适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
完成数据流的生成和调试之后,需要在管道上下文中将数据流安排为按计划执行。 可以使用触发器来调控管道。 要测试和调试管道中的数据流,可以使用工具栏功能区上的“调试”按钮或管道生成器中的“立即触发”选项来执行单次运行,以测试管道上下文中的数据流。
执行管道时,可以监视管道以及其中包含的所有活动,包括数据流活动。 在左侧 UI 面板中选择监视图标。 可以看到类似如下所示的屏幕。 突出显示的图标可用于深入查看管道中的活动,包括数据流活动。
屏幕截图显示了用于选择管道选项以获取详细信息的图标。
还可以看到此级别的统计信息,包括运行次数和状态。 活动级别的运行 ID 不同于管道级别的运行 ID。 上一级别的运行 ID 适用于管道。 选择眼镜图标可以查看有关数据流执行的深入详细信息。

在图形节点监视视图中,可以看到数据流图形的简化只读版本。 若要查看包含转换阶段标签的较大图形节点的详细信息视图,请使用画布右侧的缩放滑块。 还可使用右侧的搜索按钮在图中查找部分数据流逻辑。
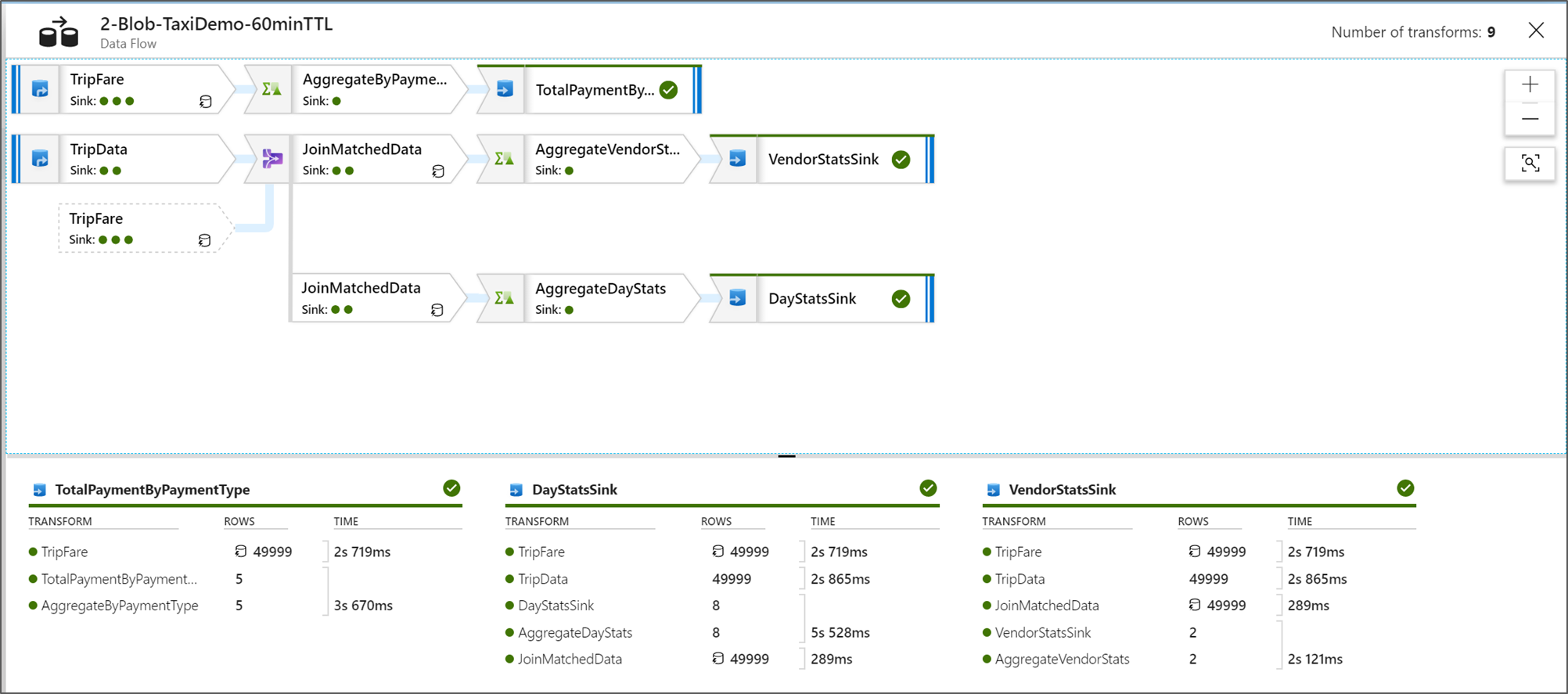
查看数据流执行计划
在 Spark 中执行数据流时,服务会根据整个数据流来确定最佳的代码路径。 此外,执行路径可能出现在不同的横向扩展节点和数据分区上。 因此,监视图形表示流的设计,它考虑到了转换的执行路径。 选择单个节点时,可以看到表示在群集上一起执行过的代码的“阶段”。 你看到的计时和计数表示这些组或阶段,而不是设计中的单个步骤。
在监视窗口中选择可选区域时,底部窗格中的统计信息会显示每个接收器的计时和行数,以及生成接收器数据的转换链路。
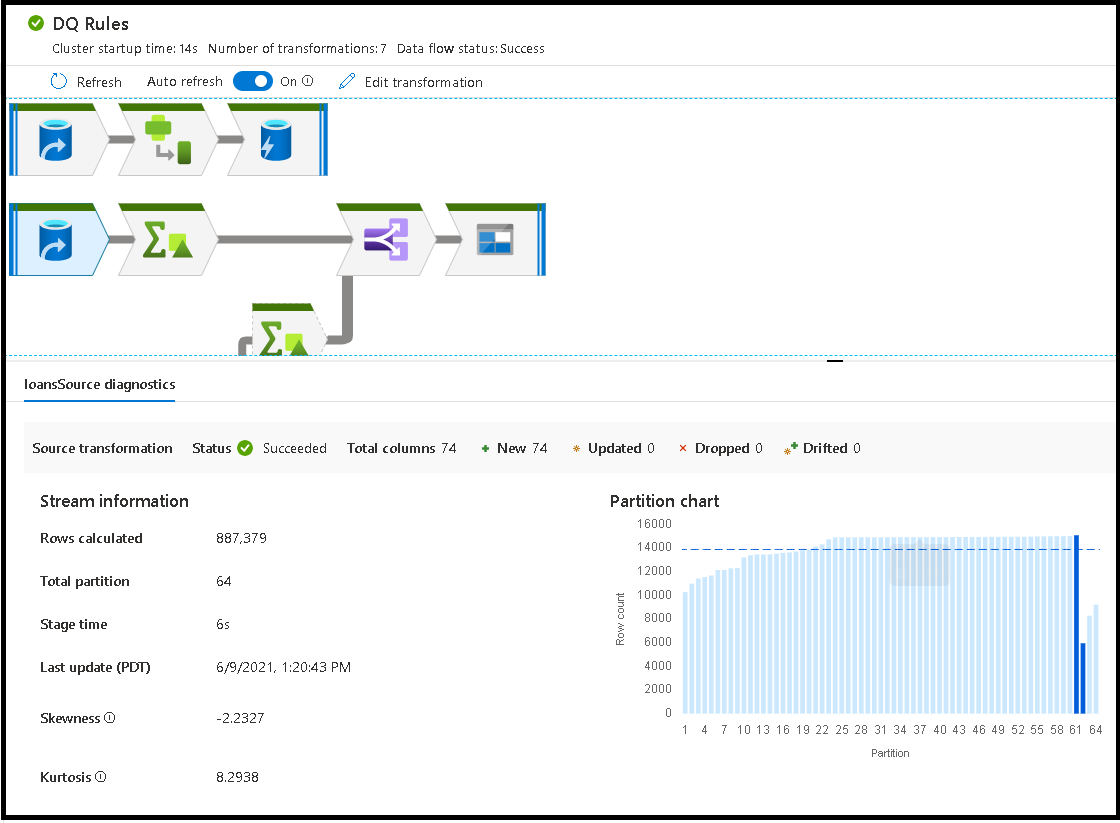
选择单个转换时,可以在右侧面板中看到额外的反馈信息,这包括分区统计、列计数、偏斜度(即数据在分区中的分布均匀性)以及峰度(即数据的尖峰特性)。
按处理时间排序有助于确定数据流中的哪些阶段所花时间最多。
若要找出每个阶段中的哪些转换所花时间最多,请按最长处理时间进行排序。
也可对写入的*行排序,以确定数据流中的哪些流写入的数据最多。
在节点视图中选择“接收器”时,可以看到列沿袭。 在数据流的整个过程中,有三种不同的方法用于汇总列并将其落入接收器。 它们分别是:
- 计算列:在数据流中使用该列进行条件处理或表达式内使用,但不将其写入 Sink
- 派生:这个列是在你的流中生成的新列,它不存在于源中。
- 映射:该列来源于源头,并且你需要将它映射到目标字段
- 数据流状态:执行的当前状态
- 群集启动时间:为数据流执行获取 JIT Spark 计算环境所需的时间量
- 转换次数:在流中执行的转换步骤数

总接收器处理时间与转换处理时间
每个转换阶段都包括在每个分区执行时间汇总后完成该阶段的总时间。 选择 Sink 时,您将看到“Sink 处理时间”。 此时间包括转换时间总计加上将数据写入目标存储所花费的 I/O 时间。 接收器处理时间与转换过程总时间之间的差异是用于写入数据的 I/O 时间。
如果在管道监视视图中打开数据流活动的 JSON 输出,则还可以查看每个分区转换步骤的详细计时。 JSON 包含每个分区的毫秒计时,而 UX 监视视图是添加在一起的分区的聚合计时:
{
"stage": 4,
"partitionTimes": [
14353,
14914,
14246,
14912,
...
]
}
汇聚处理时间
当你在映射中选择接收器转换图标时,右侧滑动面板的底部会显示一个额外的数据点,名为“后处理时间”。 这是加载、转换和写入数据后在 Spark 群集上执行作业所花费的时间。 此时间可能包括关闭连接池、驱动程序关闭、删除文件、合并文件等。当你在流中执行诸如“移动文件”和“输出到单个文件”之类的操作时,可能会看到后期处理时间值的增加。
- 写入阶段持续时间:将数据写入 Synapse SQL 暂存位置所用的时间
- 表操作 SQL 持续时间:将数据从临时表移动到目标表所花费的时间
- 前 SQL 持续时间和后 SQL 持续时间:运行前/后 SQL 命令所花费的时间
- 前命令持续时间和后命令持续时间:针对基于文件的源/接收器运行任何前/后操作所花费的时间。 例如,在处理后移动或删除文件。
- 合并持续时间:用于合并文件的时间。当写入单个文件或使用“文件名作为列数据”时,合并文件在基于文件的存储中使用。 如果在此指标中花费了大量时间,则应避免使用这些选项。
- 阶段时间:在 Spark 内部完成阶段操作所用的总时间。
- 临时暂存稳定表:数据流在数据库中用于暂存数据的临时表名称。
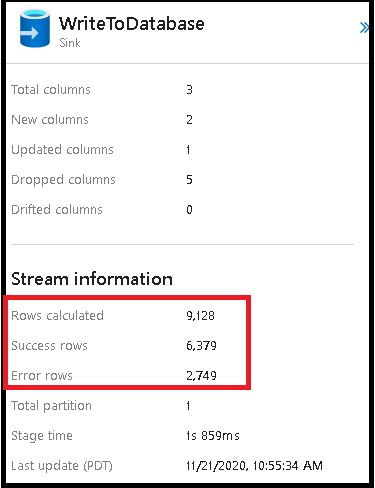
错误行
在数据流接收器中启用错误行处理将反映在监视输出中。 将接收器设置为“出错时报告成功”时,如果选择接收器监视节点,监视输出将显示成功和失败行数。
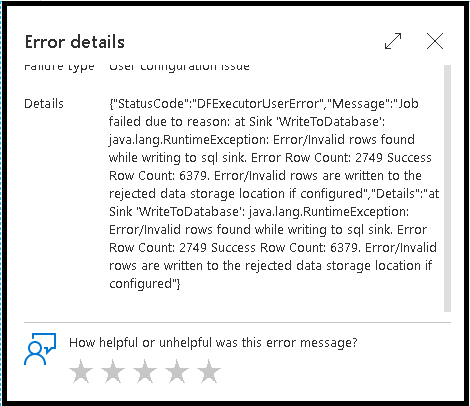
选择“出错时报告失败”时,相同的输出将仅显示在活动监视输出文本中。 这是因为数据流活动在执行过程中返回失败,并且详细监控视图不可用。
显示器图标
此图标表示转换数据已在群集中缓存,因此计时和执行路径已考虑到这种情况:
在转换中还会看到绿色的圆圈图标。 它们代表数据流入的汇入点的数量。