Azure SQL 数据库中可检测的查询性能瓶颈类型
适用于:![]() Azure SQL 数据库
Azure SQL 数据库
尝试解决某个性能瓶颈时,首先应判断该瓶颈是查询处于运行状态还是等待状态时发生的。 根据这种判断运用不同的解决方法。 借助下图来了解可能导致运行相关问题或等待相关问题的因素。 本文将探讨每种类型的问题及其相关解决方法。
可以使用智能见解或 SQL Server DMV 来检测这些类型的性能瓶颈。
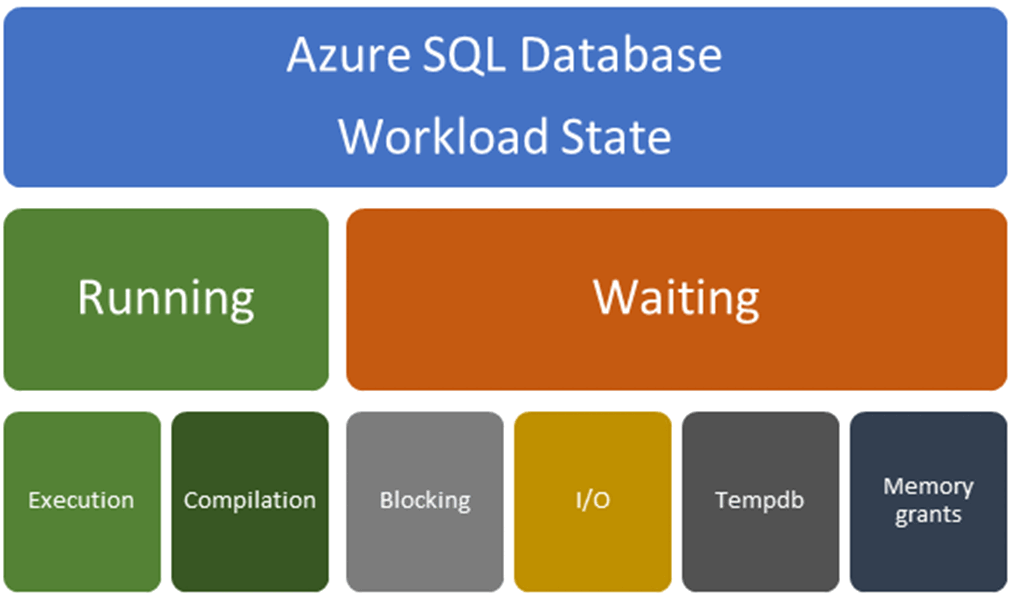
与运行相关的问题:与运行相关的问题通常与编译问题相关,这些编译问题导致查询计划欠佳,或导致与资源不足或过度使用相关的执行问题。 与等待相关的问题:与等待相关的问题通常与以下因素有关:
- 锁(阻塞)
- I/O
- 与
tempdb使用情况相关的争用 - 内存授予等待
本文介绍 Azure SQL 数据库。另请参阅 Azure SQL 托管实例中可检测的查询性能瓶颈类型。
导致查询计划欠佳的编译问题
SQL 查询优化器生成的欠佳计划可能是查询性能缓慢的原因。 由于缺少索引、统计信息过时、要处理的行数估算不当,或者所需内存估算错误,SQL 查询优化器可能会生成欠佳的计划。 如果我们知道该查询在过去或者在其他数据库上的执行速度较快,则可以比较实际的执行计划,以找到其差异。
使用以下方法之一识别任何缺失的索引:
- 使用智能见解。
- 查看数据库顾问中有关 Azure SQL 数据库中单一数据库和共用数据库的建议。 还可以选择启用自动调整选项,以调整 Azure SQL 数据库的索引。
- DMV 和查询执行计划中缺少索引。 本文演示如何使用缺失的索引请求来检测和调整非聚集索引。
作为高级故障排除步骤,使用查询存储提示通过查询存储应用查询提示,而无需更改代码。
查询优化和提示示例显示由于参数化查询导致查询计划欠佳的影响、如何检测此情况,以及如何使用查询提示解决问题。
尝试更改数据库兼容性级别并实施智能查询处理。 SQL 查询优化器可能会生成不同的查询计划,具体取决于数据库的兼容性级别。 更高的兼容性级别提供更多的智能查询处理功能。
- 有关查询处理的详细信息,请参阅查询处理体系结构指南。
- 若要更改数据库兼容性级别并详细了解兼容性级别之间的差异,请参阅 ALTER DATABASE。
- 若要详细了解基数估计,请参阅基数估计
解析存在欠佳查询执行计划的查询
以下部分介绍如何解决存在欠佳查询执行计划的查询。
存在参数敏感计划 (PSP) 问题的查询
当查询优化器生成的查询执行计划仅适用于某个或某组特定的参数值,而缓存计划对于连续执行操作中所用的参数值并非最佳时,将发生参数敏感计划 (PSP) 问题。 这样,并非最佳的计划可能导致查询性能问题,并降低整体工作负荷吞吐量。
有关参数探查和查询处理的详细信息,请参阅查询处理体系结构指南。
有多种解决方法可以缓解 PSP 问题。 每种解决方法各有利弊:
- SQL Server 2022 (16.x) 引入的一项新功能是参数敏感计划优化,它尝试缓解由参数敏感度导致的大多数次优查询计划。 这是通过 Azure SQL 数据库中的数据库兼容性级别 160 启用的。
- 在每次执行查询时使用 RECOMPILE 查询提示。 此解决方法以编译时间和 CPU 增加为代价来换取更好的计划质量。 对于需要高吞吐量的工作负荷,通常无法使用
RECOMPILE选项。 - 使用 OPTION (OPTIMIZE FOR…) 查询提示将实际参数值替代为典型的参数值,以便为大部分可能的参数值生成一个足够好的计划。 此选项要求充分了解最佳参数值和相关的计划特征。
- 使用 OPTION (OPTIMIZE FOR UNKNOWN) 查询提示替代实际参数值,并改用密度向量平均值。 还可以将传入的参数值捕获到局部变量中,然后在谓词内使用局部变量,而不是使用参数本身。 对于此修复方法,平均密度必须足够好。
- 使用 DISABLE_PARAMETER_SNIFFING 查询提示完全禁用参数探查。
- 使用 KEEPFIXEDPLAN 查询提示防止在缓存中重新编译。 此解决方法假定缓存中已有的通用计划已经足够好。 还可以禁用统计信息自动更新,以减少逐出良好计划而编译新的不良计划的可能性。
- 显式使用 USE PLAN 查询提示,通过重写查询并在查询文本中添加提示来强制执行计划。 或者,使用查询存储或启用自动优化来设置特定的计划。
- 将单个过程替换为一组嵌套的过程,可以根据条件逻辑和关联的参数值来使用其中每个过程。
- 创建动态字符串执行来替代静态过程定义。
若要应用查询提示,请修改查询或使用查询存储提示来应用提示,无需更改代码。
有关解决 PSP 问题的详细信息,请参阅以下博客文章:
- I smell a parameter(探查参数)
- Conor vs. dynamic SQL vs. procedures vs. plan quality for parameterized queries(参数化查询的 Conor 与动态 SQL、过程与计划质量)
参数化不当而导致的编译活动
当查询包含文本时,为了减少编译次数,要么数据库引擎选择自动参数化语句,要么用户显式参数化语句。 使用相同模式但不同文本值的大量查询编译可能会导致 CPU 使用率较高。 同样,如果仅将查询部分参数化,导致该查询仍包含文本,则数据库引擎不会将查询进一步参数化。
以下是部分参数化查询的示例:
SELECT *
FROM t1 JOIN t2 ON t1.c1 = t2.c1
WHERE t1.c1 = @p1 AND t2.c2 = '961C3970-0E54-4E8E-82B6-5545BE897F8F';
在此示例中,t1.c1 采用 @p1,而 t2.c2 继续采用文本形式的 GUID。 在这种情况下,如果更改 c2 的值,该查询将被视为不同的查询,并且将进行新的编译。 若要减少此示例中的编译次数,也要参数化 GUID。
以下查询显示查询哈希的查询计数,以确定查询是否已正确参数化:
SELECT TOP 10
q.query_hash
, count (distinct p.query_id ) AS number_of_distinct_query_ids
, min(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats AS rs
ON rs.plan_id = p.plan_id
JOIN sys.query_store_runtime_stats_interval AS rsi
ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
AND query_parameterization_type_desc IN ('User', 'None')
GROUP BY q.query_hash
ORDER BY count (distinct p.query_id) DESC;
影响查询计划更改的因素
重新编译查询执行计划可能会导致生成的查询计划与最初缓存的计划不同。 有多种原因可能导致自动重新编译现有的原始计划:
- 查询引用的架构发生更改
- 对查询引用的表进行数据更改
- 查询上下文选项已更改
编译的计划可能会出于各种原因从缓存中逐出,例如:
- 实例重启
- 数据库范围的配置更改
- 内存压力
- 清除缓存的显式请求
如果使用 RECOMPILE 提示,则不会缓存计划。
重新编译(或者在缓存逐出后重新编译)仍可能导致从生成与原始计划相同的查询执行计划。 如果计划与以前的或原始的计划不同,可能的解释如下:
更改了物理设计:例如,新建的索引可以更有效地解决查询要求。 如果查询优化器认为利用这些新索引比最初选择用于第一个版本的查询执行的数据结构更有利,则可以在新的编译中使用这些新索引。 对引用的对象进行任何物理更改可能会导致在编译时生成新的计划选项。
服务器资源差异:如果一个系统中的计划不同于另一个系统中的计划,则资源可用性(例如可用的处理器数)可能会影响生成的计划。 例如,如果一个系统的处理器数较多,则可能会选择并行计划。 有关 Azure SQL 数据库中的并行度的详细信息,请参阅在 Azure SQL 数据库中配置最大并行度 (MAXDOP)。
不同的统计信息:与引用的对象关联的统计信息发生了更改,或者与原始系统的统计信息有本质的差别。 如果统计信息发生更改并重新编译,则查询优化器将使用从更改时间开始的统计信息。 修改后的统计信息的数据分布和频率可能不同于原始编译中的情况。 这些更改用于创建基数估算。 (基数估算是预计要流经逻辑查询树的行数。)更改基数估算值可以引导我们选择不同的物理运算符和关联的操作顺序。 即使对统计信息进行少量的更改,也可能会导致查询执行计划发生变化。
更改了数据库兼容性级别或基数估算器版本:更改数据库兼容性级别可以启用新的策略和功能,从而可能导致生成不同的查询执行计划。 除了数据库兼容性级别以外,禁用或启用跟踪标志 4199 或更改数据库范围的配置 QUERY_OPTIMIZER_HOTFIXES 的状态也可能会影响编译时的查询执行计划选项。 跟踪标志 9481(强制旧式 CE)和 2312(强制默认 CE)也会影响计划。
资源限制问题
与欠佳查询计划和缺少索引无关的查询性能缓慢问题通常与资源不足或过度使用相关。 如果查询计划是最佳的,则原因可能是查询(和数据库)即将达到数据库或弹性池的资源限制。 例如,超过了服务级别的日志写入吞吐量限制。
使用 Azure 门户检测资源问题:若要确定问题是否与资源限制有关,请参阅 SQL 数据库资源监视。 对于单一数据库和弹性池,请参阅数据库顾问性能建议和查询性能见解。
使用智能见解检测资源限制
使用 DMV 检测资源问题:
- sys.dm_db_resource_stats DMV 返回数据库的 CPU、I/O 和内存消耗量。 即使数据库中没有活动,也会每隔 15 秒返回一行数据。 历史数据将保留一小时。
- sys.resource_stats DMV 返回 Azure SQL 数据库的 CPU 使用率和存储数据。 在 5 分钟间隔内收集并聚合数据。
- 存在许多单独的查询,它们共同消耗了很多的 CPU 资源
如果确定问题与资源不足有关,可以升级资源来增大数据库的容量,以满足 CPU 要求。 有关详细信息,请参阅在 Azure SQL 数据库中缩放单一数据库资源和在 Azure SQL 数据库中缩放弹性池资源。
工作负荷量增加导致的性能问题
应用程序流量和工作负荷量的增加可能会导致 CPU 使用率增大。 但是,要想正确诊断此问题,必须慎之又慎。 如果出现 CPU 使用率偏高的情况,请回答以下问题来确定 CPU 使用率增大是否由工作负荷量变化而引起:
来自应用程序的查询是否是导致高 CPU 问题的原因?
-
- 同一查询是否关联了多个执行计划? 如果是,为什么?
- 对于具有相同执行计划的查询,执行时间是否一致? 执行计数是否增加? 如果是,则性能问题可能是由工作负荷增加造成。
总而言之,如果查询执行计划没有以不同的方式执行,CPU 使用率却随执行计数的增加而增加,则可能出现了与工作负荷增加相关的性能问题。
要得出是工作负荷量变化导致 CPU 问题的结论并不容易。 请考虑以下因素:
资源使用率发生了变化:以 CPU 使用率长时间增加到 80% 的情况为例。 单凭 CPU 使用率并不能说明工作负荷量发生了变化。 即使应用程序执行的工作负荷完全相同,查询执行计划的回归和数据分布的变化也有可能导致资源使用率的增加。
出现了新查询:应用程序有可能在不同时间发出一组新的查询。
请求数量增加或减少:这种情况最能说明工作负荷量的变化。 查询数量并不一定与资源利用率增加相对应。 但是,在其他因素不变的前提下,该指标仍然是一个重要信号。
- 并行度:并行度过高会使其他查询得不到 CPU 和工作线程资源,从而使其他并发工作负载的性能降低。 有关 Azure SQL 数据库中的并行度的详细信息,请参阅在 Azure SQL 数据库中配置最大并行度 (MAXDOP)。
与等待相关的问题
消除与执行问题相关的欠佳计划和等待相关问题后,性能问题通常与查询可能正在等待某个资源有关。 等待相关的问题的可能原因如下:
阻塞:
一个查询可能持有数据库中某些对象的锁,而其他查询正在尝试访问相同的对象。 可以使用 DMV 或智能见解来识别阻塞的查询。 有关详细信息,请参阅了解并解决 Azure SQL 数据库阻塞问题。
IO 问题
查询可能正在等待将页面写入数据文件或日志文件。 在这种情况下,请检查 DMV 中的
INSTANCE_LOG_RATE_GOVERNOR、WRITE_LOG或PAGEIOLATCH_*等待统计信息。 了解如何使用 DMV 识别 IO 性能问题。Tempdb 问题
如果工作负荷使用大量的临时表,或者计划中存在大量的
tempdb溢出,则可能表示查询遇到了tempdb吞吐量问题。 若要进一步调查,请查看确定 tempdb 问题。内存相关的问题
如果工作负荷没有足够的内存,页生存期可能会下降,或者查询获得的内存量小于所需的量。 在某些情况下,查询优化器中的内置智能会解决内存相关的问题。 了解如何使用 DMV 识别内存授予问题。 有关示例查询的详细信息,请参阅排查 Azure SQL 数据库的内存不足错误。 如果遇到内存不足错误,请查看 sys.dm_os_out_of_memory_events。
用于显示最常见等待类别的方法
用于显示最常见等待类别的最常用方法如下:
- 使用智能见解识别由于等待时间增加而出现性能降低的查询
- 使用查询存储查找每个查询在不同时间段的等待统计信息。 在查询存储中,等待类型合并成等待类别。 可在 sys.query_store_wait_stats 中找到等待类别到等待类型的映射。
- 使用 sys.dm_db_wait_stats 返回有关查询操作期间执行的线程遇到的所有等待的信息。 可以使用此聚合视图来诊断 Azure SQL 数据库以及特定查询和批的性能问题。 查询可能正在等待资源,发生了队列等待或外部等待。
- 使用 sys.dm_os_waiting_tasks 返回有关正在等待某个资源的任务队列的信息。
在 CPU 使用率偏高时,如果存在以下情况,查询存储和等待统计信息可能不会反映 CPU 使用率:
- CPU 消耗量较高的查询仍在执行。
- 发生故障转移时,正在运行 CPU 消耗量较高的查询。
跟踪查询存储和等待统计信息的 DMV 仅显示成功完成的查询和超时查询的结果。 它们不显示当前正在执行的语句的数据(直到其完成)。 使用动态管理视图 sys.dm_exec_requests 跟踪当前正在执行的查询以及相关的工作线程时间。