适用于: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
本快速入门介绍如何使用 Azure Data Factory Studio 或 Azure 门户 UI创建数据工厂。
如果你不熟悉Azure Data Factory,请在试用本快速入门之前,先参阅服务简介。
先决条件
- 如果没有Azure订阅,请在开始前创建一个 trial 帐户。
- 请确保具有创建数据工厂所需的Azure角色。 有关详细信息,请参阅 Azure 数据工厂的角色和权限。
在 Azure Data Factory Studio 中创建数据工厂
使用 Azure Data Factory Studio,可以在几秒钟内创建数据工厂:
打开Microsoft Edge或 Google Chrome Web 浏览器。 目前,只有这些浏览器支持数据工厂 UI。
转到 Azure Data Factory Studio并选择 创建新的数据工厂选项。
可以使用新数据工厂的默认值。 或者,可以选择唯一的名称、首选位置和特定订阅。 完成这些详细信息后,选择“ 创建”。
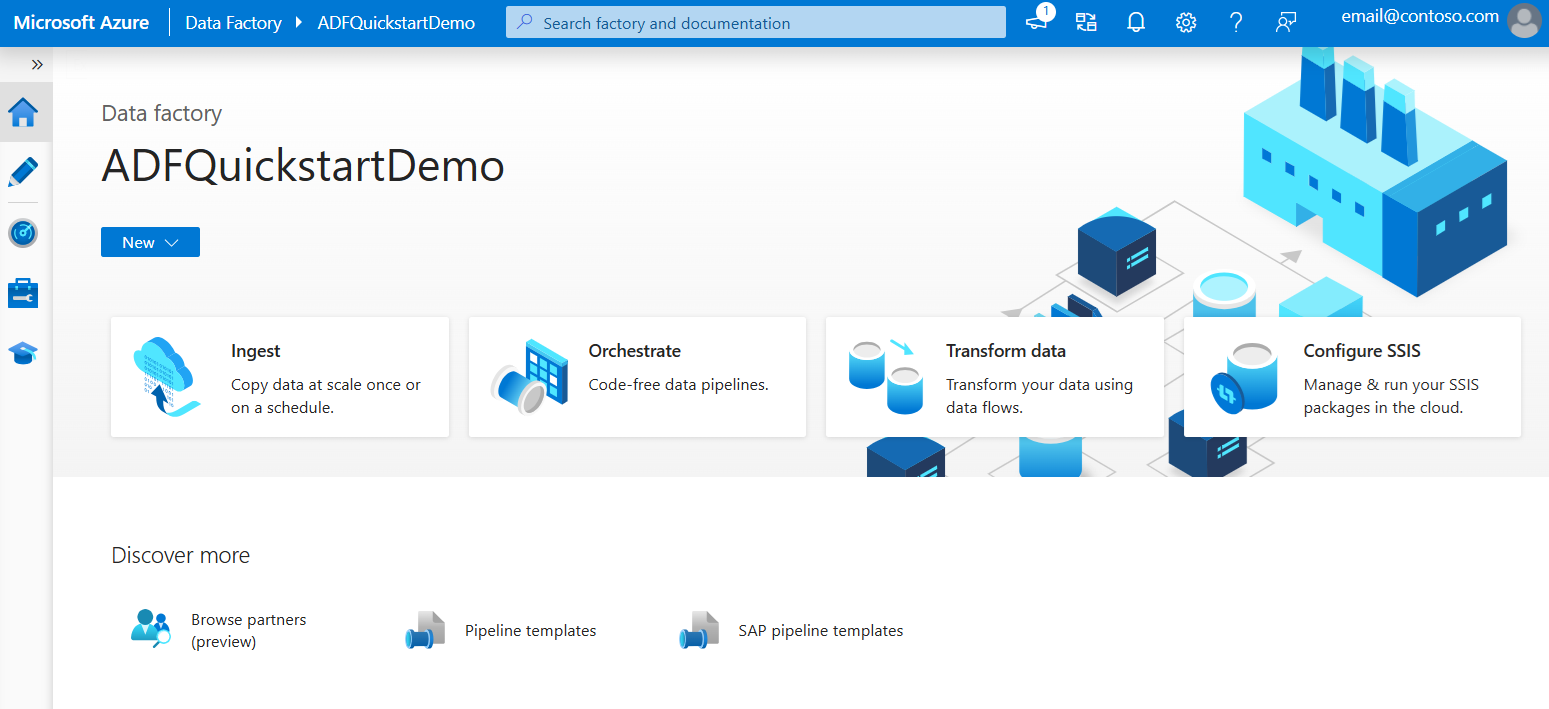
创建数据工厂后,您将被带到 Azure 数据工厂工作室的主页,您可以在其中开始使用您的数据工厂。
在 Azure 门户中创建数据工厂
使用 Azure 门户创建数据工厂时,创建选项更为高级:
打开Microsoft Edge或 Google Chrome Web 浏览器。 目前,只有这些浏览器支持数据工厂 UI。
转到 Azure 门户的数据工厂页面。
选择 创建。

对于 资源组,请执行以下步骤之一:
- 从下拉列表中选择现有资源组。
- 选择“ 新建”,然后输入新资源组的名称。
若要了解资源组,请参阅 什么是资源组?
对于 区域,请选择数据工厂的位置。
该列表仅显示数据工厂支持的位置。 此区域存储数据工厂元数据。 数据工厂使用的关联数据存储(如Azure Storage和Azure SQL Database)和计算(如Azure HDInsight)可以在其他区域中运行。
对于 Name,数据工厂的名称必须在全球范围内是唯一的。 如果出现一条错误,提示名称已被占用,请更改数据工厂的名称(例如,将其更改为 <yourname>ADFTutorialDataFactory),然后尝试重新创建它。 若要详细了解数据工厂项目的命名规则,请参阅 数据工厂命名规则。
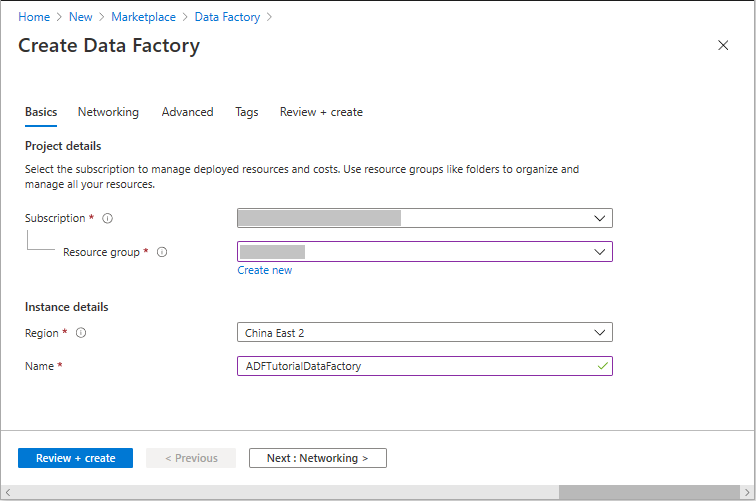
选择“查看 + 创建”。 配置通过验证后,选择“ 创建”。
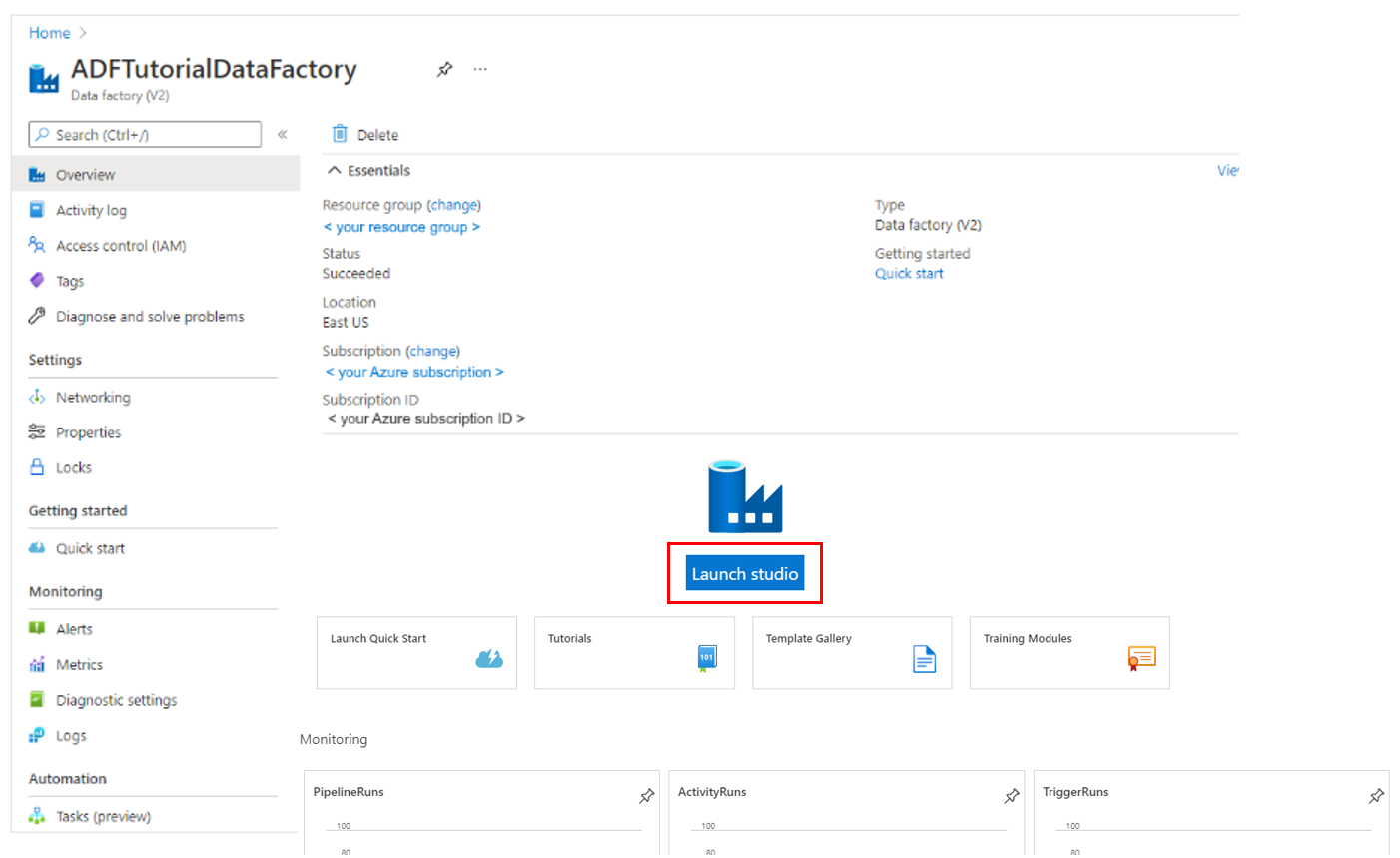
创建完成后,选择“ 转到资源”。
在数据工厂的页面上,选择Launch Studio打开Azure Data Factory Studio。 从这里,你可以开始使用数据工厂。
注意
如果 Web 浏览器停滞在 “授权”中,请清除 “阻止第三方 Cookie 和站点数据 ”复选框。 或者保持选中状态,为 login.partner.microsoftonline.cn 创建异常,然后再次尝试打开该应用。
相关内容
- 了解如何使用Azure Data Factory将数据从一个位置复制到另一个位置。
- 了解如何使用 Azure Data Factory 创建数据流
。 - 查看我们的热门教程列表以开始使用其他Azure Data Factory主题。