容器化应用程序可能会运行较长时间,从而导致进入可能需要通过重启容器来修复的损坏状态。 Azure 容器实例支持运行状况探测,以便你可以将容器组中的容器配置为在关键功能未正常工作时重启。 该运行情况探测的行为类似于 Kubernetes 运行情况探测。
本文介绍了如何部署包括运行情况探测的容器组,演示了模拟的不正常容器的自动重启。
Azure 容器实例还支持就绪情况探测,你可以对其进行配置,以确保仅当容器为流量准备就绪时,流量才到达容器。
YAML 部署
创建包含下面的代码片段的 liveness-probe.yaml 文件。 此文件定义了一个包含最终变得不正常的 NGINX 容器的容器组。
apiVersion: 2019-12-01
location: chinaeast2
name: livenesstest
properties:
containers:
- name: mycontainer
properties:
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
command:
- "/bin/sh"
- "-c"
- "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
ports: []
resources:
requests:
cpu: 1.0
memoryInGB: 1.5
livenessProbe:
exec:
command:
- "cat"
- "/tmp/healthy"
periodSeconds: 5
osType: Linux
restartPolicy: Always
tags: null
type: Microsoft.ContainerInstance/containerGroups
运行以下命令来使用前面的 YAML 配置部署此容器组:
az container create --resource-group myResourceGroup --name livenesstest -f liveness-probe.yaml
“启动”命令
部署包含了 command 属性,该属性定义在容器首次开始运行时运行的启动命令。 该属性接受字符串数组。 该命令模拟进入不正常状态的容器。
首先,它会启动一个 bash 会话,并在 /tmp 目录中创建一个名为healthy的文件。 然后,它休眠 30 秒,之后删除该文件,之后进入 10 分钟的休眠:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
运行情况命令
此部署定义了一个 livenessProbe,它支持充当运行情况检查的 exec 运行情况命令。 如果此命令以非零值退出,则将终止并重启该容器,表明找不到 healthy 文件。 如果此命令以退出代码 0 成功退出,则不会采取任何操作。
periodSeconds 属性指定运行情况命令应当每 5 秒执行一次。
验证运行情况输出
在前 30 秒内,启动命令创建的 healthy 文件存在。 当运行情况命令检查 healthy 文件是否存在时,状态代码返回零,表示成功,因此不会重启。
在 30 秒后,cat /tmp/healthy 命令将开始失败,导致不正常的和终止事件发生。
可以通过 Azure 门户或 Azure CLI 查看这些事件。
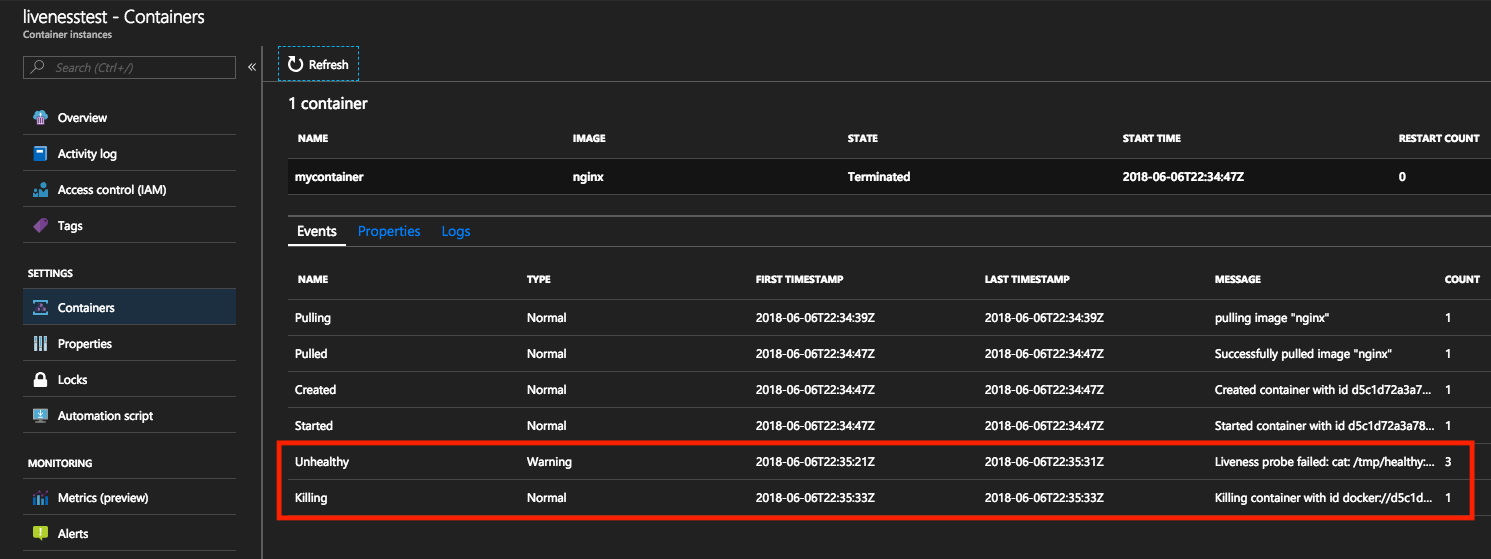
通过在 Azure 门户中查看事件,在运行情况命令失败时将触发 Unhealthy 类型的事件。 后续事件将是 Killing 类型事件,表示容器已删除,因此可以开始重启。 容器的重启计数在每次发生此事件时递增。
重启是就地完成的,因此,诸如公共 IP 地址和节点特定的内容都将保留。

如果运行情况探测连续失败,并且触发了太多次重启,则容器将进入指数后退延迟。
运行情况探测和重启策略
重启策略会取代由运行情况探测触发的重启行为。 例如,如果设置了 restartPolicy = Never 以及运行状况探测,则容器组不会由于失败的运行状况探测而重启。 容器组将改为遵守容器组的重启策略 Never。
后续步骤
基于任务的方案可能会要求运行状况探测在先决条件功能工作不正常时支持自动重启。 若要详细了解如何运行基于任务的容器,请参阅在 Azure 容器实例中运行容器化任务。