重要
你是否正在寻找一种数据库解决方案,以应对需要高扩展性、99.999% 可用性服务级别协议(SLA)、即时自动扩展和跨多个区域的自动故障转移的场景? 请考虑使用 Azure Cosmos DB for NoSQL。
使用 Azure Cosmos DB for MongoDB,可以使用索引来加快查询性能。 本文介绍如何管理和优化索引,以加快数据检索和提高效率。
适用于 MongoDB 服务器 3.6 及更高版本的索引编制功能
Azure Cosmos DB for MongoDB 服务器版本 3.6+ 会自动为 _id 字段和分片键(仅在分片集合中)编制索引。 API 强制每个分片键的 _id 字段保持唯一性。
用于 MongoDB 的 API 的工作方式与默认情况下为所有字段编制索引的 Azure Cosmos DB for NoSQL 不同。
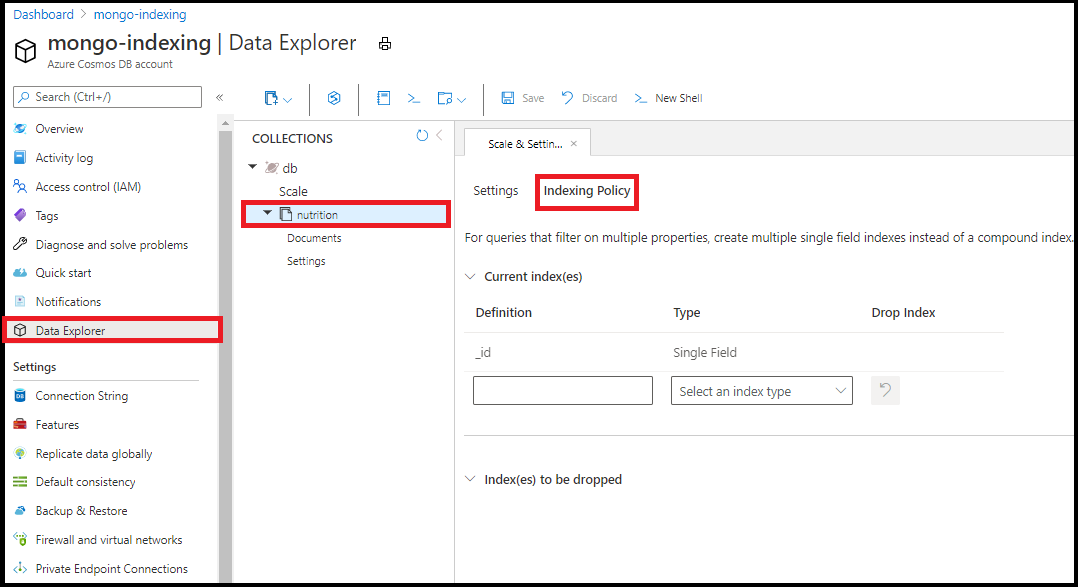
编辑索引策略
在 Azure 门户中的数据资源管理器中编辑索引策略。 从数据资源管理器中的索引策略编辑器中添加单个字段和通配符索引:
注释
无法使用数据资源管理器中的索引策略编辑器来创建复合索引。
索引类型
单个字段
在任何单个字段上创建索引。 单个字段索引的排序顺序无关紧要。 使用以下命令在字段 name上创建索引:
db.coll.createIndex({name:1})
在 Azure 门户中将单字段索引创建在 name 相同的位置:
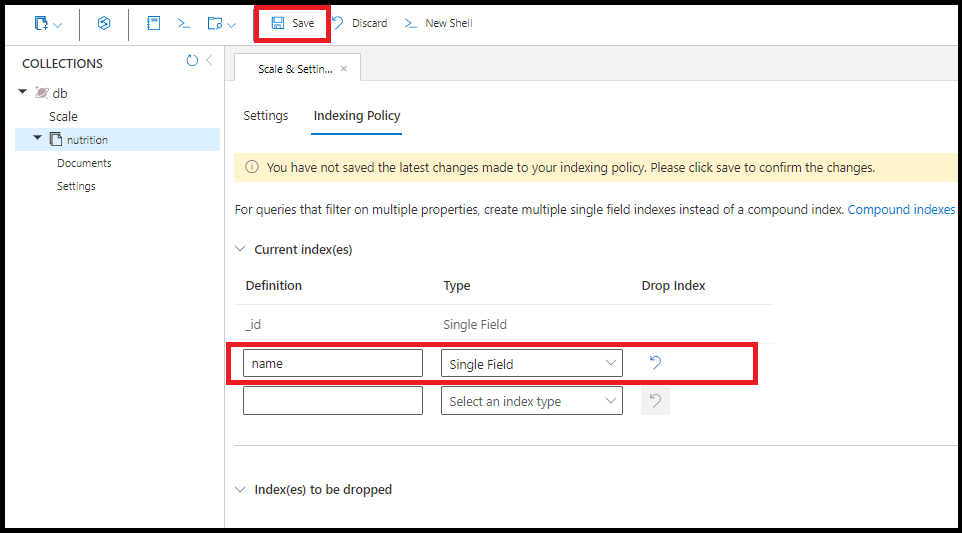
查询使用多个可用的单字段索引。 每个集合最多创建 500 个单个字段索引。
复合索引(MongoDB 服务器版本 3.6+)
在 MongoDB 的 API 中,使用复合索引来处理对多个字段同时排序的查询。 对于包含多个不需要排序的筛选器的查询,请创建多个单字段索引而不是一个复合索引,以便节省索引编制成本。
复合索引中每个字段的复合索引或单个字段索引会导致查询中筛选的性能相同。
由于数组的限制,嵌套字段上的复合索引默认不受支持。 如果嵌套字段没有数组,索引将按预期工作。 如果嵌套字段在路径上的任意位置都有数组,则索引中忽略该值。
例如,包含 people.dylan.age 复合索引在此示例中有效,因为路径上没有数组:
{
"people": {
"dylan": {
"name": "Dylan",
"age": "25"
},
"reed": {
"name": "Reed",
"age": "30"
}
}
}
在这种情况下,相同的复合索引不起作用,因为路径中有一个数组:
{
"people": [
{
"name": "Dylan",
"age": "25"
},
{
"name": "Reed",
"age": "30"
}
]
}
通过 启用“EnableUniqueCompoundNestedDocs”功能为数据库帐户启用此功能。
注释
不能基于数组创建复合索引。
以下命令对字段 name 和 age 创建复合索引:
db.coll.createIndex({name:1,age:1})
可以使用复合索引来同时对多个字段进行高效排序,如以下示例中所示:
db.coll.find().sort({name:1,age:1})
还可以使用前面的复合索引,在一个查询中对所有字段按相反顺序进行高效排序。 下面是一个示例:
db.coll.find().sort({name:-1,age:-1})
但是,复合索引中的路径顺序必须与查询完全匹配。 下面是需要额外复合索引的查询示例:
db.coll.find().sort({age:1,name:1})
多键索引
Azure Cosmos DB 创建多键索引,为数组中的内容编制索引。 如果为具有数组值的字段编制索引,Azure Cosmos DB 会自动为数组中的每个元素编制索引。
空间索引
许多地理空间操作员利用地理空间索引。 Azure Cosmos DB for MongoDB 支持 2dsphere 索引。 API 尚不支持 2d 索引。
下面是对 location 字段创建地理空间索引的示例:
db.coll.createIndex({ location : "2dsphere" })
文本索引
Azure Cosmos DB for MongoDB 不支持文本索引。 对于字符串的文本搜索查询,请使用 Azure AI 搜索与 Azure Cosmos DB 的集成。
通配符索引
使用通配符索引支持针对未知字段的查询。 假设一个集合包含有关家庭的数据。
下面是该集合中示例文档的一部分:
"children": [
{
"firstName": "Henriette Thaulow",
"grade": "5"
}
]
这是另一个示例,其中children具有一组不同的属性。
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"pets": [
{ "givenName": "Goofy" },
{ "givenName": "Shadow" }
]
},
{
"familyName": "Merriam",
"givenName": "John",
}
]
此集合中的文档可以具有许多不同的属性。 若要为数组中的所有 children 数据编制索引,请为每个属性创建单独的索引,或为整个 children 数组创建一个通配符索引。
创建通配符索引
使用以下命令在以下 children任意属性上创建通配符索引:
db.coll.createIndex({"children.$**" : 1})
- 与在 MongoDB 中不同,通配符索引可以在查询谓词中支持多个字段。 如果使用单个通配符索引而不是为每个属性创建单独的索引,则查询性能没有区别。
使用通配符语法创建以下索引类型:
- 单个字段
- 地理空间
为所有属性编制索引
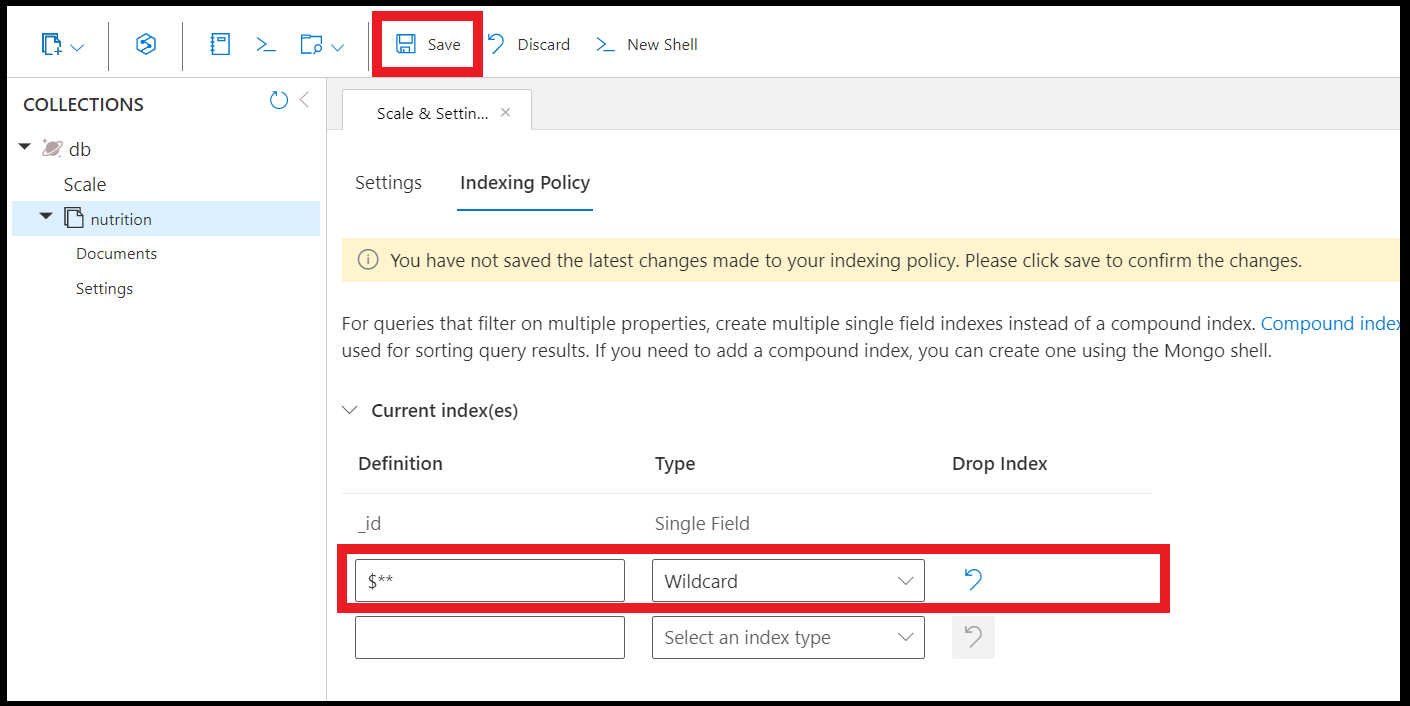
使用以下命令在所有字段上创建通配符索引:
db.coll.createIndex( { "$**" : 1 } )
在 Azure 门户中使用数据资源管理器创建通配符索引:
注释
如果刚开始进行开发,请先为每个字段设置通配符索引。 此方法简化了开发,并更易于优化查询。
具有许多字段的文档在写入和更新时会有较高的请求单位 (RU) 消耗。 如果您的工作负载主要是写操作,建议使用单独编制索引的路径,而不是使用通配符。
局限性
通配符索引不支持以下任何索引类型或属性:
化合物
TTL
唯一
与 MongoDB 不同,在 Azure Cosmos DB for MongoDB 中,不能对以下项使用通配符索引:
创建包含多个特定字段的通配符索引
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection " : { "children.givenName" : 1, "children.grade" : 1 } } )创建排除多个特定字段的通配符索引
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection" : { "children.givenName" : 0, "children.grade" : 0 } } )
或者,创建多个通配符索引。
索引属性
对于使用线协议版本 4.0 以及更早版本的帐户,以下操作很常见。 详细了解 支持的索引和索引属性。
唯一索引
唯一索引 有助于确保两个或多个文档的索引字段的值不相同。
运行以下命令,在字段上 student_id 创建唯一索引:
db.coll.createIndex( { "student_id" : 1 }, {unique:true} )
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 4
}
对于分片集合,请提供分片(分区)键来创建唯一索引。 分片集合上的所有唯一索引都是复合索引,其中一个字段是分片键。 分片键应该是索引定义中的第一个字段。
运行以下命令,创建一个名为coll的分片集合(使用university作为分片键),并在student_id和university字段上创建唯一索引:
db.runCommand({shardCollection: db.coll._fullName, key: { university: "hashed"}});
{
"_t" : "ShardCollectionResponse",
"ok" : 1,
"collectionsharded" : "test.coll"
}
db.coll.createIndex( { "university" : 1, "student_id" : 1 }, {unique:true});
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 3,
"numIndexesAfter" : 4
}
如果省略上述示例中的 "university":1 子句,则会看到以下错误消息:
cannot create unique index over {student_id : 1.0} with shard key pattern { university : 1.0 }
局限性
集合为空时创建唯一索引。
具有 连续备份 的 Azure Cosmos DB for MongoDB 帐户不支持为现有集合创建唯一索引。 对于此类帐户,必须创建唯一索引及其集合创建,这必须且只能使用创建集合 扩展命令来完成。
db.runCommand({customAction:"CreateCollection", collection:"coll", shardKey:"student_id", indexes:[
{key: { "student_id" : 1}, name:"student_id_1", unique: true}
]});
由于数组的限制,默认不支持嵌套字段上的唯一索引。 如果嵌套字段没有数组,索引将按预期方式工作。 如果嵌套字段在路径的任意位置存在数组,则该值会被忽略在唯一索引中,并且无法保持该值的唯一性。
例如,在这种情况下,唯一索引 people.tom.age 有效,因为路径上没有数组:
{
"people": {
"tom": {
"age": "25"
},
"mark": {
"age": "30"
}
}
}
但在这种情况下不起作用,因为路径中有一个数组:
{
"people": {
"tom": [
{
"age": "25"
}
],
"mark": [
{
"age": "30"
}
]
}
}
可通过启用“EnableUniqueCompoundNestedDocs”功能为数据库帐户启用此功能。
TTL 索引
若要让文档在集合中过期,请创建 生存时间(TTL)索引。 TTL 索引是具有 _ts 值的 expireAfterSeconds 字段上的索引。
示例:
db.coll.createIndex({"_ts":1}, {expireAfterSeconds: 10})
上述命令删除集合中 db.coll 修改时间超过 10 秒的任何文档。
注释
_ts字段特定于 Azure Cosmos DB,无法从 MongoDB 客户端访问。 它是一个保留的(系统)属性,其中包含文档上次修改的时间戳。
跟踪索引进度
Azure Cosmos DB for MongoDB 3.6+ 版本支持 currentOp() 命令,用于追踪数据库实例上的索引进度。 此命令返回一个文档,其中包含有关数据库实例正在进行的操作的信息。 使用 currentOp 命令来跟踪正在进行的本机 MongoDB 的所有操作。 在 Azure Cosmos DB for MongoDB 中,此命令仅跟踪索引作。
下面是有关如何使用 currentOp 命令跟踪索引进度的一些示例:
获取集合的索引进度:
db.currentOp({"command.createIndexes": <collectionName>, "command.$db": <databaseName>})获取数据库中所有集合的索引进度:
db.currentOp({"command.$db": <databaseName>})获取 Azure Cosmos DB 帐户中所有数据库和集合的索引进度:
db.currentOp({"command.createIndexes": { $exists : true } })
索引进度输出示例
索引进度详细信息显示当前索引操作的进度百分比。 下面是索引进度处于不同阶段时输出文档格式的示例:
对“foo”集合和“bar”数据库的索引操作已完成 60%,有以下输出文档。
Inprog[0].progress.total字段将 100 显示为目标完成百分比。{ "inprog": [ { ... "command": { "createIndexes": foo "indexes": [], "$db": bar }, "msg": "Index Build (background) Index Build (background): 60 %", "progress": { "done": 60, "total": 100 }, ... } ], "ok": 1 }如果索引操作刚刚在“foo”集合和“bar”数据库上启动,则输出文档最初可能显示 0%的进度,直到达到可测量的程度。
{ "inprog": [ { ... "command": { "createIndexes": foo "indexes": [], "$db": bar }, "msg": "Index Build (background) Index Build (background): 0 %", "progress": { "done": 0, "total": 100 }, ... } ], "ok": 1 }索引操作完成后,输出文档会显示空
inprog操作。{ "inprog" : [], "ok" : 1 }
后台索引更新
无论为 Background 索引属性设置的值,索引更新始终在后台运行。 由于索引更新使用的请求单位(RU)优先级低于其他数据库操作,因此索引更改不会导致写入、更新或删除操作停机。
添加新索引不会影响读取可用性。 查询仅在索引转换完成后才使用新索引。 在转换期间,查询引擎会继续使用现有索引,因此在开始索引更改之前,会看到类似的读取性能。 添加新索引不会导致查询结果不完整或不一致。
如果删除索引并立即运行针对这些已删除索引进行筛选的查询,则结果可能会不一致且不完整,直到索引转换完成。 查询引擎不会为筛选新删除索引的查询提供一致或完整的结果。 大多数开发人员不会删除索引,然后立即查询它们,因此这种情况不太可能。
注释
可以跟踪索引进度。
reIndex 命令
该 reIndex 命令重新创建集合上的所有索引。 在极少数情况下,运行 reIndex 命令可以修复集合中的查询性能或其他索引问题。 如果遇到索引问题,请尝试使用 reIndex 命令重新创建索引。
使用以下语法运行reIndex命令:
db.runCommand({ reIndex: <collection> })
使用以下语法检查运行 reIndex 命令是否提高了集合中的查询性能:
db.runCommand({"customAction":"GetCollection",collection:<collection>, showIndexes:true})
示例输出:
{
"database": "myDB",
"collection": "myCollection",
"provisionedThroughput": 400,
"indexes": [
{
"v": 1,
"key": {
"_id": 1
},
"name": "_id_",
"ns": "myDB.myCollection",
"requiresReIndex": true
},
{
"v": 1,
"key": {
"b.$**": 1
},
"name": "b.$**_1",
"ns": "myDB.myCollection",
"requiresReIndex": true
}
],
"ok": 1
}
如果 reIndex 能提高查询性能,那么 requiresReIndex 就为 true。 如果reIndex未提高查询性能,则会省略此属性。
将带有索引的数据库集合进行迁移
仅当集合没有文档时,才能创建唯一索引。 常见的 MongoDB 迁移工具尝试在导入数据后创建唯一索引。 若要解决此问题,请手动创建相应的集合和唯一索引,而不是让迁移工具尝试。 通过在命令行中使用--noIndexRestore标志来实现mongorestore的行为。
适用于 MongoDB 版本 3.2 的索引编制功能
使用 MongoDB 线路协议版本 3.2 的 Azure Cosmos DB 帐户的索引功能和默认值有所不同。 在 功能支持-36.md#协议支持中检查帐户的版本,并在 upgrade-version.md 升级到版本 3.6。
如果使用版本 3.2,本部分重点介绍版本 3.6 及更高版本的主要差异。
删除默认索引(版本 3.2)
与版本 3.6 及更高版本不同,Azure Cosmos DB for MongoDB 版本 3.2 默认为每个属性编制索引。 使用以下命令删除集合的这些默认索引(coll):
db.coll.dropIndexes()
{ "_t" : "DropIndexesResponse", "ok" : 1, "nIndexesWas" : 3 }
删除默认索引后,像在版本 3.6 及更高版本中那样添加更多索引。
复合索引(版本 3.2)
复合索引引用文档中的多个字段。 若要创建复合索引,请在 upgrade-version.md 升级到版本 3.6 或 4.0。
通配符索引(版本 3.2)
若要创建通配符索引,请在 upgrade-version.md 升级到版本 4.0 或 3.6。