重要
Azure SQL Edge 将于 2025 年 9 月 30 日停用。 有关详细信息和迁移选项,请参阅停用通知。
注意
Azure SQL Edge 不再支持 ARM64 平台。
本教程演示了如何使用 Azure 数据工厂以增量方式将数据从 Azure SQL Edge 实例中的表同步到 Azure Blob 存储。
开始之前
如果你还没有在 Azure SQL Edge 部署中创建数据库或表,请使用以下方法之一来创建一个:
使用 SQL Server Management Studio 或 Azure Data Studio 连接到 SQL Edge。 运行 SQL 脚本创建数据库和表。
通过直接连接到 SQL Edge 模块,使用 sqlcmd 创建数据库和表。 有关详细信息,请参阅使用 sqlcmd 连接到数据库引擎。
使用 SQLPackage.exe 将 DAC 包文件部署到 SQL Edge 容器。 将 SqlPackage 文件 URI 指定为模块所需属性配置的一部分可以自动化此过程。 也可以直接使用 SqlPackage.exe 客户端工具将 DAC 包部署到 SQL Edge。
有关如何下载 SqlPackage.exe 的详细信息,请参阅下载和安装 sqlpackage。 以下是适用于 SqlPackage.exe 的一些示例命令。 有关详细信息,请参阅 SqlPackage.exe 文档。
创建 DAC 包
sqlpackage /Action:Extract /SourceConnectionString:"Data Source=<Server_Name>,<port>;Initial Catalog=<DB_name>;User ID=<user>;Password=<password>" /TargetFile:<dacpac_file_name>应用 DAC 包
sqlpackage /Action:Publish /Sourcefile:<dacpac_file_name> /TargetServerName:<Server_Name>,<port> /TargetDatabaseName:<DB_Name> /TargetUser:<user> /TargetPassword:<password>
创建 SQL 表和过程用于存储和更新水印级别
水印表用于存储上次将数据同步到 Azure 存储时的时间戳。 Transact-SQL (T-SQL) 存储过程用于在每次同步后更新水印表。
在 SQL Edge 实例上运行以下命令:
CREATE TABLE [dbo].[watermarktable] (
TableName VARCHAR(255),
WatermarkValue DATETIME,
);
GO
CREATE PROCEDURE usp_write_watermark @timestamp DATETIME,
@TableName VARCHAR(50)
AS
BEGIN
UPDATE [dbo].[watermarktable]
SET [WatermarkValue] = @timestamp
WHERE [TableName] = @TableName;
END
GO
创建数据工厂管道
在此部分中,你将创建一个 Azure 数据工厂管道,用于将数据从 Azure SQL Edge 中的表同步到 Azure Blob 存储。
使用数据工厂 UI 创建数据工厂
按照本教程中的说明创建数据工厂。
创建数据工厂管道
在数据工厂 UI 的“开始使用”页上,选择“创建管道” 。

在管道“属性”窗口的“常规”页上,输入名称 PeriodicSync 。
添加“查找”活动用于获取旧水印值。 在“活动”窗格中展开“常规”,将“查找”活动拖动到管道设计器图面 。 将活动的名称更改为 OldWatermark。
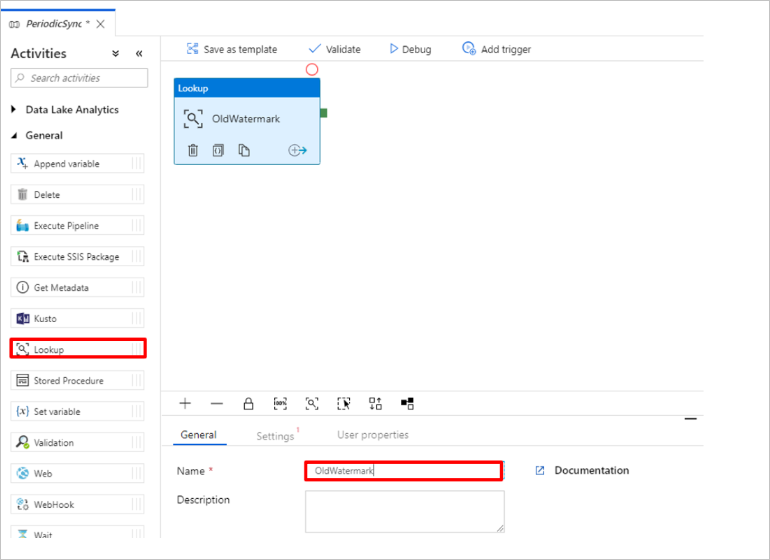
切换到“设置”选项卡,选择“源数据集”对应的“新建” 。 现在,你将创建一个代表水印表中的数据的数据集。 此表包含在前一复制操作中使用过的旧水印。
在“新建数据集”窗口中,依次选择“Azure SQL Server”、“继续” 。
在数据集“设置属性”窗口的“名称”下,输入 WatermarkDataset 。
对于“链接服务”,选择“新建”,然后完成下列步骤 :
在“名称”下,输入 SQLDBEdgeLinkedService 。
在“服务器名称”下,输入 SQL Edge 服务器详细信息。
从列表中选择“数据库名称”。
输入用户名和密码。
若要测试与 SQL Edge 实例的连接,请选择“测试连接”。
选择创建。
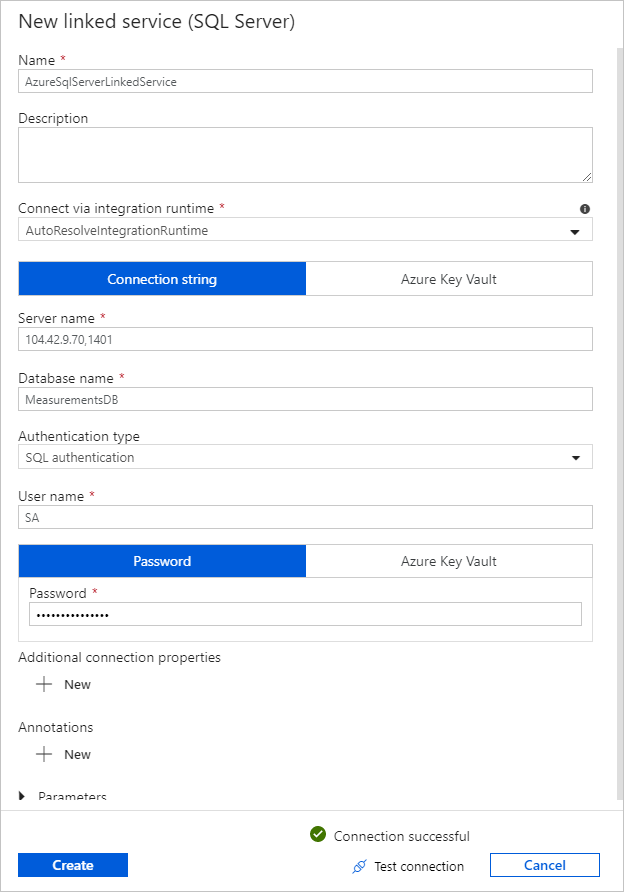
选择“确定”。
在“设置”选项卡中选择“编辑” 。
在“连接”选项卡中,对于“表”,选择
[dbo].[watermarktable]。 若要预览表中的数据,请选择“预览数据”。通过选择顶部的管道选项卡,或者选择左侧树状视图中管道的名称,切换到管道编辑器。 在“查找”活动的属性窗口中,确认在“源数据集”列表中选择了“WatermarkDataset” 。
在“活动”窗格中展开“常规”,将另一个“查找”活动拖动到管道设计器图面 。 在属性窗口的“常规”选项卡中,将名称设置为 NewWatermark 。 此“查找”活动从包含源数据的表获取新的水印值,因此源数据可以复制到目标。
在第二个“查找”活动的属性窗口中切换到“设置”选项卡,然后选择“新建”以创建一个数据集,该数据集指向包含新水印值的源表 。
在“新建数据集”窗口中,依次选择 SQL Edge 实例和“继续”。
在“设置属性”窗口的“名称”下,输入 SourceDataset 。 在“链接服务”下,选择 SQLDBEdgeLinkedService 。
在“表”下,选择要同步的表。 你还可以按本教程稍后所述,为此数据集指定查询。 此查询优先于在此步骤中指定的表。
选择“确定”。
通过选择顶部的管道选项卡,或者选择左侧树状视图中管道的名称,切换到管道编辑器。 在“查找”活动的属性窗口中,确认在“源数据集”列表中选择了“SourceDataset” 。
在“使用查询”下,选择“查询” 。 在以下查询中更新表名称,然后输入查询。 仅从表中选择
timestamp的最大值。 确保选择“仅第一行”。SELECT MAX(timestamp) AS NewWatermarkValue FROM [TableName];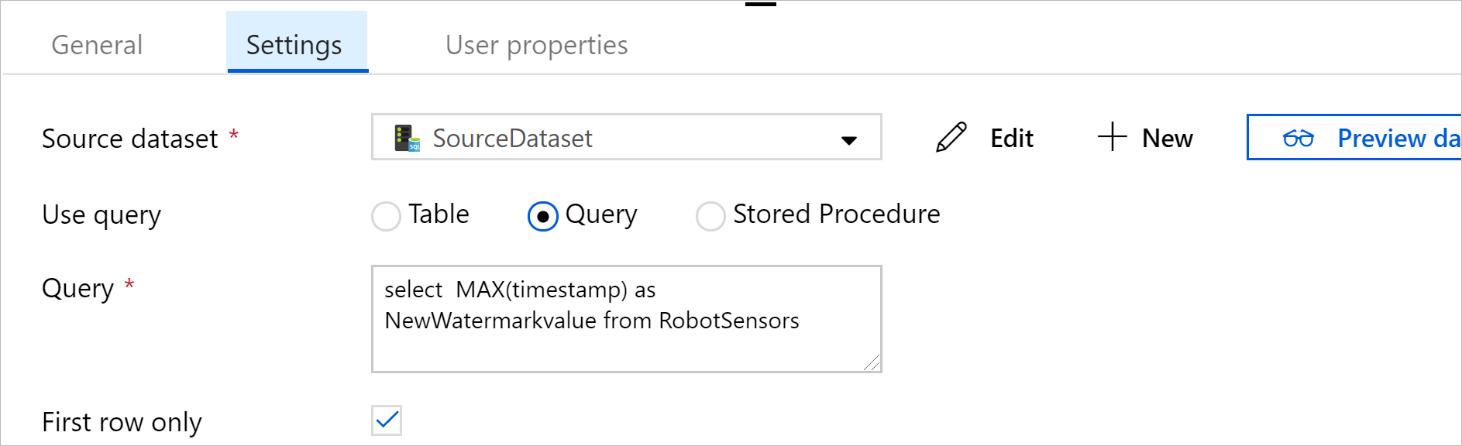
在“活动”窗格中,展开“移动和转换”,然后将“复制”活动从“活动”窗格拖动到设计器图面。 将活动的名称设置为 IncrementalCopy。
通过将附加到“查找”活动的绿色按钮拖动到“复制”活动,将两个“查找”活动都连接到“复制”活动。 看到“复制”活动的边框颜色变为蓝色时,松开鼠标按键。
选择“复制”活动,确认“属性”窗口中已显示该活动的属性。
在“属性”窗口中切换到“源”选项卡,然后完成以下步骤 :
在“源数据集”框中,选择“SourceDataset” 。
在“使用查询”下,选择“查询” 。
在“查询”框中,输入 SQL 查询。 下面是一个示例查询:
SELECT * FROM TemperatureSensor WHERE timestamp > '@{activity(' OldWaterMark ').output.firstRow.WatermarkValue}' AND timestamp <= '@{activity(' NewWaterMark ').output.firstRow.NewWatermarkvalue}';在“接收器”选项卡的“接收器数据集”下,选择“新建” 。
在本教程中,接收器数据存储为 Azure Blob 存储数据存储。 选择“Azure Blob 存储”,然后在“新建数据集”窗口中选择“继续” 。
在“选择格式”窗口中选择数据的格式,然后选择“继续” 。
在“设置属性”窗口的“名称”下,输入 SinkDataset 。 在“链接服务”下,选择“新建” 。 现在,你将创建一个连接(链接服务),用于连接到 Azure Blob 存储。
在“新建链接服务(Azure Blob 存储)”窗口中完成以下步骤:
在“名称”框中,输入 AzureStorageLinkedService 。
在“存储帐户名称”中,为 Azure 订阅选择 Azure 存储帐户。
测试连接,然后选择“完成”。
在“设置属性”窗口的“链接服务”下,确认选择了 AzureStorageLinkedService 。 依次选择“创建”、“确定” 。
在“接收器”选项卡中选择“编辑” 。
转到 SinkDataset 的“连接”选项卡,然后完成以下步骤:
在“文件路径”下,输入
asdedatasync/incrementalcopy,其中asdedatasync是 Blob 容器名称,incrementalcopy是文件夹名称。 创建容器(如果不存在),或者使用现有容器的名称。 Azure 数据工厂会自动创建输出文件夹incrementalcopy(如果不存在)。 对于“文件路径”,也可使用“浏览”按钮导航到 Blob 容器中的某个文件夹。对于“文件路径”的“文件”部分,选择“添加动态内容 [Alt+P]”,然后在打开的窗口中输入
@CONCAT('Incremental-', pipeline().RunId, '.txt')。 选择“完成”。 文件名是使用表达式动态生成的。 每次管道运行都有唯一的 ID。 “复制”活动使用运行 ID 生成文件名。
通过选择顶部的管道选项卡,或者选择左侧树状视图中管道的名称,切换到管道编辑器。
在“活动”窗格中,展开“常规”,然后将“存储过程”活动从“活动”窗格拖动到管道设计器图面 。 将“复制”活动的绿色(成功)输出连接到“存储过程”活动。
在管道设计器中选择“存储过程活动”,将其名称更改为
SPtoUpdateWatermarkActivity。切换到“SQL 帐户”选项卡,选择“链接服务”下的“*QLDBEdgeLinkedService” 。
切换到“存储过程”选项卡,然后完成以下步骤:
在“存储过程名称”下,选择
[dbo].[usp_write_watermark]。若要指定存储过程参数的值,选择“导入参数”,然后为参数输入以下值:
名称 类型 值 LastModifiedTime DateTime @{activity('NewWaterMark').output.firstRow.NewWatermarkvalue}TableName 字符串 @{activity('OldWaterMark').output.firstRow.TableName}若要验证管道设置,请选择工具栏中的“验证”。 确认没有任何验证错误。 若要关闭“管道验证报告”窗口,请选择 >>。
选择“全部发布”按钮,将实体(链接服务、数据集和管道)发布到 Azure 数据工厂服务。 请等待,直到确认发布操作已成功的消息出现。
根据计划触发管道
在管道工具栏中选择“添加触发器”,然后依次选择“新建/编辑”、“新建” 。
将触发器命名为 HourlySync。 在“类型”下,选择“计划” 。 将“重复周期”设置为每小时一次。
选择“确定”。
选择“全部发布”。
选择“立即触发”。
在左侧切换到“监视”选项卡。 可以看到手动触发器触发的管道运行的状态。 选择“刷新”可刷新列表。
## 相关内容
- 本教程中的 Azure 数据工厂管道每小时将数据从 SQL Edge 实例中的表复制到 Azure Blob 存储中的某个位置一次。 若要了解如何在其他方案中使用数据工厂,请参阅这些教程。