适用于: ![]() Azure SQL 数据库
Azure SQL 数据库 ![]() Azure SQL 托管实例
Azure SQL 托管实例
借助 Azure SQL 数据库和 Azure SQL 托管实例中的智能见解,可了解数据库性能的情况。
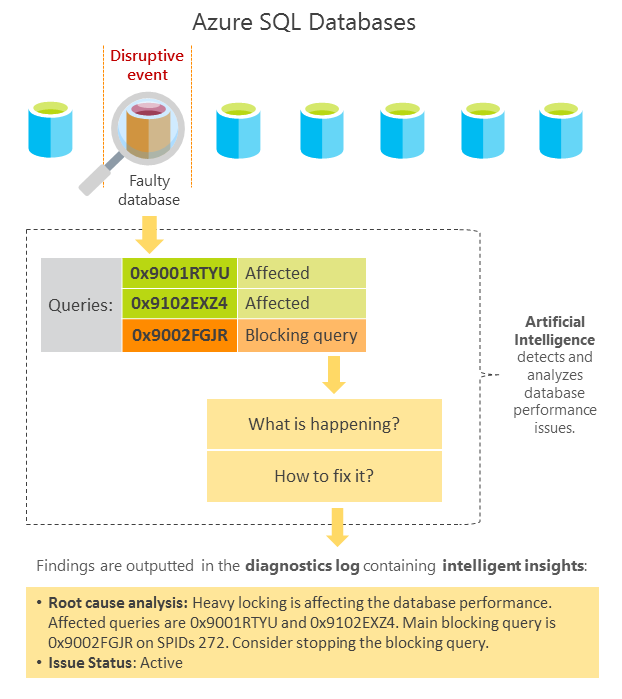
智能见解使用内置智能,通过人工智能持续监视数据库使用情况,并检测导致性能不佳的干扰性事件。 检测到后,将执行详细分析,生成名为 SQLInsights(与 Azure Monitor SQL 见解(预览版)无关)的智能见解资源日志,并对问题进行智能评估。 此评估包含对数据库性能问题的根本原因分析,以及为性能改进而提供的可行性建议。
Intelligent Insights 能为你做什么?
Intelligent Insights 是 Azure 内置智能的一项独特功能,提供以下功能价值:
- 主动监视
- 定制的性能见解
- 数据库性能下降的早期检测
- 已检测出问题的根本原因分析
- 性能改进建议
- 数以十万计的数据库上的横向扩展功能
- 对 DevOps 资源和总拥有成本的积极影响
智能见解的工作原理
智能见解可分析数据库性能,方法是比较前一个小时的数据库工作负荷和前七天的基线工作负荷。 数据库工作负荷由确定为对数据库性能最为重要的查询(例如重复最多和最大的查询)组成。 由于每个数据库基于其结构、数据、使用情况和应用程序都是唯一的,因此每个生成的工作负荷基线对于该工作负荷而言都具有特定性和唯一性。 由于独立于工作负载基线,智能见解还可监视绝对操作阈值,并检测过长的等待时间问题、关键异常和查询参数化问题,这些问题可能会对性能造成影响。
在使用人工智能根据多个观察的指标检测到性能降低问题后,将执行分析。 此外还会生成包含数据库状况的智能见解的诊断日志。 智能见解可对数据库性能问题从其首次出现到解决全程轻松展开跟踪。 从初始问题检测和性能改进验证到完成,跟踪每个检测到的问题的整个生命周期。
用于衡量和检测数据库性能问题的指标基于查询持续时间、超时请求、过长的等待时间和出错的请求制定。 有关指标的详细信息,请参阅检测指标。
已确定的数据库性能降低问题记录在智能见解 SQLInsights 日志中,其中包含由以下属性组成的智能项:
| 属性 | 详细信息 |
|---|---|
| 数据库信息 | 关于在其上检测到见解的数据库的元数据,例如资源 URI。 |
| 观察的时间范围 | 检测到的见解时段的开始和结束时间。 |
| 受影响的指标 | 导致生成某个见解的指标:
|
| 影响值 | 某个指标测量出的值。 |
| 受影响的查询和错误代码 | 查询哈希或错误代码。 这些属性可用于轻松关联到受影响的查询。 提供包括查询持续时间增加、等待时间、超时计数或错误代码的指标。 |
| 检测 | 在数据库中发生事件时确定的检测。 有 15 种检测模式。 有关详细信息,请参阅使用智能见解排查数据库性能问题。 |
| 根本原因分析 | 对已识别问题的根本原因分析采用人类可读的格式。 一些见解可能包含可行的性能改进建议。 |
智能见解在发现和排查数据库性能问题方面出类拔萃。 若要使用智能见解排查数据库性能问题,请参阅使用智能见解解决性能问题。
智能见解选项
可用的智能见解选项包括:
| 智能见解选项 | Azure SQL 数据库支持 | Azure SQL 托管实例支持 |
|---|---|---|
| 配置智能见解 - 配置针对数据库的智能见解分析。 | 是 | 是 |
| 将见解流式传输到 Azure 事件中心 - 将见解流式传输到事件中心,以便进一步进行自定义集成。 | 是 | 是 |
| 将见解流式传输到 Azure 存储 - 将见解流式传输到 Azure 存储,以便进一步进行分析和长期存档。 | 是 | 是 |
配置智能见解日志的导出
可以将智能见解的输出流式传输到多个目标之一进行分析:
- 使用流式传输到 Azure 事件中心的输出,可以开发自定义监视和警报方案
- 借助流式传输到 Azure 存储的输出,可进行自定义应用程序开发,例如自定义报告、长期数据存档等等。
与 Azure SQL Analytics、Azure 事件中心、Azure 存储或第三方消费产品的集成方式是:先在数据库的“诊断设置”页中启用智能见解日志记录(“SQLInsights”日志),然后配置要流式传输到这些目标之一的智能见解日志数据。
要详细了解如何启用智能见解日志记录和配置要流式传输到消费产品的指标及资源日志数据,请参阅指标和诊断日志记录。
通过事件中心进行设置
若要将智能见解与事件中心配合使用,配置要流式传输到事件中心的智能见解日志数据,请参阅指标和诊断日志记录和将 Azure 诊断日志流式传输到事件中心。
若要使用事件中心设置自定义监视和警报,请参阅如何在事件中心处理指标和诊断日志。
通过 Azure 存储进行设置
若要将智能见解与存储配合使用,配置要流式传输到存储的智能见解日志数据,请参阅指标和诊断日志记录和流式传输到 Azure 存储。
智能见解日志的自定义集成
若要将智能见解与第三方工具配合使用或用于自定义警报和监视开发,请参阅使用智能见解数据库性能诊断日志。
检测指标
用于生成智能见解的检测模型的指标基于监视以下内容得出:
- 查询持续时间
- 超时请求
- 过长的等待时间
- 出错的请求
在检测数据库工作负载性能问题时,查询持续时间和超时请求将用作主要模型。 这是因为它们直接测量工作负荷发生的情况。 为检测工作负荷性能降低的所有可能情况,过长的等待时间和出错的请求将用作附加模型,以指出影响工作负荷性能的问题。
系统会自动将工作负荷更改和对数据库所做的查询请求数更改纳入考虑,以动态决定正常和异常的数据库性能阈值。
所有指标都将通过科学派生的数据模型在各种关系中纳入考虑,并且这种模型会对每个检测到的性能问题进行归类。 通过智能见解提供的信息包括:
- 检测到的性能问题的详细信息。
- 检测到的问题的根本原因分析。
- 关于在可能的情况下如何提升受监视数据库的性能的建议。
查询持续时间
查询持续时间下降模型分析单独的查询,并检测与性能基线相比,编译和执行查询增加的时间。
如果内置智能检测到查询编译或查询执行时间显著增加并影响工作负载性能,这些查询将被标记为出现查询持续时间性能降低问题。
智能见解诊断日志会输出性能降低的查询的查询哈希。 查询哈希指出性能降低是否与查询编译或执行时间增加(使查询持续时间增加)有关。
超时请求
超时请求下降模型分析单独的查询,并在查询执行级别检测任何超时增加情况,以及与性能基线持续时间相比,数据库级别的总体请求超时。
某些查询甚至在到达执行阶段之前就可能超时。 通过比较中止的辅助角色数和所提请求数的方式,内置智能还测量和分析到达数据库的所有查询,而不管它们有没有到达执行阶段。
在执行查询超时数或中止的请求辅助角色数超出系统管理阈值后,使用智能见解填充诊断日志。
生成的见解包含超时请求数和超时查询数。 指示性能降低是否与执行阶段的超时增加有关,或提供总体数据库级别。 当系统认为超时增加对数据库性能至关重要时,这些查询将标记为出现超时性能降低问题。
过长的等待时间
过长的等待时间模型监视单个数据库查询。 它会检测高出系统管理的绝对阈值的异常查询等待统计信息。 以下查询过长等待时间指标通过查询存储等待统计信息 (sys.query_store_wait_stats) 进行观察:
- 达到资源限制
- 达到弹性池资源上限
- 过多的辅助角色或会话线程数
- 过多的数据库锁定
- 内存压力
- 其他等待统计信息
达到资源限制或弹性池资源限制表示某一订阅或弹性池中的可用资源消耗已超出绝对阈值。 这些统计信息指示工作负荷性能降低。 过多的辅助角色或会话线程数表示如下情况:启动的工作线程数或会话数超出绝对阈值。 这些统计信息指示工作负荷性能降低。
过多的数据库锁定表示如下情况:数据库锁定计数超出绝对阈值。 此状态指示工作负荷性能降低。 内存压力表示如下情况:请求内存授予的线程数超出绝对阈值。 此状态指示工作负荷性能降低。
其他等待统计信息指示如下情况:通过查询存储等待统计信息测量的其他指标超出绝对阈值。 这些统计信息指示工作负荷性能降低。
检测到过长的等待时间后,根据可用数据的情况,智能见解诊断日志将输出性能降低正在影响和已经影响的查询的哈希,以及导致查询在执行和测量等待时间中等待的指标的详细信息。
出错的请求
出错的请求下降模型监视单独的查询,并检测与基线持续时间相比,增加的出错查询数。 此模型还监视超出内置智能管理的绝对阈值的关键异常。 系统会自动考虑向数据库提出的查询请求数,并在受监视时期说明任何工作负荷更改。
当系统认为测量出的出错请求数增加(与提出的总请求数有关)对工作负荷性能至关重要时,受影响的查询将标记为具有出错请求的性能降低问题。
智能见解日志输出出错请求计数。 它会指示性能降低是否与出错请求数增加或超出受监视的关键异常阈值有关,以及性能降低的测量时间。
在任何受监视的关键异常超出系统管理的绝对阈值的情况下,会使用关键异常详细信息生成智能见解。
后续步骤
- 了解如何使用智能见解排查性能问题。