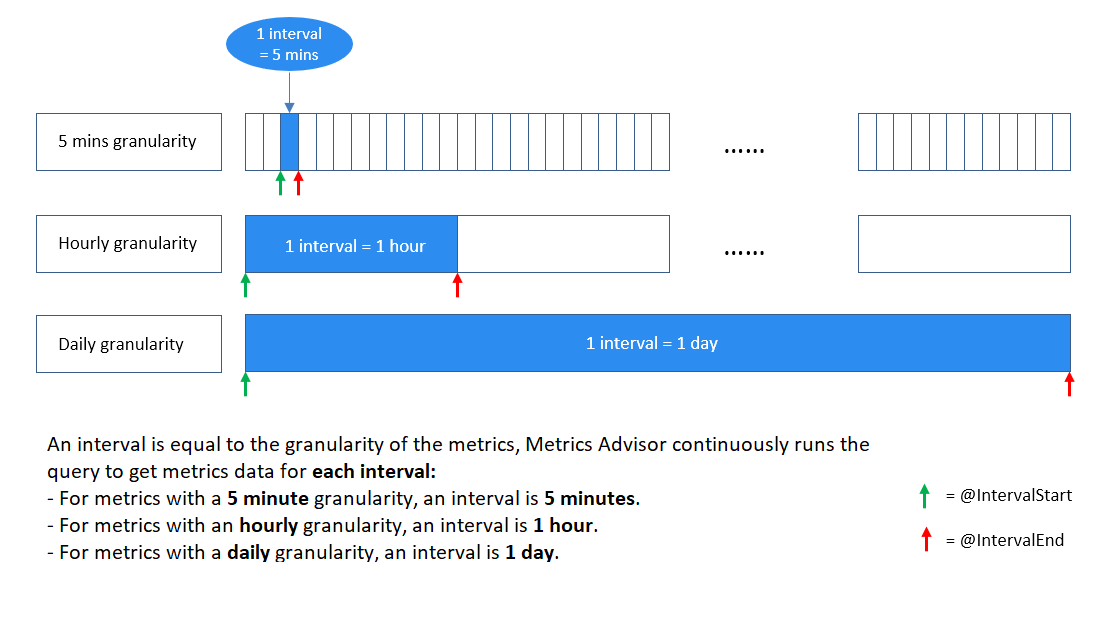
如何编写有效查询?
Use @IntervalStart and @IntervalEnd to limit query results
为了帮助实现这一点,提供两个在查询中使用的参数:@IntervalStart 和 @IntervalEnd。
每次运行查询时,都会将 @IntervalStart 和 @IntervalEnd 自动更新为最新的时间间隔时间戳并获取相应的指标数据。 @IntervalEnd 始终被定义为 @IntervalStart + 1 粒度。
下面是在 Azure SQL Server中正确使用这两个参数的示例:
SELECT [timestampColumnName] AS timestamp, [dimensionColumnName], [metricColumnName] FROM [sampleTable] WHERE [timestampColumnName] >= @IntervalStart and [timestampColumnName] < @IntervalEnd;
采用这种方式编写查询脚本后,指标的时间戳应在每个查询结果的时间间隔内。 “指标顾问”会自动将时间戳与指标粒度对齐。
使用聚合函数来聚合指标
通常情况下,客户数据源中包含许多列,但并不是所有列都可以作为维度去监视或纳入。 客户可以使用聚合函数来聚合指标并仅包含有意义的列作为维度。
在下面的示例中,客户的数据源包含超过 10 列的数据,但只有少量列有意义且需要包含并聚合到要监视的指标中。
| TS | 市场 | 设备操作系统 | 类别 | ... | Measure1 | Measure2 | Measure3 |
|---|---|---|---|---|---|---|---|
| 2020-09-18T12:23:22Z | 纽约 | iOS | 太阳眼镜 | ... | 43242 | 322 | 54546 |
| 2020-09-18T12:27:34Z | Beijing | Android | 包包 | ... | 3333 | 126 | 67677 |
| ... |
如果客户想要按小时粒度监视“Measure1”,并选择“Market”和“Category”作为维度,以下示例介绍了如何正确使用聚合函数来实现此目的:
SQL 示例:
SELECT dateadd(hour, datediff(hour, 0, TS),0) as NewTS ,Market ,Category ,sum(Measure1) as M1 FROM [dbo].[SampleTable] where TS >= @IntervalStart and TS < @IntervalEnd group by Market, Category, dateadd(hour, datediff(hour, 0, TS),0)Azure 数据资源管理器示例:
SampleTable | where TS >= @IntervalStart and TS < @IntervalEnd | summarize M1 = sum(Measure1) by Market, Category, NewTS = startofhour(TS)
注释
在上例中,客户想要以小时为粒度监视指标,但原始时间戳 (TS) 未对齐。 在聚合语句中,需要对时间戳执行一个过程使其按小时对齐,并生成一个名为“NewTS”的新时间戳列。
加入过程中的常见错误
错误: 在查询结果中找到多个时间戳值
这是常见错误,原因是未将查询结果限制在某个时间间隔内。 例如,如果您正在以天为单位的粒度监控指标,当查询返回的结果如下所示时,就会出现此错误:
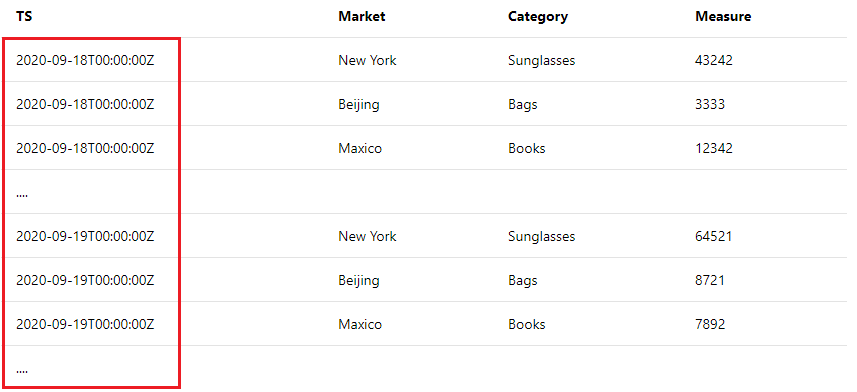
包含多个时间戳值,且这些值不在指标的同一个时间间隔中(一天)。 请查看“指标顾问”中的数据引入原理,了解“指标顾问”将获取每个指标时间间隔内的指标数据。 然后,请确保在查询中使用 @IntervalStart 和 @IntervalEnd,以将结果限制在一个时间间隔内。 查看 Use @IntervalStart and @IntervalEnd to limit query results 以了解详细指南和示例。
错误: 在一个指标时间间隔内的同一个维度组合中发现重复的指标值
在一个时间间隔内,Metrics Advisor 期望同一维度组合只有一个指标值。 例如,如果您正在以天为单位的粒度监控指标,当查询返回的结果如下所示时,就会出现此错误:
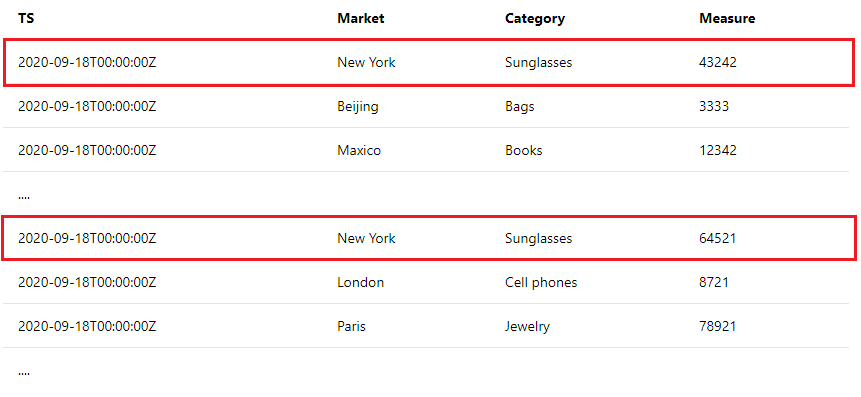
有关详细指导和示例,请参阅使用聚合函数来聚合指标。
后续步骤
转到下一篇文章,了解如何创建。