本教程介绍如何使用 Azure Functions 触发 Batch 作业。 本文逐步讲解一个示例,该示例将文档添加到Azure 存储 blob 容器,并使用Azure Batch向其应用光学字符识别(OCR)。 为了简化 OCR 处理,此示例配置每次将文件添加到 Blob 容器时运行 Batch OCR 作业的 Azure 函数。 你将学会如何:
- 使用 Azure 门户创建池和作业。
- 创建 Blob 容器和共享访问签名(SAS)。
- 创建 Blob 触发的 Azure 函数。
- 将输入文件上传到存储。
- 监视任务执行情况。
- 检索输出文件。
先决条件
- 拥有有效订阅的 Azure 帐户。 创建试用版订阅。
- Azure Batch 帐户和链接的 Azure 存储帐户。 有关如何创建和链接帐户的详细信息,请参阅 “创建 Batch 帐户”。
登录到 Azure
登录到 Azure 门户。
使用 Azure 门户创建批处理池和批处理作业
本部分将使用 Azure 门户创建用于运行 OCR 任务的批处理池和批处理作业。
创建池
使用 Azure 凭据登录到 Azure 门户。
通过在左侧导航栏中选择 “池 ”来创建池,然后选择搜索窗体上方的“ 添加 ”按钮。
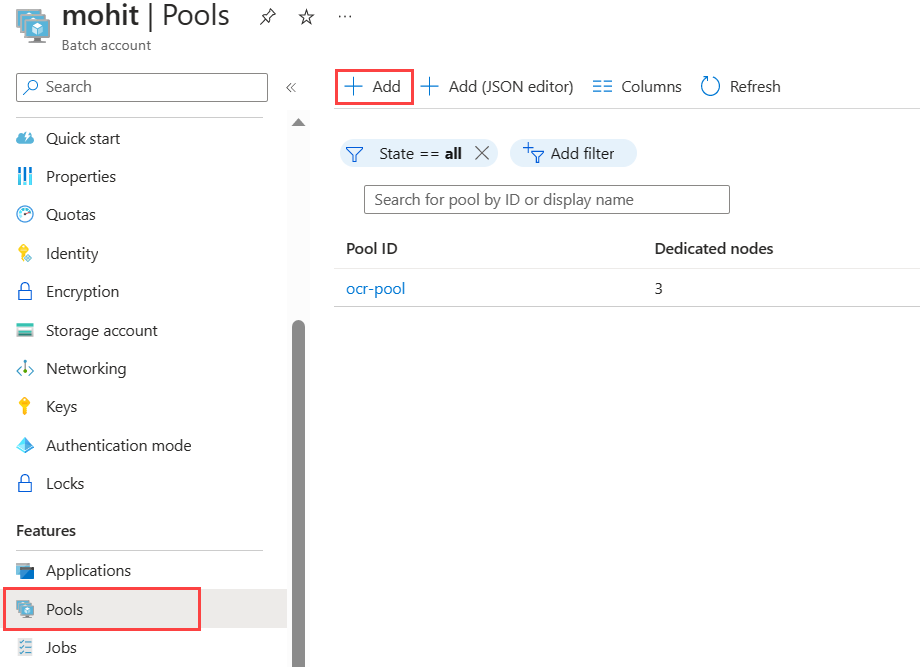
- 输入 池 ID。 此示例将池命名为
ocr-pool。 - 选择 Canonical 作为 发布者。
- 选择 0001-com-ubuntu-server-jammy 作为 套餐。
- 选择 22_04-lts 作为 Sku。
- 在
Standard_F2s_v2 - 2 vCPUs, 2 GB Memory”部分选择为 VM 大小。 - 将“缩放”部分中的“模式”设置为“固定”,并为目标专用节点输入 3。
- 将“开始”任务设置为“启用启动任务”,然后在
/bin/bash -c "sudo update-locale LC_ALL=C.UTF-8 LANG=C.UTF-8; sudo apt-get update; sudo apt-get -y install ocrmypdf"中输入命令。 请务必将 提升级别 设置为 池自动用户,管理员,这允许启动任务包含命令sudo。 - 选择“确定”。
- 输入 池 ID。 此示例将池命名为
创建职位
- 通过在左侧导航栏中选择“作业”,您可以在池中创建作业,然后选择搜索框上方的“添加”按钮。
- 输入 作业 ID。 此示例使用
ocr-job。 - 选择
ocr-pool当前池,或您为池选择的任何名称。 - 选择“确定”。
- 输入 作业 ID。 此示例使用
创建 Blob 容器
在这里,你将创建 Blob 容器,用于存储 OCR Batch 作业的输入和输出文件。 在此示例中,输入容器被命名 input ,并且是最初上传不带 OCR 的所有文档进行处理的位置。 输出容器命名为 output ,批处理作业将使用 OCR 处理后生成的文档写入其中。
在 Azure 门户中搜索并选择 存储帐户 。
选择与 Batch 帐户关联的存储帐户。
从左侧导航中选择 “容器 ”,然后按照“ 创建 Blob 容器”中的步骤创建两个 Blob 容器(一个用于输入文件,一个用于输出文件)。
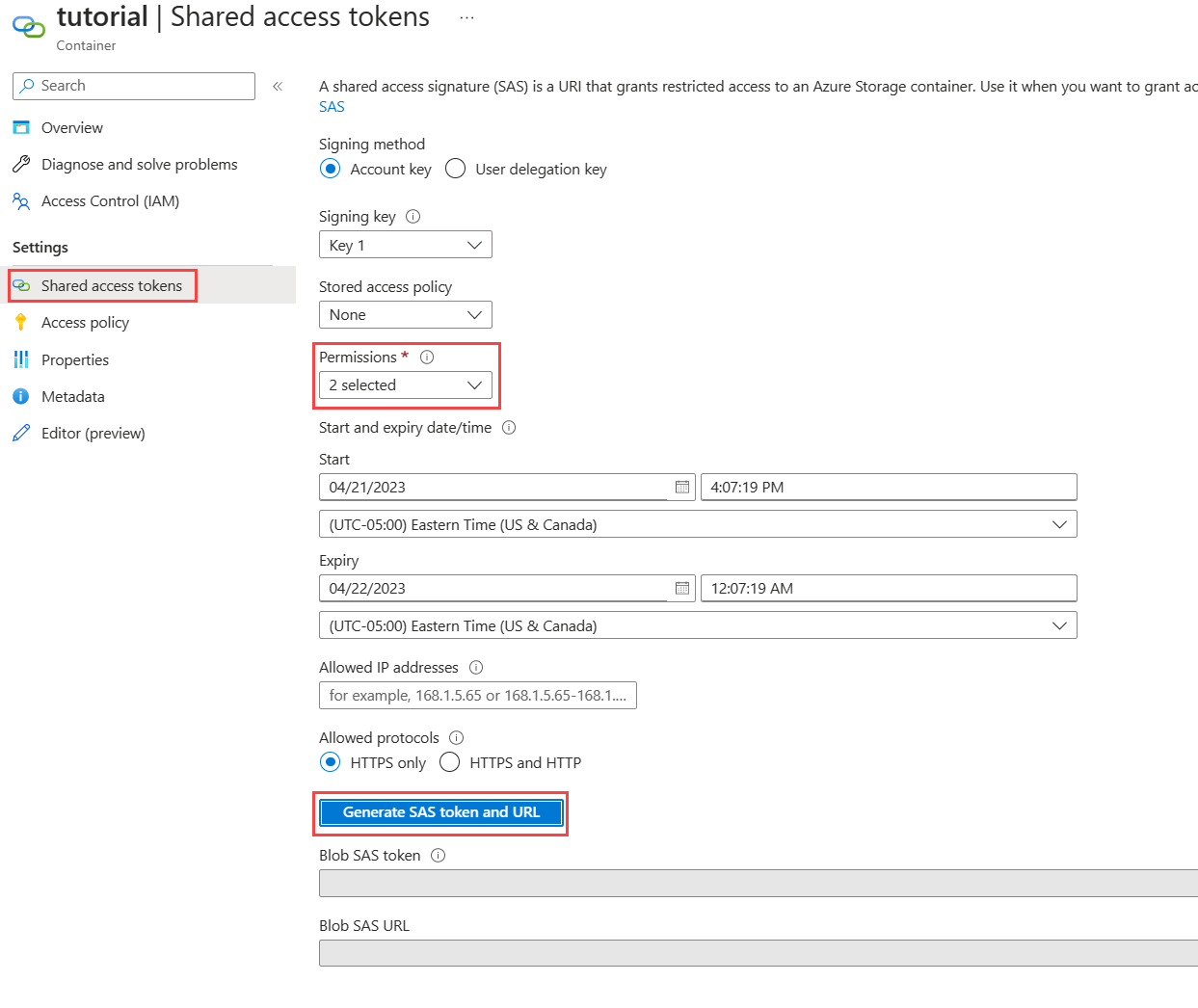
通过选择输出容器为输出容器创建共享访问签名,然后在“共享访问令牌”页上,在“权限”下拉列表中选择“写入”。 不需要其他任何权限。
选择生成 SAS 令牌和 URL,然后复制Blob SAS URL,以供函数稍后使用。
创建 Azure 函数
在本部分中,将创建一个 Azure 函数,每当文件上传到输入容器时,就会触发 OCR Batch 作业。
请按照创建由 Azure Blob 存储触发的函数中的步骤来创建一个函数。
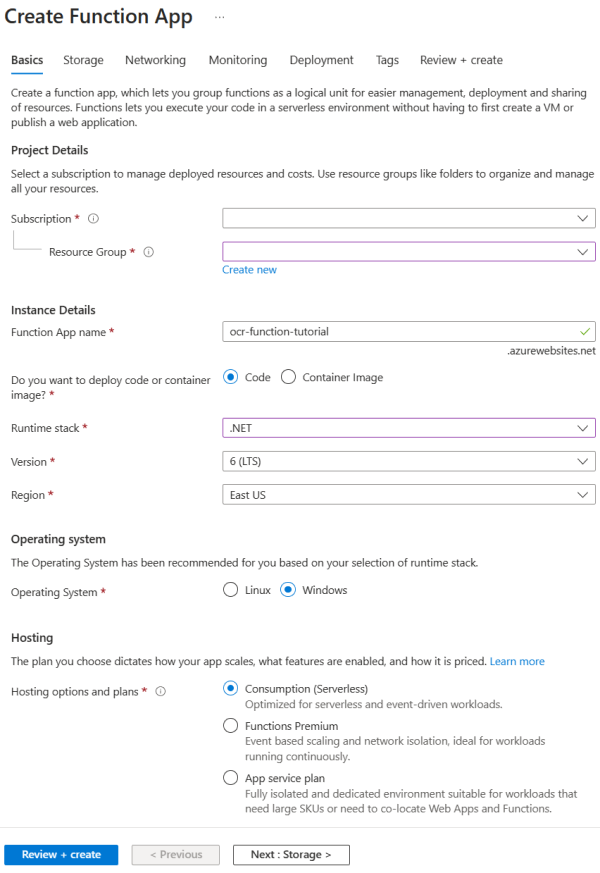
- 对于 运行时堆栈,请选择 .NET。 此示例函数使用 C# 来利用 Batch .NET SDK。
- 在 “存储 ”页上,使用链接到 Batch 帐户的同一存储帐户。
- 选择审阅 + 创建> 创建。
以下是使用示例信息在基本信息选项卡上显示的创建函数应用页面的屏幕截图。
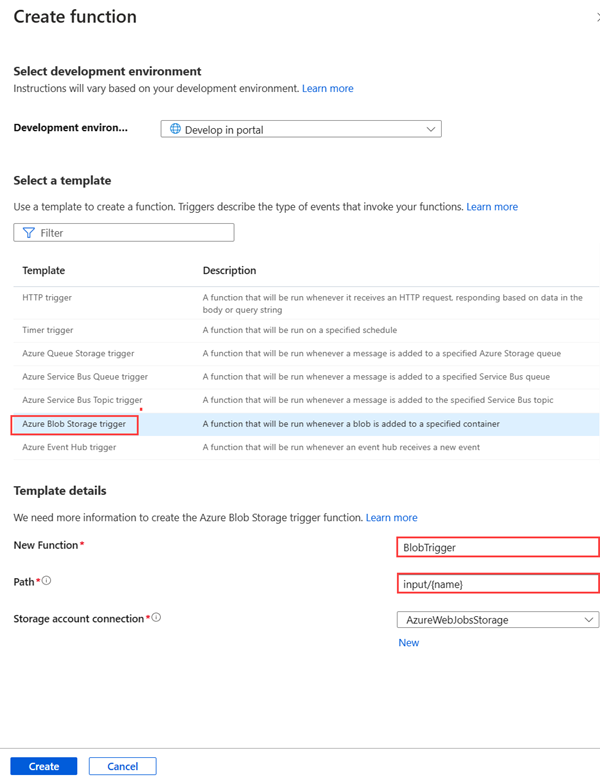
在函数中,从左侧导航中选择 “函数 ”,然后选择“ 创建”。
在“ 创建函数 ”窗格中,选择“Azure Blob 存储触发器”。
在 “新建函数”中输入函数的名称。 在此示例中,名称为 OcrTrigger。 输入路径为
input/{name},其中input/{name}为 Blob 容器的名称。选择 创建。
创建 Blob 触发的函数后,选择 “代码 + 测试”。 在函数中使用来自 GitHub 的
run.csx和function.proj。function.proj默认情况下不存在,因此请选择 “上传 ”按钮将其上传到开发工作区。- 当将新 Blob 添加到输入 Blob 容器时,
run.csx将运行。 -
function.proj列出函数代码中的外部库,例如 Batch .NET SDK。
- 当将新 Blob 添加到输入 Blob 容器时,
更改
Run()文件中run.csx函数的变量占位符值,以反映您的 Batch 和存储凭据。 可以在 Batch 和存储帐户的 “密钥 ”部分的 Azure 门户中找到 Batch 和存储帐户凭据。


触发函数并检索结果
将 input_files GitHub 上目录中的任何或所有扫描文件上传到输入容器。
可以在 Azure 门户的函数代码 + 测试页上测试你的函数。
- 在“代码 + 测试”页上选择“测试/运行”。
- 在“输入”选项卡的“正文”中输入容器的路径。
- 选择 运行。
几秒钟后,应用 OCR 的文件将添加到输出容器。 日志信息输出到窗口底部。 然后,该文件在存储资源管理器上可见且可检索。
或者,可以在 “监视 ”页上找到日志信息:
2019-05-29T19:45:25.846 [Information] Creating job...
2019-05-29T19:45:25.847 [Information] Accessing input container <inputContainer>...
2019-05-29T19:45:25.847 [Information] Adding <fileName> as a resource file...
2019-05-29T19:45:25.848 [Information] Name of output text file: <outputTxtFile>
2019-05-29T19:45:25.848 [Information] Name of output PDF file: <outputPdfFile>
2019-05-29T19:45:26.200 [Information] Adding OCR task <taskID> for <fileName> <size of fileName>...
若要将输出文件下载到本地计算机,请转到存储帐户中的输出容器。 选择所需文件上的更多选项,然后选择“ 下载”。
小窍门
如果在 PDF 阅读器中打开,则可搜索下载的文件。
清理资源
即使没有计划任何作业,也会在节点运行时为池付费。 不再需要池时,请按照以下步骤将其删除:
- 在 Batch 帐户的 “池 ”页中,选择池上的更多选项。
- 选择 删除。
删除池时会删除节点上的所有任务输出。 但是,输出文件保留在存储帐户中。 不再需要时,还可以删除 Batch 帐户和存储帐户。
后续步骤
有关使用 .NET API 计划和处理 Batch 工作负载的更多示例,请参阅 GitHub 上的示例。