Azure 数据资源管理器(ADX)是一个完全托管的分析平台,用于实时分析大规模遥测和日志数据。 本文介绍如何在 Azure 数据资源管理器中计算每 GB 引入的成本、驱动因素以及如何优化群集以提高效率。 大数据分析平台使用不同的定价模型。 许多平台基于查询量、数据引入、存储持续时间和计算资源等因素进行定价。 这种复杂性使得很难比较产品之间的定价。
为了帮助了解使用 Azure 数据资源管理器的成本,本文采用指标 每 GB 摄取的成本。 此指标是 群集总成本 (计算、存储、网络和服务标记)除以在此期间 引入的原始大小数据总数 。
2025 年 6 月 ADX 群集的代表快照用于建立示例分析。 以下部分显示了 分析的主要结果、解释 哪些驱动 成本变化,以及用户如何 优化引入的每 GB 成本 ,而不会影响性能。
注释
- 本文中的所有成本数字都显示了列表价格,不包括折扣或基于承诺的节省。
- 为了进行此示例分析,每个 GB 的成本以 样本成本单位(SCU)表示,其中每个 SCU 表示一个通用成本单位,例如一美分。
每 GB 引入成本分析
下图显示了每个成本组中原始大小(Y 轴)中的每日引入 GB 的中位数与每 GB 引入成本的中位数(X 轴)。 气泡大小代表该组在引入到服务的总数据中的份额。
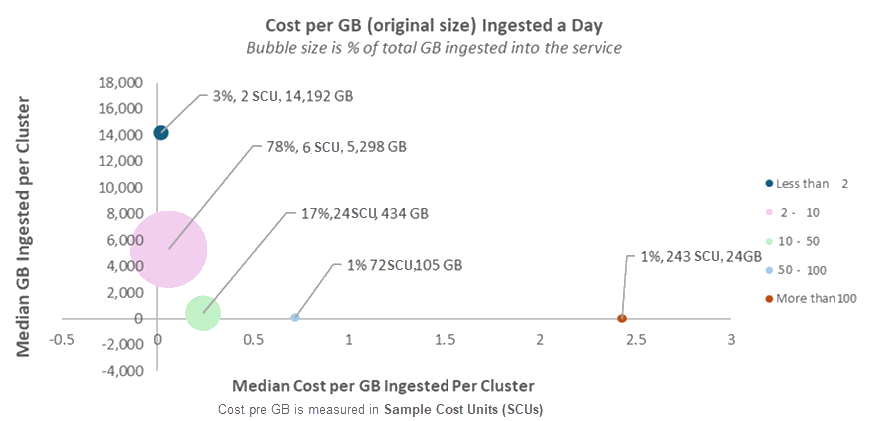
每 GB 摄入成本因群集而异,但有几个模式十分显著:
大多数数据 (>75%)的引入成本在每 GB 2 到 10 个 SCU(折扣前)。
少于 5% 的数据的引入成本为每 GB 少于 2 个 SCU。
即使在相同的使用类别(或“气泡”)中,你也会看到显著变化。 例如,在最大的气泡中,一个群集以每 GB 2 个 SCU 引入,而另一个群集则达到每个 GB 10 个 SCU。 这是5倍的差异。 后续部分介绍此变体的主要原因。
每 GB 成本较高的群集较为罕见,且通常数据引入量较低。 通常,较小的数据量意味着每 GB 的成本更高。
重要
气泡图显示,每 GB 引入成本因群集而异。 此变体并不表示良好或不良的做法。 它反映了服务的不同方案、配置和使用模式。
例如,一个群集可能会保留更长的数据,以符合性,这会增加存储成本。 另一种更新策略可能会在引入期间处理数据,从而增加计算资源使用。 这些方案是有意的设计选择,符合特定目标,它们自然会影响每 GB 的成本。
影响每 GB 引入成本的因素有哪些
这些关键因素导致每个群集中每 GB 摄取的成本差异:
存储持续时间:存储数据的时间越长,成本就越高。 请参阅 保留策略。
高 CPU 使用率:作(如大量查询、数据处理或转换)会导致 CPU 使用率较高。
缓存设置:缓存更多数据可提升性能,但可能会增加成本。 请参阅 缓存策略。
冷数据使用情况:访问冷数据的查询会触发读取事务并增加成本。 查看 热缓存和冷缓存。
数据转换和优化:更新策略、具体化视图和分区等功能消耗 CPU 资源,并可能降低成本。 请参阅 更新策略、 具体化视图和 分区。
摄取量:群集在更高的摄取量下更具成本效益地运行。
架构设计:包含许多列的宽表需要更多的计算和存储资源,这会增加成本。
高级功能:关注者、专用终结点和 Python 沙盒等选项消耗更多资源,并可以增加成本。
自动缩放:没有自动缩放的群集通常成本更高,因为它们不会按需调整其大小。
你可以配置其中大多数因素来优化性能和成本。
深入了解关键成本驱动因素
本部分探讨影响 Azure 数据资源管理器中引入的每 GB 成本的关键因素,提供有关如何管理和优化这些成本的见解。
数据保留对成本的影响
在 ADX 中,所有引入的数据都存储在永久性存储中。 每个表和具体化视图都有一个 保留策略 ,用于定义数据的保留时间。 数据保留的时间越长,成本越高,根据 Azure 存储定价。 当您需要长期存储(例如为了合规性)时,每 GB 存储的成本会上升,因为它包括持续的存储费用。
除了群集报告的盘区大小外,还有两个额外的成本驱动因素:
- 保留缓冲区:默认存储额外的 7 天数据,以防止意外数据丢失。
- 可恢复性开销:对于启用了 可恢复性设置 的表(默认值),数据将保留 14 天。 这包括在合并和重新生成作期间生成的中间 Blob。
群集大小
群集大小是群集中的计算机数(节点)。 每台计算机都会增加成本,具体取决于其类型(SKU)。 自动缩放 根据 CPU 使用率调整群集大小,因此系统可以通过避免空闲或冗余资源来优化成本和性能。
自动缩放可调整群集大小,以确保缓存的数据适合可用 SSD 空间。 因此,大型缓存可能会增加群集大小,如果 CPU 使用率较低,这可能会导致每个 GB 的成本更高。 有关优化缓存大小的详细信息,请参阅 “缓存”选项卡群集见解工具 。
运行许多查询或执行 CPU 密集型任务的群集(例如具体化视图、更新策略或分区)可以缩放群集,从而增加每 GB 的成本。 请注意,这些功能可以显著提高查询性能并减少查询 CPU 使用率,从而提高整体效率。
引入的数据量
随着群集的增长,将添加更多节点,增加总成本。 该成本分布在所有引入的数据中,因此引入的数据越多,每 GB 的成本就越低。
冷数据使用情况
当查询经常访问存储在磁盘上的冷数据时,它们会导致读取事务使用更多资源,并会增加整体群集成本。
流式处理与排队引入
每个引入方法具有不同的成本、延迟和功能特征,因此每个引入方法都更适合不同的方案。 出于成本考虑,流式引入 在引入包含缓慢流动的数据的小型表时更便宜,而 排队引入 对于大型表而言更具成本效益。
小窍门
优化每 GB 摄取的成本
检查 关键成本驱动因素 的配置,以确保它们符合群集的需求和服务要求,以提高效率。 特别是:
- 最大程度地减少对冷数据的查询,以减少读取事务。
- 启用自动缩放以动态匹配群集大小以满足需求。