适用对象:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() 格林姆林
格林姆林
适用于Azure Cosmos DB 的 Azure Synapse Link 是一种云原生混合事务和分析处理 (HTAP) 功能,可实现对 Azure Cosmos DB 中的操作数据进行准实时分析。 Azure Synapse Link 在 Azure Cosmos DB 和 Azure Synapse Analytics 之间建立紧密无缝的集成。
可将 Azure Cosmos DB 分析存储(完全隔离的列存储)与 Azure Synapse Link 结合使用,以在 Azure Synapse Analytics 中针对大规模操作数据启用提取-转换-加载 (ETL) 分析。 业务分析师、数据工程师和数据科学家现在可以互换使用 Synapse Spark 或 Synapse SQL 来运行准实时商业智能、分析和机器学习管道。 你可以分析实时数据,而不会影响 Azure Cosmos DB 上的事务工作负载的性能。
下图显示了 Azure Synapse Link 与 Azure Cosmos DB 和 Azure Synapse Analytics 的集成:
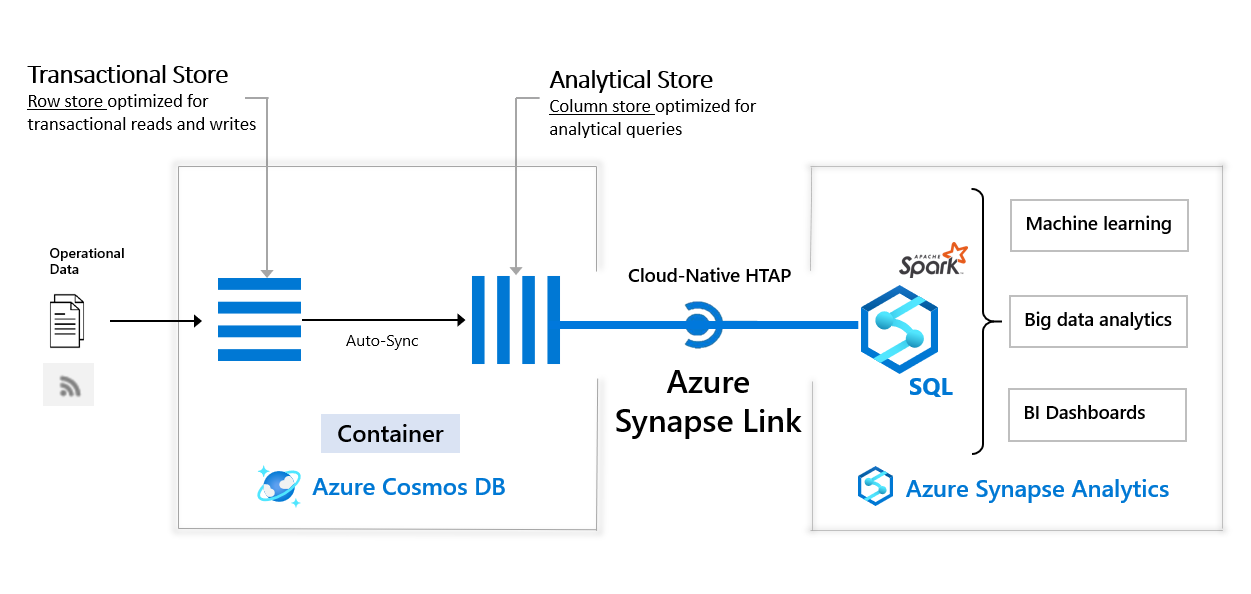
为了分析大型操作数据集,同时最大程度地减少对任务关键型事务工作负载的性能影响,Azure Cosmos DB 一直以来会导出操作数据。 这些操作由提取-转换-加载 (ETL) 管道执行,这些管道需要许多层的数据和作业管理,从而导致操作复杂性,并对事务工作负载产生性能影响。 还会增加延迟以从原始时间分析操作数据。
与传统的基于 ETL 的解决方案相比,Azure Synapse Link for Azure Cosmos DB 提供了多种优势,例如:
借助 Azure Synapse Link,可以使用 Azure Synapse Analytics 直接访问 Azure Cosmos DB 分析存储,无需进行复杂的数据移动。 对操作数据所做的任何更新都准实时显示在分析存储中,不包含任何 ETL 或更改源作业。 可从 Azure Synapse Analytics 针对分析存储运行大规模分析,无需额外的数据转换。
使用 Azure Synapse Link,现在可以准实时深入了解操作数据。 由于有许多层需要提取、转换和加载操作数据,因此基于 ETL 的系统在分析操作数据时往往会产生较高的延迟。 通过 Azure Cosmos DB 分析存储与 Azure Synapse Analytics 的本机集成,可以准实时分析操作数据,从而启用新的业务方案。
使用 Azure Synapse Link,可以针对 Azure Cosmos DB 分析存储(数据的列存储表示形式)运行分析查询。 可以在运行查询的同时,通过 Azure Cosmos DB 基于行的事务存储使用事务工作负载的预配吞吐量处理事务操作。 分析工作负载独立于事务工作负载流量,而不会消耗你为操作数据分配的吞吐量。
Azure Cosmos DB 分析存储已经过优化,可为分析工作负荷提供可伸缩性、弹性和性能,无需依赖计算运行时。 存储技术是自行管理,可优化分析工作负荷。 通过对 Azure Synapse Analytics 的内置支持,访问此存储层可提供简单性和高性能。
借助 Azure Synapse Link,可以为运营分析获取成本优化且完全托管的解决方案。 它不再需要用于分析操作数据的传统 ETL 管道所需的额外存储层和计算层。
Azure Cosmos DB 分析存储遵循基于消耗的定价模型,该模型基于数据存储和分析读/写操作以及已执行的查询。 它不要求你像现在对事务工作负载所做的那样分配任何吞吐量。 通过 Azure Synapse Analytics 中极具弹性的计算引擎来访问你的数据,使运行存储和计算的总体成本非常高效。
你可以高效地对 Azure Cosmos DB 中距离最近的区域的数据副本运行分析查询。 Azure Cosmos DB 提供了最先进的功能,可按主动-主动的方式运行多区域分发的分析工作负载和事务工作负载。
Azure Synapse Link 汇集了 Azure Cosmos DB 分析存储和 Azure Synapse Analytics 运行时支持。 通过此集成,你可以构建云原生 HTAP解决方案,该解决方案基于大型数据集上操作数据的实时更新生成见解。 它可解锁新的业务方案,以根据实时趋势发出警报,构建准实时仪表板并基于用户行为生成业务体验。
Azure Cosmos DB 分析存储是 Azure Cosmos DB 中的操作数据的面向列的表示形式。 此分析存储适用于对大型操作数据集进行快速且经济高效的查询。 此存储可以在不复制数据且不影响事务工作负载性能的情况下查询数据。
分析存储准实时自动选择事务工作负荷中的高频率插入、更新、删除,作为 Azure Cosmos DB 的完全托管功能(“自动同步”)。 无需更改源或 ETL。
如果你拥有多区域分发的 Azure Cosmos DB 帐户,为容器启用分析存储后,它将适用于该帐户的所有区域。 有关分析存储的详细信息,请参阅 Azure Cosmos DB 分析存储概述一文。
借助 Azure Synapse Link,你现在可以直接从 Azure Synapse Analytics 连接到 Azure Cosmos DB 容器,并访问没有单独连接器的分析存储。 Azure Synapse Analytics 目前支持具有 Synapse Apache Spark 和无服务器 SQL 池的 Azure Synapse Link。
可以在 Azure Synapse Analytics 支持的不同分析运行时间内以互操作方式同时从 Azure Cosmos DB 分析存储查询数据。 不需要其他数据转换来分析操作数据。 可以使用以下对象来查询和分析分析存储数据:
完全支持 Scala、Python、SparkSQL 和 C# 的 Synapse Apache Spark。 Synapse Spark 是数据工程和数据科学方案的核心
采用 T-SQL 语言且支持熟悉的 BI 工具(例如 Power BI Premium 等)的无服务器 SQL 池
备注
通过 Azure Synapse Analytics,可以同时访问 Azure Cosmos DB 容器中的分析存储和事务存储。 但是,如果要对操作数据运行大规模分析或扫描,我们建议你使用分析存储来避免对事务工作负荷的性能影响。
备注
可以通过将 Azure Cosmos DB 容器连接到 Azure 区域中的 Synapse 运行时,在该区域中以较低的延迟运行分析。
此集成可为不同用户启用以下 HTAP 方案:
BI 工程师,想要对 Power BI 报表建模后将其发布,以便通过 Synapse SQL 直接访问 Azure Cosmos DB 中的实时操作数据。
数据分析人员,想要通过使用 Synapse SQL 查询 Azure Cosmos DB 容器中的操作数据来从中获得见解,大规模读取数据并将这些发现与其他数据源合并。
数据科学家,想要使用 Synapse Spark 查找一项功能来改善其模型,并在不进行复杂的数据工程的情况下训练该模型。 他们还可以将模型推理的结果写入 Azure Cosmos DB 以便通过 Spark Synapse 对数据进行实时评分。
某位数据工程师想要无需手动 ETL 过程即可对 Azure Cosmos DB 容器创建 SQL 或 Spark 表,以便使数据可供使用者访问。
有 Azure Cosmos DB 的 Azure Synapse Analytics 运行时支持的详细信息,请参阅 用于 Azure Cosmos DB 的 Azure Synapse Analytics 支持。
如果你是 Azure Cosmos DB 客户,并且想要对操作数据运行分析、BI 和机器学习,建议使用 Azure Synapse Link。 例如:
如果你现在直接使用单独的连接器对 Azure Cosmos DB 操作数据运行分析或 BI,或者
如果你正在运行 ETL 过程以将操作数据提取到单独的分析系统中。
在此类情况下,Azure Synapse Link 提供了更集成的分析体验,同时不影响事务存储的预配吞吐量。
如果你需要满足传统的数据仓库要求,则不建议使用 Azure Synapse Link。 这些要求可能包括高并发、工作负载管理和跨多个数据源的聚合持久性。 有关详细信息,请参阅可由适用于Azure Cosmos DB 的 Azure Synapse Link 提供帮助的常见方案。
NoSQL、Gremlin 和 MongoDB API 支持面向 Azure Cosmos DB 的 Azure Synapse Link。 Cassandra 或表 API 则不支持它。
Synapse 工作区中的数据资源管理器不会在树视图中列出 Gremlin 图形。 但你仍然可以运行查询。
当前不支持通过 Azure Synapse 专用 SQL 池访问 Azure Cosmos DB 分析存储。
尽管分析存储数据由于未备份而无法还原,但可以通过在恢复的容器中重新启用 Azure Synapse Link 来重新生成分析存储。 有关详细信息,请参阅分析存储文档。
目前,从容器禁用 Synapse Link 的客户无法迁移到连续备份。 如果是这种情况,请与我们联系: cosmosdbsynapselink@microsoft.com
从 Synapse 进行查询时,不支持精细的基于角色的访问控制。 有权访问 Synapse 工作区并有权访问 Azure Cosmos DB 帐户的用户可以访问该帐户中的所有容器。 我们目前不支持对容器进行更精细的访问。
目前 Azure Synapse 工作区不支持使用
Managed Identity的链接服务。 请始终使用MasterKey选项。目前,不建议将多区域写入帐户用于生产环境。
通过 Azure Synapse Link,可以对 Azure Cosmos DB 中的关键任务数据运行准实时分析。 务必确保关键业务数据安全地存储在事务和分析存储区中。 适用于 Azure Cosmos DB 的 Azure Synapse Link 旨在通过以下功能帮助满足这些安全要求:
使用专用终结点的网络隔离 - 可以单独控制对事务性和分析存储中的数据的网络访问。 在 Azure Synapse 工作区的托管虚拟网络内,为每个存储使用单独的托管专用终结点进行网络隔离。 如要了解详细信息,请参阅如何为分析存储配置专用终结点一文。
使用客户管理的密钥进行数据加密 - 可以采用自动且透明的方式使用相同的客户管理密钥无缝地跨事务存储和分析存储加密数据。 Azure Synapse Link 仅支持使用 Azure Cosmos DB 帐户的托管标识配置客户管理的密钥。 在帐户上启用 Azure Synapse Link 之前,必须在 Azure Key Vault 访问策略中配置帐户的托管标识。 若要了解详细信息,请参阅如何使用 Azure Cosmos DB 帐户的托管标识配置客户管理的密钥一文。
安全密钥管理 - 从 Synapse Spark 和 Synapse 无服务器 SQL 池中访问分析存储中的数据,需要用户对 Synapse Analytics 工作区中 的 Azure Cosmos DB 密钥进行管理。 Azure Synapse Link 提供了更安全的功能,代替了在 Spark 作业或 SQL 脚本中以内联方式使用 Azure Cosmos DB 帐户密钥这种方式:
使用 Synapse 无服务器 SQL 池时,可以通过预先创建用于存储帐户密钥的 SQL 凭据并在
OPENROWSET函数中引用这些密钥来查询 Azure Cosmos DB 分析存储。 如要了解详细信息,请参阅在 Azure Synapse Link 中使用无服务器 SQL 池进行查询一文。使用 Synapse Spark 时,可以将帐户密钥存储在指向 Azure Cosmos DB 数据库的链接服务对象中,并在运行时在 Spark 配置中引用密钥。 如要了解详细信息,请参阅使用 Apache Spark 将数据复制到专用的 SQL 池中一文。
Azure Synapse Link 的计费模型包括使用 Azure Cosmos DB 分析存储和 Synapse 运行时所产生的成本。 若要了解详细信息,请参阅 Azure Cosmos DB 分析存储定价和 Azure Synapse Analytics 定价文章。
若要了解更多信息,请参阅下列文档: