在 Azure Cosmos DB for PostgreSQL 中选择分布列
适用对象:![]() PostgreSQL 的 Azure Cosmos DB (由 PostgreSQL 的 Citus 数据库扩展提供支持)
PostgreSQL 的 Azure Cosmos DB (由 PostgreSQL 的 Citus 数据库扩展提供支持)
选择每个表的分发列是你将做出的最重要的建模决策之一。 Azure Cosmos DB for PostgreSQL 根据行的分布列值在分片中存储行。
正确的选择会将相关数据一起分组到相同物理节点上,从而可使查询快速运行,并添加对所有 SQL 功能的支持。 不正确的选择会使系统运行缓慢。
一般技巧
下面是为分布式表选择理想分布列的四个条件。
选取作为应用程序工作负荷中核心部分的列。
可将此列视为分区数据的“核心”、“中心部分”或“自然维度”。
示例:
- IoT 工作负荷中的
device_id - 金融应用用于跟踪证券的
security_id - 用户分析中的
user_id - 用于多租户 SaaS 应用程序的
tenant_id
- IoT 工作负荷中的
选取基数大且统计分布均匀的列。
该列应具有多个值,并且在所有分片之间完全均匀分布。
示例:
- 超过 1000 的基数
- 不要选取在大部分行上具有相同值的列(数据倾斜)
- 在 SaaS 工作负荷中,一个租户比其余租户大得多可能会导致数据倾斜。 在这种情况下,可以使用租户隔离创建专用分片,以处理租户。
有利于现有查询的列。
对于事务性或操作性工作负载(其中大多数查询只需要几毫秒),请选择一个在至少 80% 的查询的
WHERE子句中显示为筛选器的列。 例如,SELECT * FROM events WHERE device_id=1中的device_id列。对于分析工作负载(其中大多数查询需要 1-2 秒),请选择一个支持跨工作器节点并行化查询的列。 例如,经常出现在 GROUP BY 子句中的列,或者一次查询多个值的列。
选取大多数大型表中存在的列。
应该分布超过 50 GB 的表。 通过为所有这些表选取相同的分布列,可以在工作器节点上并置列的数据。 通过并置,可以高效地运行 JOIN 和汇总,并强制实施外键。
其他(较小的)表可以是本地表或引用表。 如果较小的表需要与分布式表联接,请将其设为引用表。
用例
我们已经了解选择分布列的一般标准。 现在,让我们看看常见用例中是如何应用这些标准。
多租户应用
多租户体系结构使用一种分层数据库建模形式,以跨群集中的节点分配查询。 数据层次结构的顶部称为“租户 ID”,需要存储在每个表的列中。
Azure Cosmos DB for PostgreSQL 检查查询项目,以查看其涉及的租户 ID,并找到匹配表分片。 它将查询路由到包含分片的单个工作器节点。 在同一节点上运行包含所有相关数据的查询称为归置。
下图说明了多租户数据模型中的归置。 它包含两个表:帐户和 Campaigns,每个表由 account_id 分布。 阴影框代表分片。 绿色分片存储在一个工作器节点上,而蓝色分片存储在另一个工作器节点上。 请注意,当两个表都限制为同一 account_id 时,帐户和 Campaigns 之间的联接查询如何将所有必要的数据包含在同一个节点上。
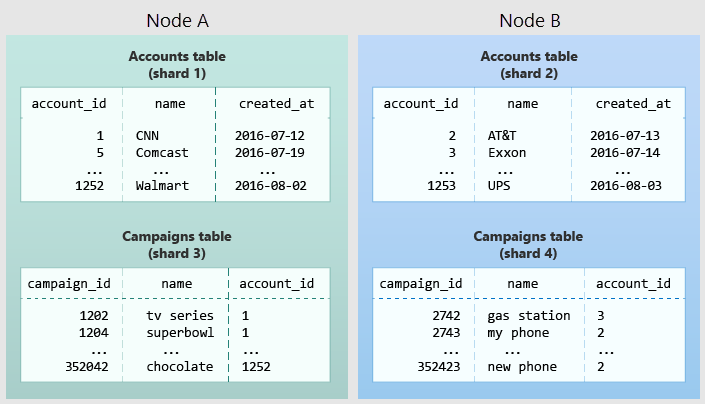
若要在自己的架构中应用此设计,请确定在应用程序中构成租户的内容。 常见的实例包括公司、帐户、组织或客户。 列名将类似于 company_id 或 customer_id。 检查每个查询并问自己,如果有更多 WHERE 子句来将涉及的所有表限制为具有相同租户 ID 的行,它是否起作用? 多租户模型中的查询的作用域为租户。 例如,针对销售或库存的查询作用域在特定商店内。
最佳做法
- 按常见 tenant_id 列分布表。 例如,在租户为公司的 SaaS 应用程序中,tenant_id 很可能是 company_id。
- 将小型跨租户表转换为引用表。 当多个租户共享一个较小的信息表时,将它作为引用表进行分布。
- 按 tenant_id 限制筛选所有应用程序查询。 每次查询只能请求一个租户的信息。
有关如何生成此类应用程序的示例,请参阅多租户教程。
实时应用
多租户体系结构引入了一个层次结构,并使用数据归置来路由每个租户的查询。 与此相反,实时体系结构依赖于其数据的特定分布属性来实现高度并行的处理。
我们在实时模型中使用“实体 ID”作为分布列的术语。 典型实体是用户、主机或设备。
实时查询通常要求按日期或类别分组的数值聚合。 Azure Cosmos DB for PostgreSQL 将这些查询发送到每个分片以获得部分结果,并将最终答案汇编到协调器节点。 当尽可能多的节点参与,并且没有单个节点必须执行不成比例的工作量时,查询运行速度最快。
最佳做法
- 选择一个具有高基数的列作为分布列。 如果要进行比较,如果订单表具有“新”、“已支付”和“已发货”值,则“状态”字段不是适当的分布列选择。 该字段仅假定这几个值,它们限制了可容纳数据的分片的数目,以及可处理数据的节点数。 在具有高基数的列中,选择那些经常用于“分组依据”子句或用作联接键的列也是不错的选择。
- 选择包含均匀分布的列。 如果根据偏向特定公用值的列进行表分布,则表中的数据往往会累积到特定分片。 最终保存这些分片的节点所做的工作多于其他节点。
- 将事实数据表和维度表分布在其通用列上。 事实数据表只能有一个分布键。 联接其他键的表将不会与事实数据表相连接。 根据联接的频率和联接行的大小,选择要归置的一个维度。
- 将一些维度表更改为引用表。 如果维度表不能与事实数据表一起使用,则可以通过将维度表的副本以引用表的形式分布到所有节点,从而提高查询性能。
有关如何生成此类应用程序的示例,请阅读实时仪表板教程。
时序数据
在时序工作负载中,应用程序会在存档旧信息时查询最新信息。
在 Azure Cosmos DB for PostgreSQL 中对时序信息进行建模时,最常见的错误是使用时间戳本身作为分布列。 基于时间的哈希分布时间似乎随机将时间分布于不同的分片,而不是在分片中同时保留时间范围。 涉及时间的查询通常引用时间范围,例如,最新的数据。 这种类型的哈希分布会导致网络开销。
最佳做法
- 不要选择时间戳作为分布列。 选择不同的分布列。 在多租户应用中,使用租户 ID,或在实时应用中使用实体 ID。
- 改为使用时间分区的 PostgreSQL 表。 使用表分区可将大量有时间顺序的数据分解成多个继承表,其中每个表都包含不同的时间范围。 分配 Postgres 分区表可为继承的表创建分片。