Azure Data Lake Storage 是一种用于大数据分析的数据湖解决方案,可伸缩性高且经济高效。 它将高性能文件系统的强大功能与大规模和经济效益相结合,帮助你缩短获取洞察所需的时间。 Data Lake Storage Gen2 扩展了 Azure Blob 存储功能,并针对分析工作负载进行了优化。
Azure 数据资源管理器与 Azure Blob 存储和 Azure Data Lake Storage(Gen1 和 Gen2)集成,提供对存储在外部存储中的数据的快速、缓存和索引访问。 无需先将数据引入 Azure 数据资源管理器即可分析和查询数据。 还可以同时对引入的和未引入的外部数据进行查询。 有关详细信息,请参阅如何使用 Azure 数据资源管理器 Web UI 向导创建外部表。 有关简要概述,请参阅外部表。
提示
若要获得最佳查询性能,必须将数据引入 Azure 数据资源管理器中。 在不预先引入数据的情况下查询外部数据的功能只应当用于历史数据或极少会查询的数据。 请优化外部数据查询性能以获得最佳结果。
创建外部表
假设你有许多 CSV 文件,其中包含仓库中存储的产品的历史信息,并且你想要进行快速分析来查找去年最流行的五种产品。 在此示例中,CSV 文件如下所示:
| 时间戳 | ProductId | 产品描述 |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | 3.5in DS/HD 软盘 |
| 2019-01-01 11:30:55 | YDX1 | Yamaha DX1 合成器 |
| ... | ... | ... |
文件存储在 Azure Blob 存储 mycompanystorage 中名为 archivedproducts 的容器中,按日期分区:
https://mycompanystorage.blob.core.chinacloudapi.cn/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.chinacloudapi.cn/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.chinacloudapi.cn/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.chinacloudapi.cn/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.chinacloudapi.cn/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
若要直接对这些 CSV 文件运行 KQL 查询,请使用 .create external table 命令在 Azure 数据资源管理器中定义一个外部表。 有关外部表创建命令选项的详细信息,请参阅外部表命令。
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.chinacloudapi.cn/archivedproducts;StorageSecretKey'
)
外部表现已在 Azure 数据资源管理器 Web UI 左窗格中可见:
外部表权限
查看下表权限:
- 数据库用户可以创建外部表。 表创建者自动成为表管理员。
- 群集、数据库或表管理员可以编辑现有表。
- 任何数据库用户或读取者都可以查询外部表。
查询外部表
定义外部表后,可以使用 external_table() 函数引用它。 查询的其余部分是标准的 Kusto 查询语言。
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
同时查询外部数据和已引入的数据
可以在同一查询中同时查询外部表和引入的数据表。 可以将外部表与来自 Azure 数据管理器、SQL Server 或其他源的其他数据进行 join 或 union。 请使用 let( ) statement 为外部表引用分配速记名称。
在下面的示例中, Products 是引入的数据表, ArchivedProducts 是我们定义的外部表:
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
查询分层数据格式
Azure 数据资源管理器允许查询分层格式,例如 JSON、Parquet、Avro 和 ORC。 若要将分层数据架构映射到外部表架构(如果它是不同的架构),请使用外部表映射命令。 例如,如果要查询采用以下格式的 JSON 日志文件:
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "aaaabbbb-0000-cccc-1111-dddd2222eeee",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "bbbbcccc-1111-dddd-2222-eeee3333ffff",
"method": "GetFileList"
}
}
...
外部表定义如下所示:
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.chinacloudapi.cn/container1;StorageSecretKey'
)
定义将数据字段映射到外部表定义字段的 JSON 映射:
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
查询外部表时,首先会调用映射,然后检索映射到外部表列的相关数据。
external_table('ApiCalls') | take 10
有关映射语法的详细信息,请参阅数据映射。
查询 help 群集中的 TaxiRides 外部表
使用名为 help 的测试群集来尝试不同的 Azure 数据资源管理器功能。 help 群集包含纽约市出租车数据集(其中包含数十亿条出租车搭乘记录)的外部表定义。
创建外部表 TaxiRides
本部分显示了用于在 help 群集中创建 TaxiRides 外部表的查询。 由于已创建此表,因此可以跳过本部分并直接 查询 TaxiRides 外部表数据。
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.chinacloudapi.cn/container1;secretKey'
)
可以通过查看 Azure 数据资源管理器 Web UI 的左窗格找到创建的 TaxiRides 表。
查询 TaxiRides 外部表数据
登录 https://dataexplorer.azure.cn/clusters/help.chinaeast2/databases/Samples 。
在不分区的情况下查询 TaxiRides 外部表
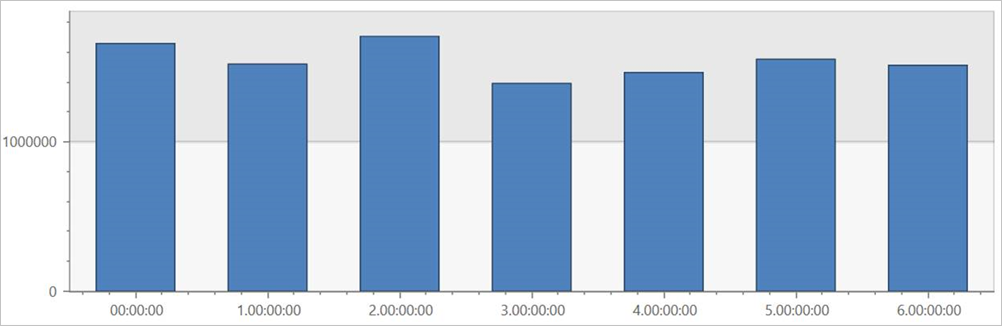
在外部表 TaxiRides 上运行此查询,以显示数据集中每周不同日期的搭乘记录。
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
此查询显示一周中最忙碌的一天。 由于数据未分区,因此查询可能需要好几分钟的时间才能返回结果。
使用分区查询 TaxiRides 外部表
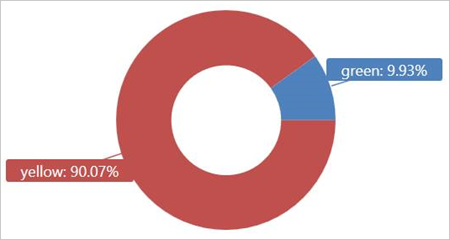
在外部表 TaxiRides 上运行此查询以显示 2017 年 1 月使用的出租车类型(黄色或绿色) 。
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
此查询使用分区,这样可以优化查询时间和性能。 此查询基于分区的列 (pickup_datetime) 进行筛选,在数秒钟内返回结果。
你可以编写针对外部表 TaxiRides 运行的其他查询,了解有关数据的更多信息。
优化查询性能
可以使用下述用于查询外部数据的最佳做法,优化数据湖中的查询性能。
数据格式
- 请为分析查询使用纵栏格式,原因如下:
- 只能读取与查询相关的列。
- 列编码技术可显著减少数据大小。
- Azure 数据资源管理器支持 Parquet 和 ORC 纵栏格式。 建议采用 Parquet 格式,因为它优化了实现。
Azure 区域
检查外部数据是否与 Azure 数据资源管理器群集位于同一 Azure 区域中。 此设置可降低成本并缩短数据提取时间。
文件大小
最佳文件大小为每个文件数百 Mb(最高可达 1 GB)。 请避免使用多个需要不必要开销的小文件,例如速度较慢的文件枚举过程,以及对纵栏格式进行有限的使用。 文件数应大于 Azure 数据资源管理器群集中的 CPU 核心数。
压缩
使用压缩可以减少从远程存储提取的数据量。 对于 Parquet 格式,请使用内部 Parquet 压缩机制来单独压缩列组,这样就可以单独读取列组。 若要验证压缩机制的使用情况,请检查文件的命名方式是否如下所示: <filename>.gz.parquet 或 <filename>.snappy.parquet,而不是 <filename>.parquet.gz。
分区
使用“文件夹”分区组织你的数据,此类分区允许查询跳过无关的路径。 在规划分区时,请考虑查询中的文件大小和常见筛选器,例如时间戳或租户 ID。
VM 大小
请选择核心数较多且网络吞吐量较高的 VM SKU(内存不太重要)。 有关详细信息,请参阅为 Azure 数据资源管理器群集选择正确的 VM SKU。