适用于:![]() Azure SQL 数据库
Azure SQL 数据库
本文回顾 Azure SQL 数据库的 vCore 购买模型。
概述
虚拟核心(vCore)表示逻辑 CPU,并提供选择硬件的物理特征的选项(例如核心数、内存和存储大小)。 基于 vCore 的购买模型为你提供灵活性、控制权、单个资源消耗的透明度,以及一种简单的方法来将本地工作负载需求转移到云端。 此模型优化价格,并允许根据工作负荷需求选择计算、内存和存储资源。
在基于 vCore 的购买模型中,成本取决于以下选项和使用情况:
- 服务层
- 硬件配置
- 计算资源(vCore 数和内存量)
- 预留的数据库存储
- 实际备份存储
重要
计算资源、I/O 以及数据和日志存储按数据库或弹性池收费。 备份存储按每个数据库收费。 有关定价详细信息,请参阅 Azure SQL 数据库定价页。
比较 vCore 和 DTU 购买模型
Azure SQL 数据库使用的 vCore 购买模型相比于基于 DTU 的购买模型而言具备多项优势:
- 更高的计算、内存、I/O 和存储限制。
- 选择硬件配置以更好地匹配工作负荷的计算和内存要求。
- Azure Hybrid Benefit (AHB)提供的折扣定价。
- 提高对支持计算的硬件详细信息的透明度,以帮助规划从本地部署的迁移。
- 缩放粒度更高,并提供多个可用的计算大小。
有关如何在 vCore 和 DTU 购买模型之间进行选择的帮助,请参阅 vCore 和基于 DTU 的购买模型之间的差异。
计算
基于 vCore 的购买模型具有预配的计算层和 无服务器 计算层。 在预配的计算层中,计算成本反映为独立于工作负荷活动的应用程序持续预配的总计算容量。 根据 vCore 和内存要求,选择最适合业务需求的资源分配,然后根据需要根据工作负荷纵向扩展和缩减资源。 在 Azure SQL 数据库的无服务器计算层中,根据工作负荷容量自动缩放计算资源,并按每秒使用的计算量计费。
总结:
- 虽然 预配的计算层 提供了独立于工作负荷活动持续预配的特定计算资源量,但 无服务器计算层 根据工作负荷活动自动缩放计算资源。
- 预配计算层级按每小时固定价格对预配的计算量收费,而无服务器计算层级则按每秒使用的计算量收费。
无论计算层级如何,在业务关键服务层级中会自动分配三个额外的高可用性次要副本,以提供高复原能力,应对故障和快速故障转移。 这些附加副本的成本比“常规用途”服务层级高出约 2.7 倍。 同样,业务关键服务层级中每 GB 的存储成本越高,反映了本地 SSD 存储的 IO 限制和更低的延迟。
在“超大规模”中,客户控制从 0 到 4 的额外高可用性副本数,以在控制成本的同时,获取应用程序所需的复原能力级别。
有关 Azure SQL 数据库中的计算的详细信息,请参阅 计算资源(CPU 和内存)。
资源限制
数据和日志存储
以下因素会影响用于数据和日志文件的存储量,并应用于“常规用途”和“业务关键”层。
- 每个计算大小都支持可配置的最大数据大小,默认值为 32 GB。
- 配置最大数据大小时,将自动为日志文件额外添加 30% 的可计费存储。
- 在常规用途服务层级中,
tempdb使用本地 SSD 存储,此存储成本包含在 vCore 价格中。 - 在业务关键服务层级中,
tempdb与数据和日志文件共享本地 SSD 存储,tempdb存储成本包含在 vCore 价格中。 - 在“常规用途”和“业务关键”层中,需要为数据库或弹性池配置的最大存储大小付费。
- 对于 SQL 数据库,可以选择 1 GB 与支持的存储大小上限之间的任意最大数据大小(以 1 GB 为增量)。
以下存储注意事项适用于超大规模:
- 最大数据存储大小设置为 128 TB,且不可配置。
- 您只需为已分配的数据存储付费,而不是为最大的数据存储量付费。
- 日志存储不收费。
-
tempdb使用本地 SSD 存储,其成本包含在 vCore 价格中。 要监视 SQL 数据库中的当前已分配和已用数据存储大小,请分别使用 allocated_data_storage 和 storage Azure Monitor 指标。
若要使用 T-SQL 监视数据库中单个数据和日志文件的当前分配和使用存储大小,请使用 sys.database_files 视图和 FILEPROPERTY(... 'SpaceUsed') 函数。
小提示
在某些情况下,可能需要收缩数据库以回收未使用的空间。 有关详细信息,请参阅 管理 Azure SQL 数据库中的文件空间。
备份存储
为数据库备份分配存储,以支持 SQL 数据库的 时间点还原(PITR) 和 长期保留(LTR) 功能。 此存储独立于数据和日志文件存储,并单独计费。
- PITR:在“常规用途”层和“业务关键”层中,会自动将单个数据库备份复制到 Azure 存储。 创建新备份时,存储大小会动态增加。 存储由完整备份、差异备份和事务日志备份使用。 存储消耗取决于数据库的更改率和为备份配置的保留期。 可以为 SQL 数据库为每个数据库配置 1 到 35 天的单独保留期。 备份存储量等于配置的最大数据大小,不收取额外费用。
- LTR:还可以配置完整备份的长期保留,最长可达 10 年。 如果设置了 LTR 策略,这些备份会自动存储在 Azure Blob 存储中,但可以控制备份的复制频率。 若要满足不同的符合性要求,可以为每周、每月和/或每年备份选择不同的保留期。 选择的配置确定用于 LTR 备份的存储量。 有关详细信息,请参阅 长期备份保留。
有关超大规模备份存储,请参阅 超大规模数据库的自动备份。
服务等级
vCore 购买模型中的服务层选项包括“常规用途”、“业务关键”和“超大规模”。 服务层通常确定存储类型和性能、高可用性和灾难恢复选项,以及某些功能(如 In-Memory OLTP)的可用性。
| 用例 | 常规用途 | 业务关键 | 超大规模 |
|---|---|---|---|
| 最适用于 | 大多数业务工作负载。 提供面向预算、平衡且可缩放的计算和存储选项。 | 使用多个高可用性次要副本为业务应用程序提供对故障的最高复原能力,并提供最高的 I/O 性能。 | 最广泛的工作负载,包括具有高度可缩放存储和读取缩放要求的工作负载。 通过允许配置多个高可用性次要副本,提供更高的故障复原能力。 |
| 计算大小 | 2 到 80 个 vCore | 2 到 80 个 vCore | 2 到 80 个 vCore |
| 存储类型 | 高级远程存储(每个实例) | 超快的本地 SSD 存储(每个实例) | 将存储与本地 SSD 缓存分离(每个计算副本) |
| 存储大小 | 1 GB - 4 TB | 1 GB - 4 TB | 10 GB - 128 TB |
| 最大 IOPS | 最大 12,800 IOPS | 最大 204,800 IOPS | 204,800 IOPS(具有最大本地 SSD) 超大规模是一种多层次结构,在多个层级进行缓存。 有效的 IOPS 取决于工作负荷。 |
| 内存/vCore | 5.1 GB | 5.1 GB | 5.1 GB |
| 备份 | 选择异地冗余、区域冗余或本地冗余备份存储,保留期为 1-35 天(默认为 7 天) 长期保留期最长为 10 年 |
选择异地冗余、区域冗余或本地冗余备份存储,保留期为 1-35 天(默认为 7 天) 长期保留期最长为 10 年 |
选择本地冗余(LRS)、区域冗余(ZRS)或异地冗余(GRS)存储 1-35 天(默认值为 7 天)的保留期,最长的长期保留期为 10 年 |
| 可用性 | 一个副本,无读取缩放副本, 区域冗余高可用性 (HA) |
三个副本,一个读取缩放副本, 区域冗余高可用性 (HA) |
区域冗余高可用性 (HA) |
| 定价/计费 |
vCore、保留存储和备份存储 收费。 IOPS 不收费。 |
vCore、保留存储和备份存储 收费。 IOPS 不收费。 |
每个副本的 vCore 和已用存储收费。 IOPS 不收费。 |
| 折扣模型 |
Azure 混合权益(在开发/测试订阅中不可用) 企业和即用即付开发/测试套餐订阅 |
Azure 混合权益(在开发/测试订阅中不可用) 企业和即用即付开发/测试套餐订阅 |
Azure 混合权益(在开发/测试订阅上不可用)1 企业和即用即付开发/测试套餐订阅 |
| 内存中 OLTP 表 | 否 | 是的 | 无 |
1 即将推出 SQL Database 超大规模的简化定价。 有关详细信息,请查看 超大规模定价博客。
有关更多详细信息,请查看 逻辑服务器的资源限制、单一数据库和 共用数据库。
常规用途
常规用途服务层的体系结构模型基于计算和存储的分离。 此体系结构模型依赖于 Azure Blob 存储的高可用性和可靠性,该存储以透明方式复制数据库文件,并确保在发生底层基础结构故障时不会丢失任何数据。
下图显示了标准体系结构模型中具有分隔计算层和存储层的四个节点。
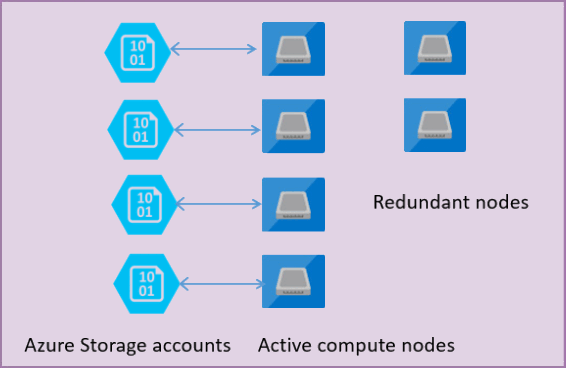
在常规用途服务层级的体系结构模型中,有两个层:
- 运行进程的无状态计算层
sqlservr.exe,仅包含暂时性和缓存数据(例如-计划缓存、缓冲池、列存储池)。 此无状态节点由 Azure Service Fabric 运行,它会初始化进程、控制节点运行状况,并根据需要执行到另一位置的故障转移。 - 包含存储在 Azure Blob 存储中的数据库文件(.mdf/.ldf)的有状态数据层。 Azure Blob 存储保证任何数据库文件中没有任何记录丢失。 Azure 存储具有内置的数据可用性/冗余,可确保即使进程崩溃,也会保留日志文件或数据文件页中的每个记录。
每当升级数据库引擎或作系统时,底层基础结构的某些部分会失败,或者如果在 sqlservr.exe 进程中检测到某些严重问题,Azure Service Fabric 会将无状态进程移动到另一个无状态计算节点。 如果主节点的故障转移发生,则有一组备用节点等待运行新的计算服务,以便最大程度地减少故障转移时间。 Azure 存储层中的数据不会受到影响,数据/日志文件将附加到新初始化的进程。 默认情况下,此过程保证 99.99% 可用性,启用 区域冗余 时,% 可用性为 99.995。 由于存在切换时间,并且新节点从冷缓存启动,正在执行的繁重工作负载的性能可能会受到一些影响。
何时选择“常规用途”服务层级
常规用途服务层级是 Azure SQL 数据库中的默认服务层,专为大多数通用工作负荷而设计。 如果需要具有默认 SLA 的完全托管数据库引擎,并且存储延迟在 5 毫秒到 10 毫秒之间,则“常规用途”层是一个选项。
业务关键
业务关键服务层级模型基于数据库引擎进程的群集。 此架构模型依赖于数据库引擎节点的多数,以最大程度减少对您工作负荷的性能的影响,即使在维护期间也是如此。 基础作系统、驱动程序和数据库引擎的升级和修补程序以透明方式进行,最终用户的停机时间最短。
在业务关键模型中,计算和存储在每个节点上集成。 在四节点群集的每个节点上的数据库引擎进程之间复制数据可实现高可用性,每个节点使用本地附加的 SSD 作为数据存储。 下图显示了业务关键服务层级如何在可用性组副本中组织数据库引擎节点群集。

数据库引擎进程和基础 .mdf/.ldf 文件都放置在具有本地附加 SSD 存储的同一节点上,为工作负荷提供低延迟。 高可用性是使用类似于 SQL Server AlwaysOn 可用性组的技术实现的。 每个数据库都是一个数据库节点群集,其中一个主要副本可供客户工作负荷访问,以及包含数据副本的三个次要副本。 如果主要副本因任何原因而失败,则主要副本会不断推送到次要副本的更改,以确保数据在次要副本上可用。 故障转移由 Service Fabric 和数据库引擎处理 - 一个次要副本成为主要副本,并创建新的次要副本来确保群集中有足够的节点。 工作负荷会自动重定向到新的主副本。
此外,业务关键群集具有内置的读取扩展功能,该功能提供免费的只读副本,用于运行不会影响主要副本上工作负载性能的只读查询(例如报告)。
何时选择“业务关键”服务层级
业务关键服务层级专为需要底层 SSD 存储(平均 1-2 毫秒)提供低延迟响应的应用程序而设计。当底层基础结构发生故障时,它能够更快恢复,或将报表、分析和只读查询卸载到基于主数据库的免费可读次要副本中。
选择“业务关键”服务层级而不是“常规用途”层的主要原因是:
- 低 I/O 延迟要求 - 需要存储层(平均 1-2 毫秒)的快速响应的工作负荷应使用业务关键层。
- 包含报告和分析查询的工作负载,其中仅需一个免费的辅助只读副本。
- 更高的复原能力和更快的故障恢复。 如果系统发生故障,主实例上的数据库将被禁用,其中一个辅助副本会立即成为新的读写主数据库,可以处理查询。
- 高级数据损坏保护。 由于业务关键层在后台使用数据库副本,因此该服务利用 镜像和可用性组 提供的自动页面修复功能来帮助缓解数据损坏。 如果副本由于数据完整性问题而无法读取页面,则会从另一个副本检索该页的新副本,从而替换不可读的页面,而不会丢失数据或客户停机。 如果数据库具有异地辅助副本,此功能可在“常规用途”层中使用。
- 更高的可用性 - 多可用性区域配置中的业务关键层提供对区域性故障和更高可用性 SLA 的复原能力。
- 快速异地恢复 - 如果配置了活动异地复制,业务关键层级可在 100% 的部署小时内确保恢复点目标 (RPO) 为 5 秒和恢复时间目标 (RTO) 为 30 秒。
超大规模
“超大规模”服务层级适用于所有工作负荷类型。 其云原生体系结构提供独立可缩放的计算和存储,以支持各种传统和现代应用程序。 超大规模计算和存储资源大大超出了“常规用途”和“业务关键”层中可用的资源。
若要了解详细信息,请查看 Azure SQL 数据库 超大规模服务层级。
何时选择“超大规模”服务层级
“超大规模”服务层级消除了传统上在云数据库中看到的许多实际限制。 如果大多数其他数据库受单个节点中可用资源的限制,则“超大规模”服务层级中的数据库没有此类限制。 借助其灵活的存储体系结构,“超大规模”数据库会根据需要增长,并且仅针对使用的存储容量计费。
除了其高级缩放功能外,Hyperscale 适用于任何工作负荷,而不仅仅是大型数据库。 借助超大规模,可以:
- 通过选择 0 到 4 的高可用性副本数,实现 高复原和快速故障恢复,同时控制成本。
- 通过为计算和存储启用区域冗余来提高 高可用性。
- 对于经常访问的数据库部分,实现 低 I/O 延迟(平均为 1-2 毫秒)。 对于较小的数据库,这可能适用于整个数据库。
- 使用命名副本实现各种读取扩展方案。
- 利用快速缩放,无需等待数据复制到新节点上的本地存储。
- 享受“零影响连续数据库备份”和“快速还原”。
- 使用故障转移组和异地复制来满足 业务连续性 的要求。
计算资源(CPU 和内存)
下表比较了不同硬件配置和计算层中的计算资源:
| 硬件配置 | CPU | 内存 |
|---|---|---|
| 标准系列 (第5代) |
预配计算 - Intel® E5-2673 v4 (Broadwell) 2.3 GHz,Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2.5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (米兰) 处理器 - 预配最多 80 个 vCore(超线程) 无服务器计算 - Intel® E5-2673 v4 (Broadwell) 2.3 GHz,Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2.5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (米兰) 处理器 - 自动纵向扩展到 40 个 vCore(超线程) - 内存与 vCore 比率根据工作负荷需求动态适应内存和 CPU 使用率,每个 vCore 的容量可能高达 24 GB。 |
预配计算 - 每个 vCore 5.1 GB - 最多预配 415 GB 无服务器计算 - 自动缩放到每个 vCore 24 GB 自动扩展至最多 120 GB |
* 在 sys.dm_user_db_resource_governance 动态管理视图中,使用 Intel® SP-8160(Skylake)处理器的数据库的硬件代系显示为 Gen6,使用 Intel® 8272CL(Cascade Lake)的数据库的硬件代系显示为 Gen7,使用 Intel® Xeon® Platinum 8370C(Ice Lake)或 AMD® EPYC® 7763v(米兰)的数据库的硬件代系显示为 Gen8。 对于给定的计算大小和硬件配置,无论 CPU 类型(Intel Broadwell、Skylake、Ice Lake、Cascade Lake 或 AMD 米兰),资源限制都是相同的。
有关详细信息,请参阅 单一数据库的资源限制 和 弹性池。
有关超大规模数据库计算资源和规范,请参阅 超大规模计算资源。
标准系列 (第5代)
标准系列(Gen5)硬件提供均衡的计算和内存资源,适用于大多数数据库工作负荷。
标准系列(Gen5)硬件在所有区域中都可用。
选择硬件配置
可以在创建时为 SQL 数据库中的数据库或弹性池选择硬件配置。 还可以更改现有数据库或弹性池的硬件配置。
在创建 SQL 数据库或池时选择硬件配置
有关详细信息,请参阅 创建 SQL 数据库。
在“基本信息”选项卡上,选择 “计算 + 存储”部分中的“配置数据库”链接,然后选择 “更改配置” 链接:

选择所需的硬件配置:

更改现有 SQL 数据库或池的硬件配置
对于数据库,请在“概述”页上选择“定价层”链接:

对于池,请在“概述”页上选择“配置”。
按照步骤更改配置,并按前面的步骤所述选择硬件配置。
硬件可用性
有关当前代硬件可用性的信息,请参阅 Azure SQL 数据库按区域功能可用性。
上一代硬件
Gen4
Gen4 硬件已停用,不可用于预配、纵向扩展或缩减。 将数据库迁移到受支持的硬件代系,实现更广泛的 vCore 和存储可伸缩性、加速网络、最佳 IO 性能和最小延迟。 查看单一数据库的硬件选项和弹性池的硬件选项。 有关详细信息,请参阅 Azure SQL 数据库上对第 4 代硬件的支持已结束。