当数据流写入接收器时,任何自定义分区都会在写入之前立即发生。 与源一样,在大多数情况下,建议保留 “使用当前分区 ”作为所选分区选项。 已分区数据写入的速度比未分区的数据要快得多,即使目标未分区也是如此。 以下是各种接收器类型的单独注意事项。
Azure SQL Database接收器
使用Azure SQL Database时,默认分区在大多数情况下应正常工作。 你的数据接收端可能由于分区过多,导致 SQL 数据库无法处理。 如果遇到这种情况,请减少 SQL 数据库接收器输出的分区数。
错误行处理对性能的影响
在汇聚转换中启用错误行处理(“出错时继续”)时,服务会在将兼容的行写入目标表之前执行额外的步骤。 此额外步骤会导致大约 5% 的性能损失,如果选择将不兼容的行写入日志文件,还会有额外的小性能影响。
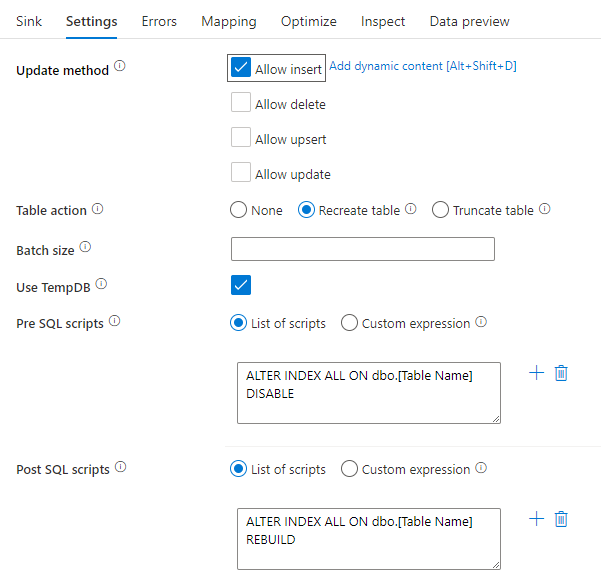
使用 SQL 脚本禁用索引
在 SQL 数据库中加载之前禁用索引可以大大提高写入表的性能。 在写入 SQL 接收器之前,请运行以下命令。
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
写入完成后,使用以下命令重新生成索引:
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
可以在映射数据流中使用 Azure SQL Database 或 Synapse 汇聚中的 Pre-SQL 和 Post-SQL 脚本本地完成此操作。
警告
禁用索引时,数据流实际上控制了数据库,此时查询不太可能成功。 因此,许多 ETL 作业在午夜触发,以避免这种冲突。 有关详细信息,请了解 禁用 SQL 索引的约束
扩大数据库
在运行管道之前,计划调整源和接收器的 Azure SQL 数据库和数据仓库的规模,以增加吞吐量,并在达到 DTU 限制后将 Azure 的限制降到最低。 管道执行完成后,将数据库调整回其正常运行速率。
Azure Synapse Analytics接收器
写入Azure Synapse Analytics时,请确保启用暂存设置为 true。 这使服务能够使用 SQL COPY 命令 进行写入,该命令可有效地批量加载数据。 在使用暂存时,需要引用 Azure Data Lake Storage gen2 或 Azure Blob Storage 帐户来暂存数据。
除了暂存之外,适用于 Azure SQL 数据库的同样最佳实践也适用于 Azure Synapse Analytics。
文件为基础的输出
虽然数据流支持各种文件类型,但建议使用 Spark 原生 Parquet 格式,以获得最佳读取和写入时间。
如果数据均匀分布, 则使用当前分区 是写入文件的最快分区选项。
文件名选项
编写文件时,可以选择对性能产生影响的命名选项。
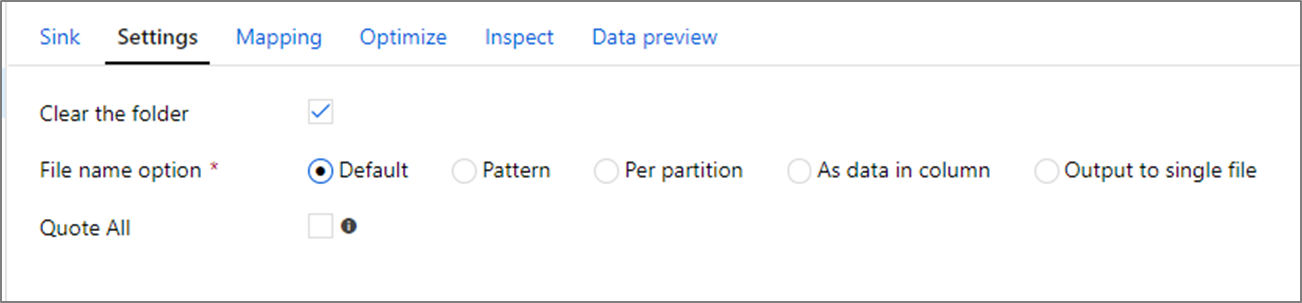
选择 “默认” 选项可实现最快的写入速度。 每个分区等同于具有 Spark 默认名称的文件。 如果只是从数据文件夹读取数据,这非常有用。
设置命名 模式 会将每个分区文件重命名为更易用的名称。 此操作在写入后发生,比选择默认值慢一些。
每个分区 允许您为每个分区手动命名。
如果列对应于要如何输出数据,则可以选择 “名称文件”作为列数据。 这会重新调整数据,如果列未均匀分布,则可能会影响性能。
如果某列与您希望生成文件夹名称的方式相对应,请选择将文件夹命名为列数据。
输出到单个文件 会将所有数据合并到单个分区中。 这会导致长时间的写入时间,尤其是对于大型数据集。 除非有明确的业务理由使用它,否则不建议使用此选项。
Azure Cosmos DB接收器
写入Azure Cosmos DB时,更改数据流执行期间的吞吐量和批大小可以提高性能。 这些更改仅在数据流活动运行期间生效,并在结束后返回到原始集合设置。
批大小: 通常,从默认批大小开始就足够了。 若要进一步优化此值,请计算数据的粗略对象大小,并确保对象大小 * 批大小小于 2MB。 如果是,可以增加批大小以获得更好的吞吐量。
Throughput:在此处设置更高的吞吐量设置,使文档能够更快地写入Azure Cosmos DB。 请记住,基于高吞吐量设置会导致较高的 RU 成本。
写入吞吐量预算: 使用小于每分钟 RU 总数的值。 如果有具有大量 Spark 分区的数据流,则设置预算吞吐量允许在这些分区之间实现更大的平衡。
相关内容
请参阅与性能相关的其他Data Flow文章: