适用于根本原因分析的异常诊断
Kusto 查询语言 (KQL) 具有内置的异常情况检测和预测函数,用于检查是否存在异常行为。 一旦检测到此模式,可运行根本原因分析 (RCA) 来缓解或解决异常情况。
诊断过程比较复杂且冗长,需由领域专家完成。 此过程包括:
- 从同一时间段内不同的源中提取和连接其他数据
- 在多个维度上查找值分布的变化
- 绘制更多变量的图表
- 其他基于域知识和直觉的技术
由于这些诊断方案很常用,其中提供了机器学习插件来简化诊断过程及缩短 RCA 的持续时间。
以下三个机器学习插件都实现聚类分析算法:autocluster、basket 和 diffpatterns。 autocluster 和 basket 插件聚类单个记录集,diffpatterns 插件聚类两个记录集之间的差异。
聚类单个记录集
常见的场景包括按特定条件选择的数据集,例如:
- 存在异常行为的时间范围
- 读取高温设备数据
- 长时间的命令
- 主要消费用户 你需要一种快速而简单的方法来发现数据中隐藏的惯常模式(段)。 模式是其记录在多个维度(分类列)上共用相同值的数据集的子集。
以下查询以 10 分钟箱为单位生成并显示一周内的服务时序异常:
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m
| render timechart with(title="Service exceptions over a week, 10 minutes resolution")
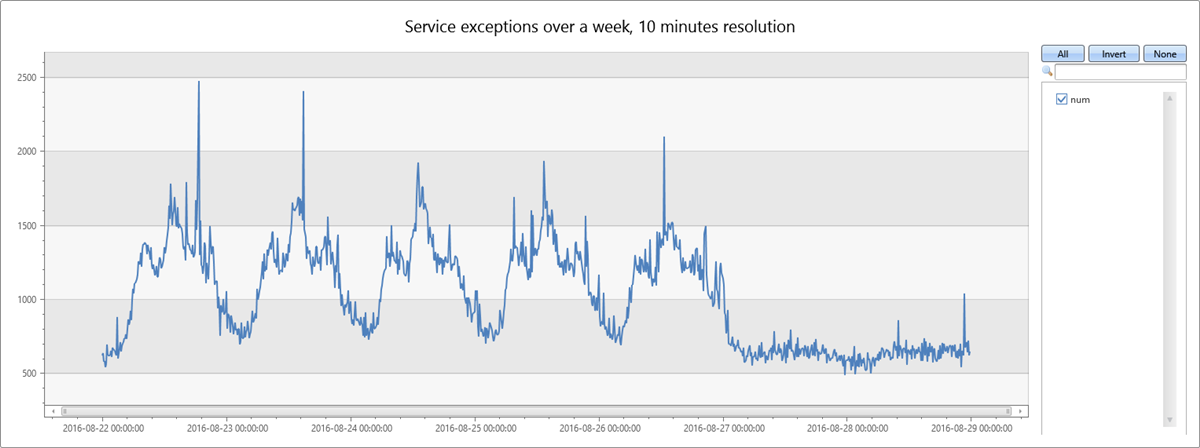
服务异常计数与服务总流量相关联。 你可以清楚地看到工作日(周一到周五)的每日模式。 一天的中间时段,服务异常的数量会增加,在晚上会下降。 在周末,计数平稳地保持较低水平。 可以使用时序异常情况检测来检测异常高峰。
数据中的第二个高峰发生在星期二下午。 下面的查询用于进一步诊断和验证它是否是尖峰。 该查询以更高的分辨率(8 小时时段,以分钟为单位)围绕峰值重新绘制了图表。然后你可以研究它的边界。
let min_t=datetime(2016-08-23 11:00);
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to min_t+8h step 1m
| render timechart with(title="Zoom on the 2nd spike, 1 minute resolution")
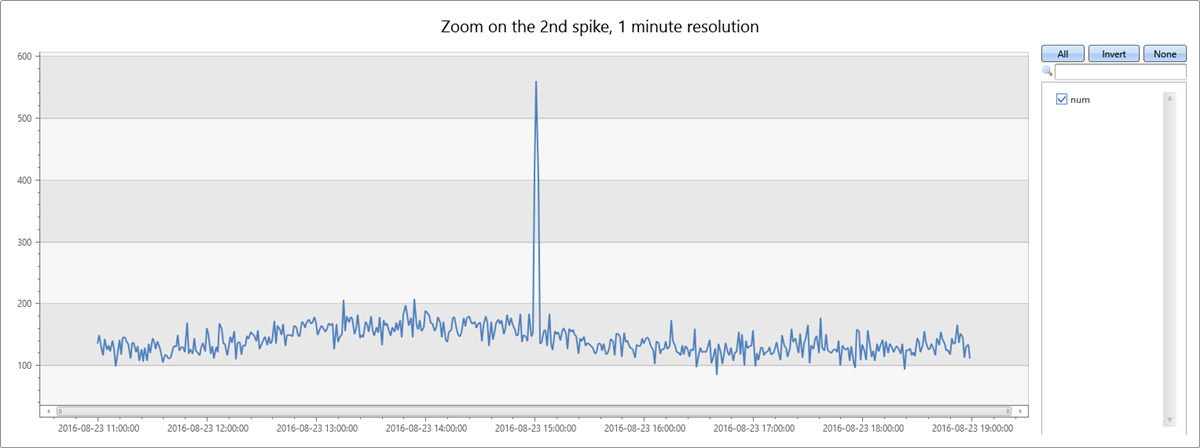
你会看到 从 15:00 到 15:02 出现了较窄的两分钟高峰。 以下查询统计了此两分钟时段内的异常数:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| count
| 计数 |
|---|
| 972 |
以下查询从 972 个异常中采样 20 个异常:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| take 20
| PreciseTimeStamp | 区域 | 缩放单元 | 部署 ID | 跟踪点 | 服务主机 |
|---|---|---|---|---|---|
| 2016-08-23 15:00:08.7302460 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:09.9496584 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 8d257da1-7a1c-44f5-9acd-f9e02ff507fd |
| 2016-08-23 15:00:10.5911748 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:12.2957912 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | f855fcef-ebfe-405d-aaf8-9c5e2e43d862 |
| 2016-08-23 15:00:18.5955357 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 9d390e07-417d-42eb-bebd-793965189a28 |
| 2016-08-23 15:00:20.7444854 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 6e54c1c8-42d3-4e4e-8b79-9bb076ca71f1 |
| 2016-08-23 15:00:23.8694999 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 36109 | 19422243-19b9-4d85-9ca6-bc961861d287 |
| 2016-08-23 15:00:26.4271786 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 36109 | 3271bae4-1c5b-4f73-98ef-cc117e9be914 |
| 2016-08-23 15:00:27.8958124 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 904498 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:32.9884969 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007007 | d5c7c825-9d46-4ab7-a0c1-8e2ac1d83ddb |
| 2016-08-23 15:00:34.5061623 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:37.4490273 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | f2ee8254-173c-477d-a1de-4902150ea50d |
| 2016-08-23 15:00:41.2431223 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 103200 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:47.2983975 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 423690590 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:50.5932834 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 2a41b552-aa19-4987-8cdd-410a3af016ac |
| 2016-08-23 15:00:50.8259021 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 0d56b8e3-470d-4213-91da-97405f8d005e |
| 2016-08-23 15:00:53.2490731 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 36109 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:57.0000946 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 64038 | cb55739e-4afe-46a3-970f-1b49d8ee7564 |
| 2016-08-23 15:00:58.2222707 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | 8215dcf6-2de0-42bd-9c90-181c70486c9c |
| 2016-08-23 15:00:59.9382620 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | 451e3c4c-0808-4566-a64d-84d85cf30978 |
使用 autocluster() 聚类单个记录集
即使异常数不到 1000 个,也仍很难发现常见段,因为每个列中包含多个值。 可以使用 autocluster() 插件即时提取常见段的简短列表,并在高峰的两分钟时段内找出相关的聚类,如以下查询所示:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate autocluster()
| 段 ID | 计数 | 百分比 | 区域 | 缩放单元 | 部署 ID | 服务主机 |
|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 1 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | |
| 2 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 3 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | |
| 4 | 55 | 5.65843621399177 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc |
在上面的结果中可以看到,最具主导性的段包含异常记录总数中的 65.74%,并共享四个维度。 下一个段中异常出现的频率要低得多。 仅包含记录数的 9.67%,并共享三个维度。 其他段的常见性更低。
autocluster 使用专属算法来挖掘多个维度并提取相关的段。 “相关”是指每个段明显覆盖了记录集和特征集。 段也有分歧,这意味着,每个段与其他段不同。 其中一个或多个段可能与 RCA 过程相关。 为了尽量减少段的审查和评估,autocluster 只会提取精简的段列表。
使用 basket() 聚类单个记录集
也可以按以下查询中所示使用 basket() 插件:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate basket()
| 段 ID | 计数 | 百分比 | 区域 | 缩放单元 | 部署 ID | 跟踪点 | 服务主机 |
|---|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec | |
| 1 | 642 | 66.0493827160494 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | ||
| 2 | 324 | 33.3333333333333 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 0 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 3 | 315 | 32.4074074074074 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 16108 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 4 | 328 | 33.7448559670782 | 0 | ||||
| 5 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | ||
| 6 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | ||
| 7 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | ||
| 8 | 167 | 17.1810699588477 | scus | ||||
| 9 | 55 | 5.65843621399177 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | ||
| 10 | 92 | 9.46502057613169 | 10007007 | ||||
| 11 | 90 | 9.25925925925926 | 10007006 | ||||
| 12 | 57 | 5.8641975308642 | 00000000-0000-0000-0000-000000000000 |
Basket 实现了用于项集挖掘的“Apriori”算法。 它提取记录集覆盖率高于阈值(默认为 5%)的所有段。 可以看到,已提取多个相似的段(例如段 0、1 或 2、3)。
这两个插件功能都很强大且易于使用。 它们的局限性在于,它们以无监督的方式聚集单个记录集,不带任何标签。 不清楚提取的模式特征化的是所选记录集(异常记录)还是全局记录集。
聚类两个记录集之间的差异
diffpatterns() 插件克服了 autocluster 和 basket 的限制。 Diffpatterns 采用两个记录集,并提取不同的主段。 一个集通常包含正在调查的异常记录集。 一个集由 autocluster 和 basket 进行分析。 另一个集包含参考记录集,即基线。
在以下查询中,diffpatterns 查找高峰的两分钟时段内的相关聚类,这不同于基线中的聚类。 我们将基线时间范围定义为 15:00 之前的 8 分钟(开始出现高峰的时间)。 可以按二元列 (AB) 进行扩展,并指定特定的记录是属于基线还是异常集。 Diffpatterns 实现监督式学习算法,其中,会按异常标志与基线标志 (AB) 生成两个类标签。
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
let min_baseline_t=datetime(2016-08-23 14:50);
let max_baseline_t=datetime(2016-08-23 14:58); // Leave a gap between the baseline and the spike to avoid the transition zone.
let splitime=(max_baseline_t+min_peak_t)/2.0;
demo_clustering1
| where (PreciseTimeStamp between(min_baseline_t..max_baseline_t)) or
(PreciseTimeStamp between(min_peak_t..max_peak_t))
| extend AB=iff(PreciseTimeStamp > splitime, 'Anomaly', 'Baseline')
| evaluate diffpatterns(AB, 'Anomaly', 'Baseline')
| 段 ID | 计数 A | 计数 B | 百分比 A | 百分比 B | PercentDiffAB | 区域 | 缩放单元 | 部署 ID | 跟踪点 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 639 | 21 | 65.74 | 1.7 | 64.04 | eau | su7 | b5d1d4df547d4a04ac15885617edba57 | |
| 1 | 167 | 544 | 17.18 | 44.16 | 26.97 | scus | |||
| 2 | 92 | 356 | 9.47 | 28.9 | 19.43 | 10007007 | |||
| 3 | 90 | 336 | 9.26 | 27.27 | 18.01 | 10007006 | |||
| 4 | 82 | 318 | 8.44 | 25.81 | 17.38 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 5 | 55 | 252 | 5.66 | 20.45 | 14.8 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | |
| 6 | 57 | 204 | 5.86 | 16.56 | 10.69 |
最具主导性的段是由 autocluster 提取的片段。 它在两分钟异常时段内的覆盖率也为 65.74%。 但是,它在八分钟基线时段内的覆盖率仅为 1.7%。 两者相差 64.04%。 这种差异看起来与异常高峰相关。 为了验证此假设,以下查询将原始图表拆分为属于此问题段的记录和其他段中的记录。
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| extend seg = iff(Region == "eau" and ScaleUnit == "su7" and DeploymentId == "b5d1d4df547d4a04ac15885617edba57"
and ServiceHost == "e7f60c5d-4944-42b3-922a-92e98a8e7dec", "Problem", "Normal")
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m by seg
| render timechart
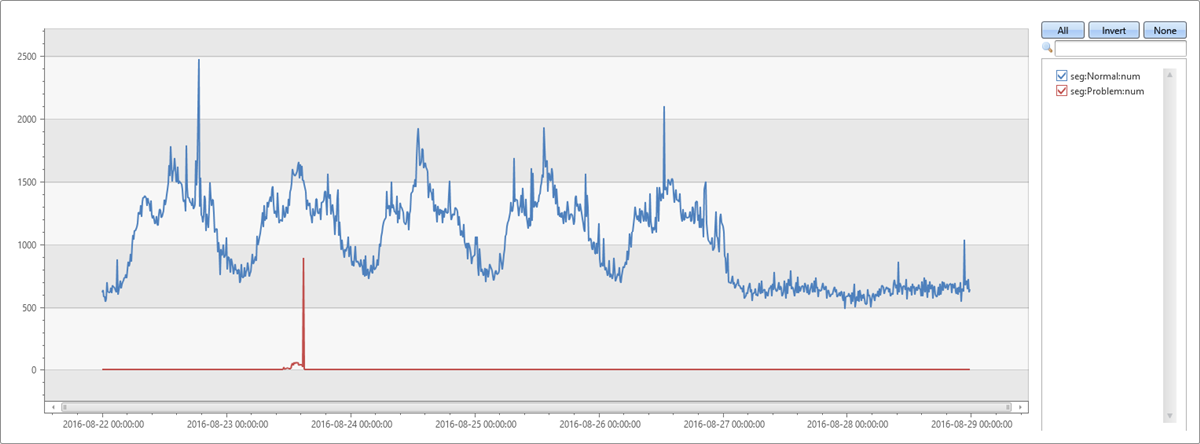
在此图表中可以看出,星期二下午出现高峰的原因是,此特定段中发生了 diffpatterns 插件发现的异常。
摘要
机器学习插件在很多方案中可以发挥作用。 autocluster 和 basket 实现非监督式学习算法,且易于使用。 Diffpatterns 实现监督式学习算法,尽管它更复杂,但在提取 RCA 的差异段时功能更强大。
在临时方案以及自动化的近实时监视服务中可以交互方式使用这些插件。 在时间序列异常检测之后会执行一个诊断过程。 此过程经过高度优化,可满足必要的性能标准。