适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
如果你要复制巨量的对象(例如数千个表)或者要从大量不同的源中加载数据,适当的方法是在一个控制表中输入包含所需复制行为的对象的名称列表,然后使用参数化管道从该控制表中读取这些对象,并相应地将其应用于作业。 这样,只需更新控制表中的对象名称就能轻松维护(例如添加/删除)要复制的对象列表,而无需重新部署管道。 此外,还可以在单个位置轻松检查定义了复制行为的哪些管道/触发器复制了哪些对象。
ADF 中的复制数据工具简化了这种元数据驱动的数据复制管道的生成过程。 通过基于向导的体验完成直观的流程后,该工具可为你生成参数化管道和 SQL 脚本,以便你相应地创建外部控制表。 运行生成的脚本在 SQL 数据库中创建控制表后,管道将读取控制表中的元数据,并自动将其应用于复制作业。
通过复制数据工具创建元数据驱动的复制作业
在复制数据工具中选择“元数据驱动的复制任务”。
需要输入您的控制表的连接信息和表名称,以便生成的管道从该控制表中读取元数据。
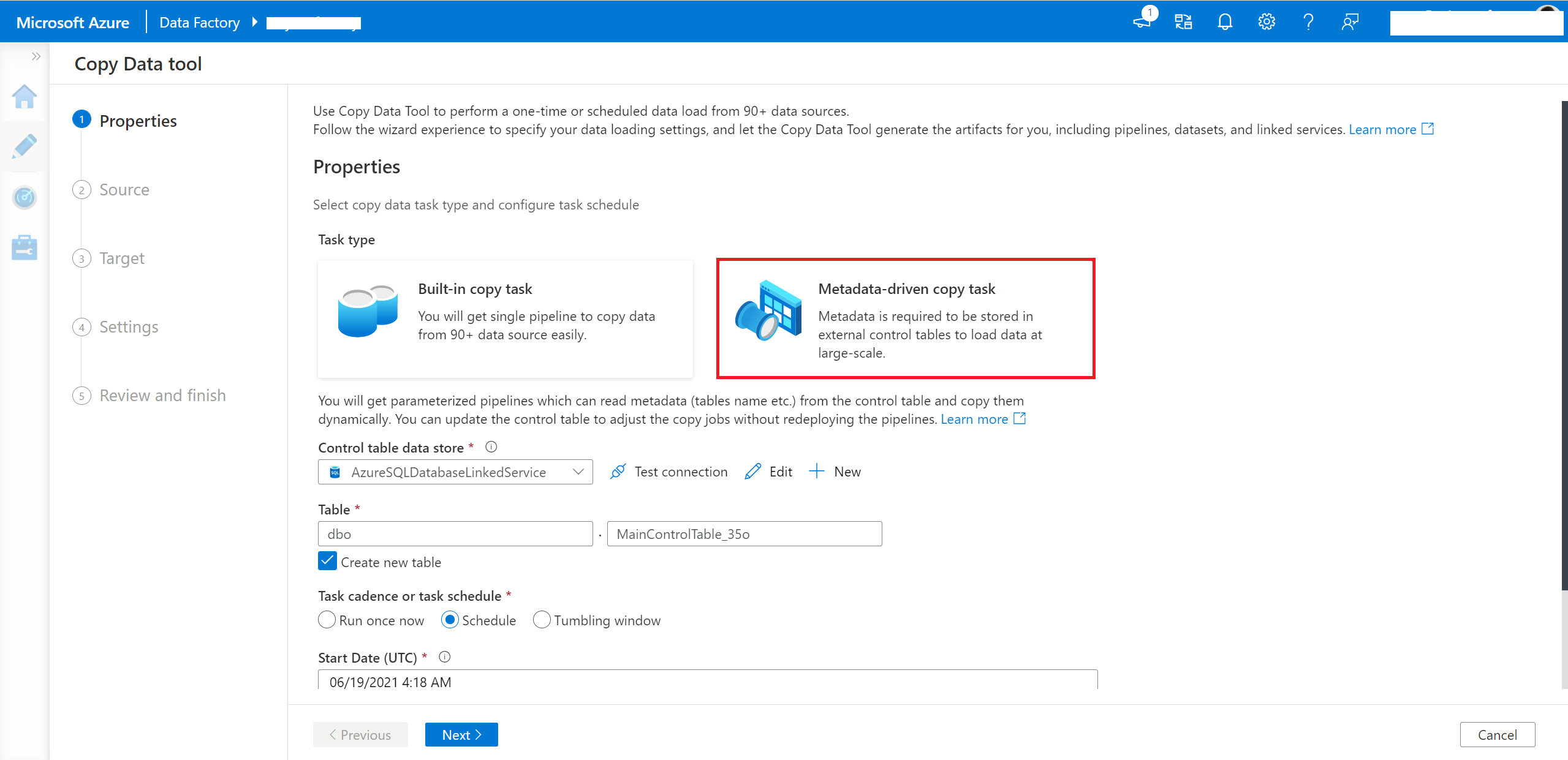
输入您源数据库的连接信息。 也可以使用参数化链接服务。
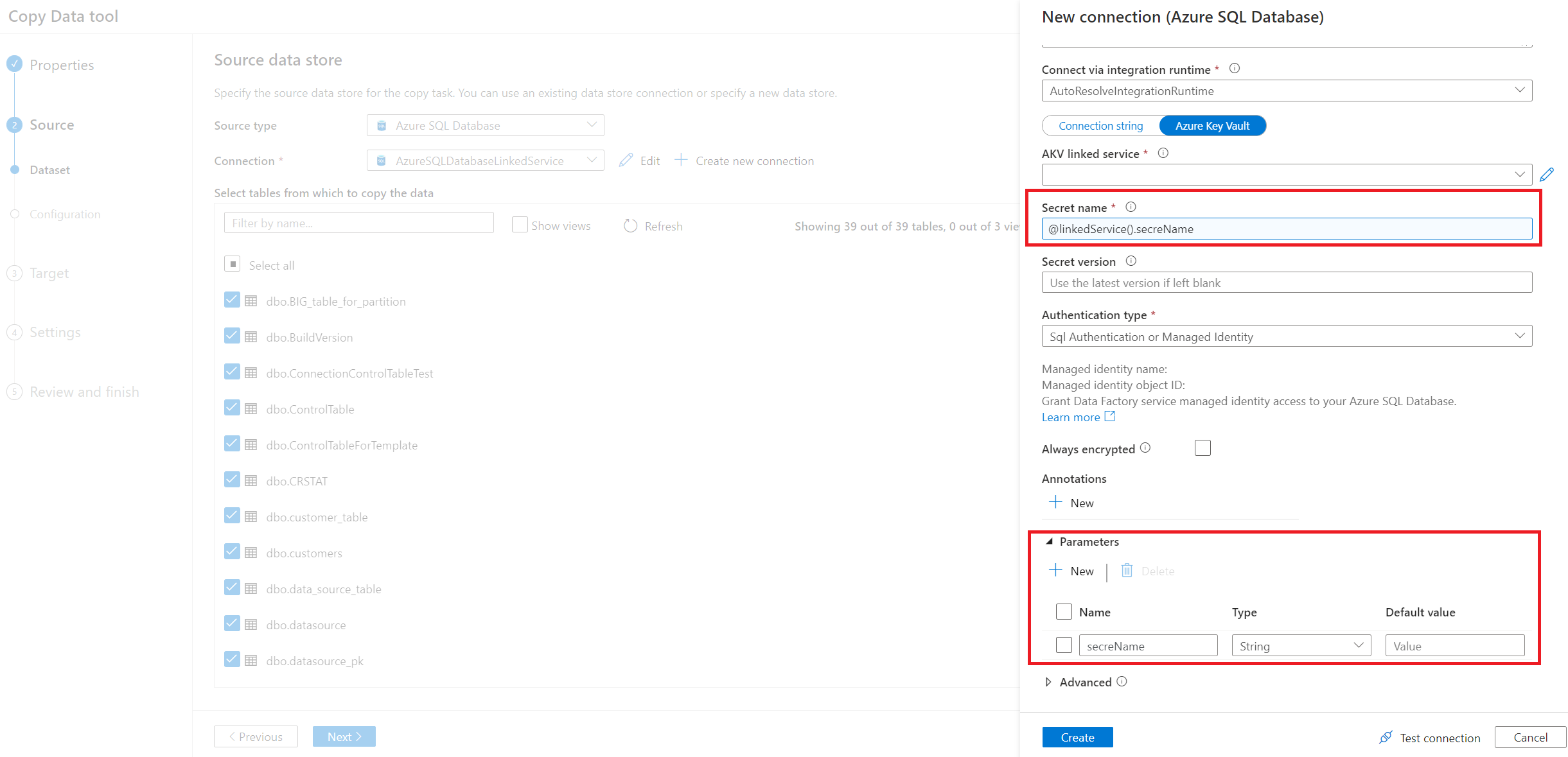
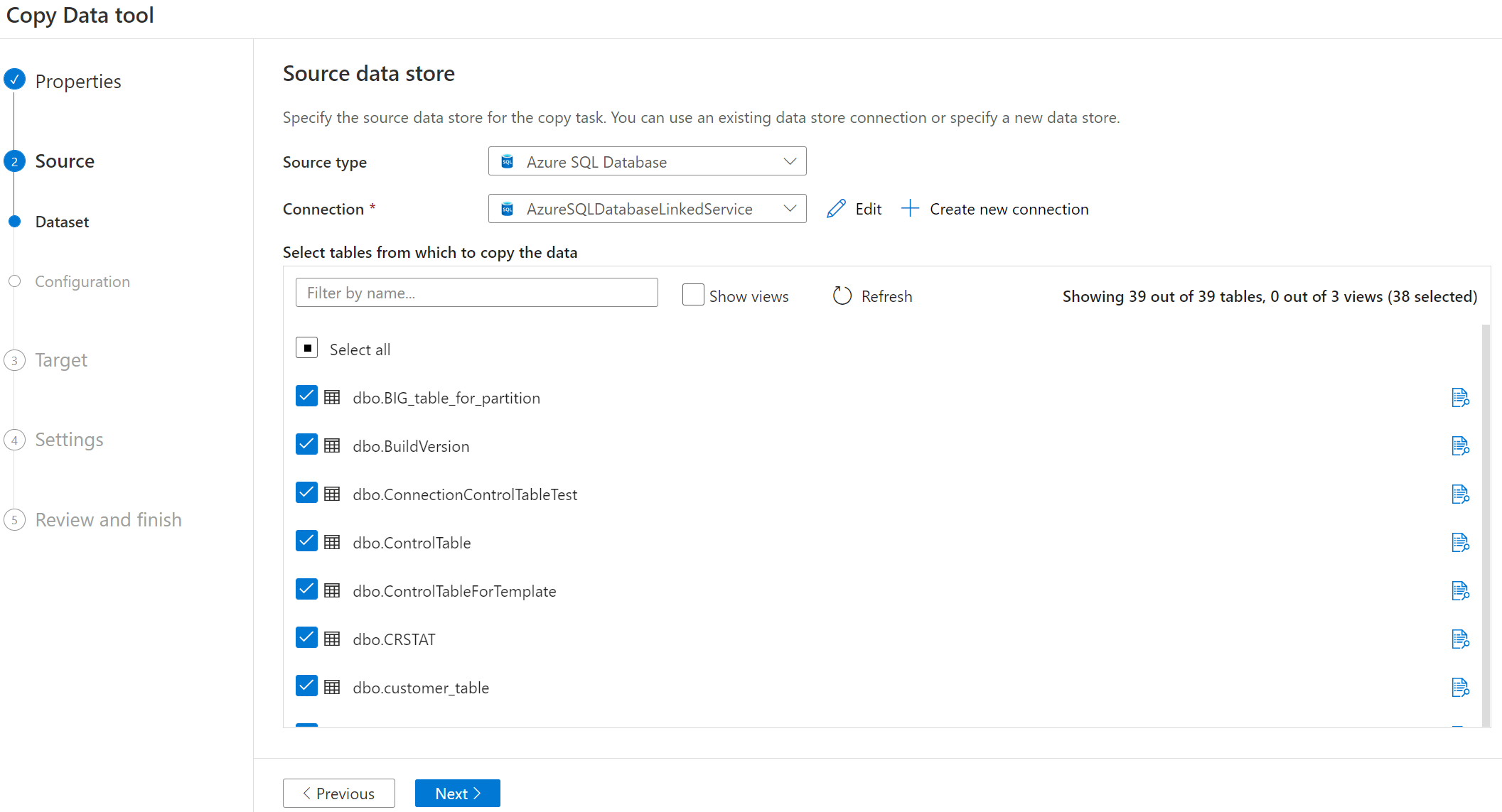
选择要复制的表名称。
注意
如果选择了表格数据存储,则可以在下一页中进一步选择完全加载或增量加载。 如果选择存储商店,则在下一页中您只能选择完全加载。 目前不支持仅从存储中以增量方式加载新文件。
选择加载行为。
提示
如果你要对所有表执行完全复制,请选择“完全加载所有表”。 如果您想进行增量复制,您可以选择“单独对每个表进行配置”,并为每个表选择“增量加载”,还需要指定水印列的名称和值来开始复制。
选择目标数据存储。
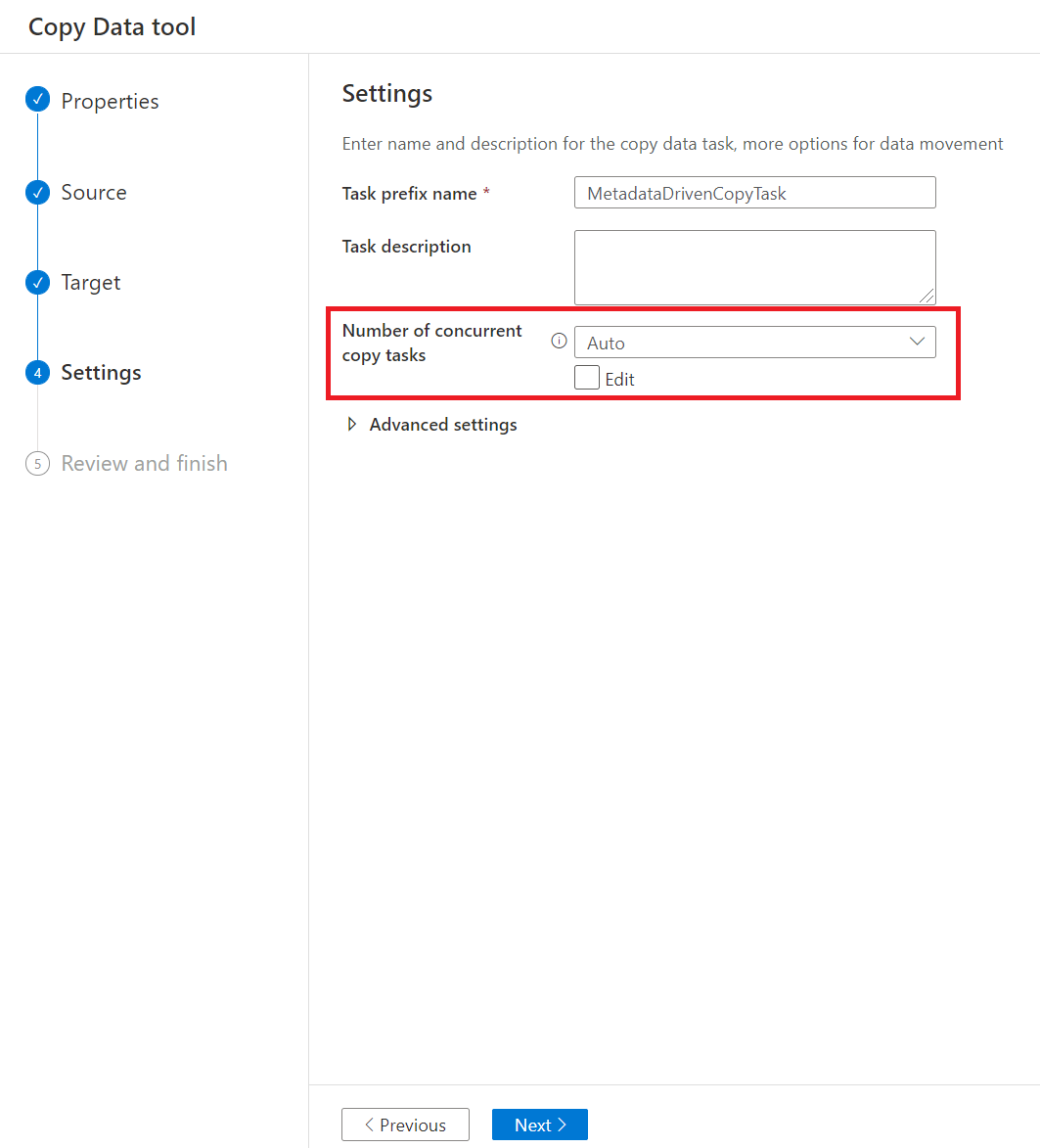
在“设置”页中,您可以通过设置“并发复制任务数”来决定可用于从源存储中并行复制数据的复制活动的最大数量。 默认值为 20。
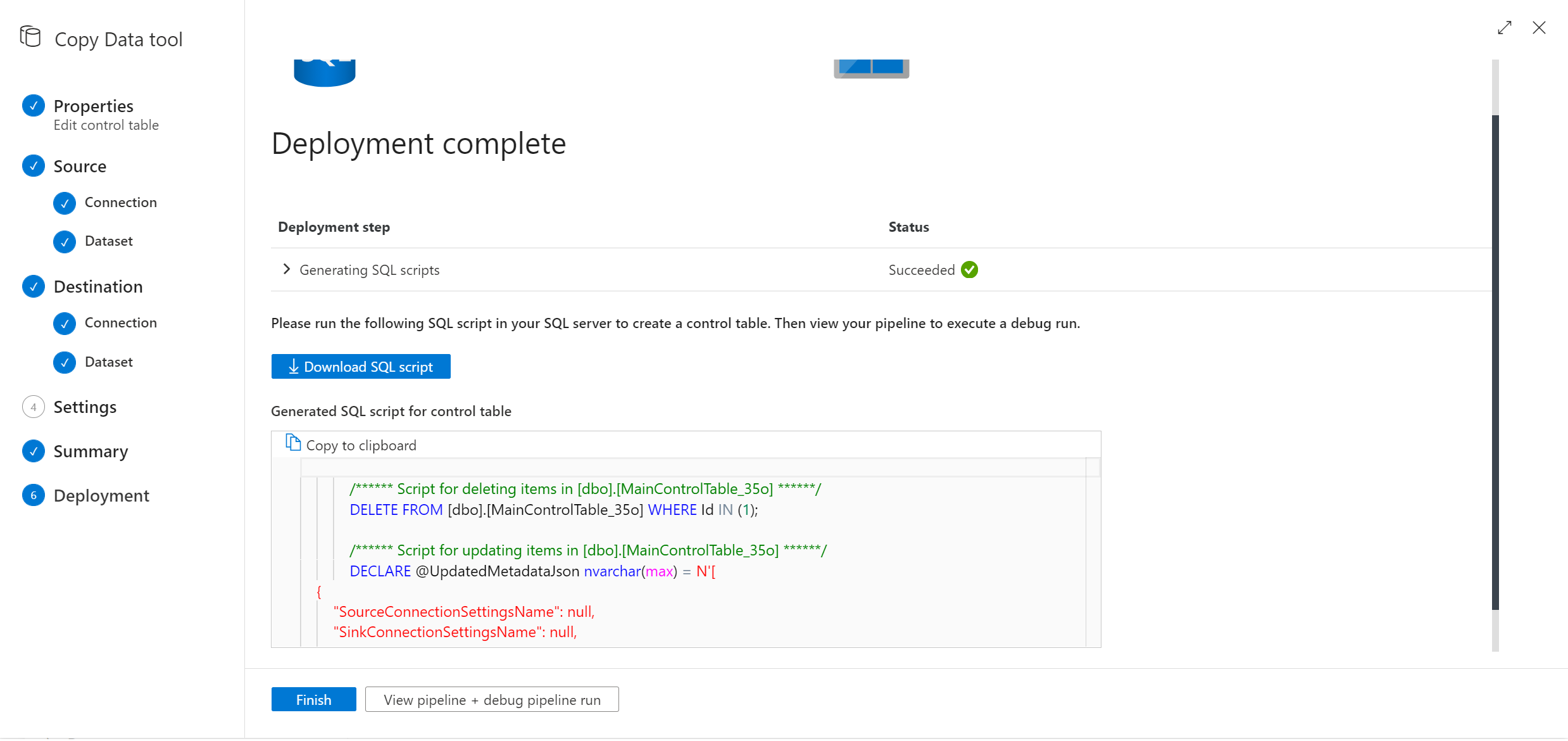
管道部署后,可以从 UI 复制或下载 SQL 脚本,用于创建控制表和存储过程。
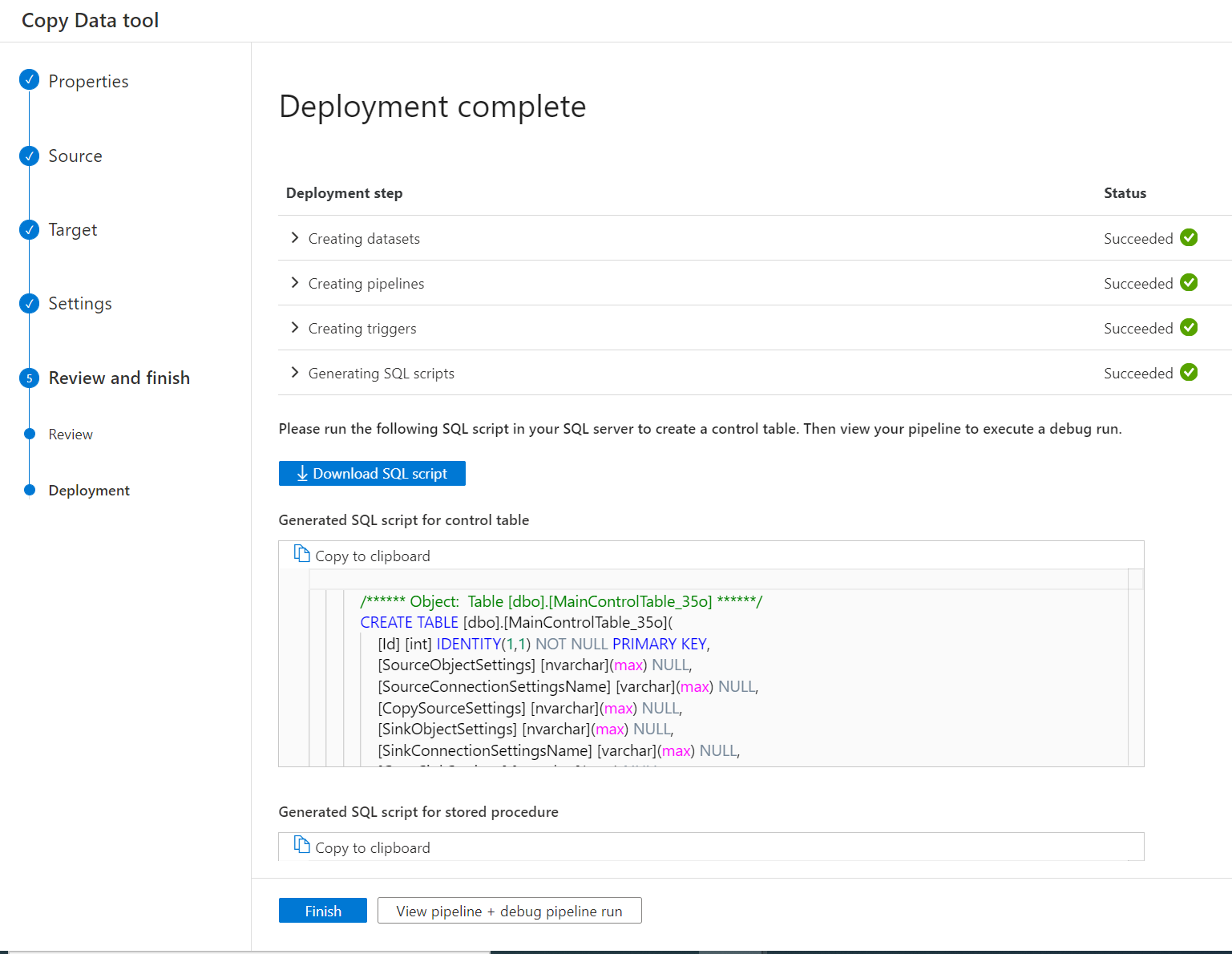
你将看到两个 SQL 脚本。
- 第一个 SQL 脚本用于创建两个控制表。 主控制表存储表列表、文件路径或复制行为。 连接控制表存储数据存储的连接值(如果使用的是参数化链接服务)。
- 第二个 SQL 脚本用于创建存储过程。 每次增量复制任务完成时,用于更新主控制表中的水印值。
打开 SSMS 以连接到控制表服务器,然后运行这两个 SQL 脚本来创建控制表和存储过程。
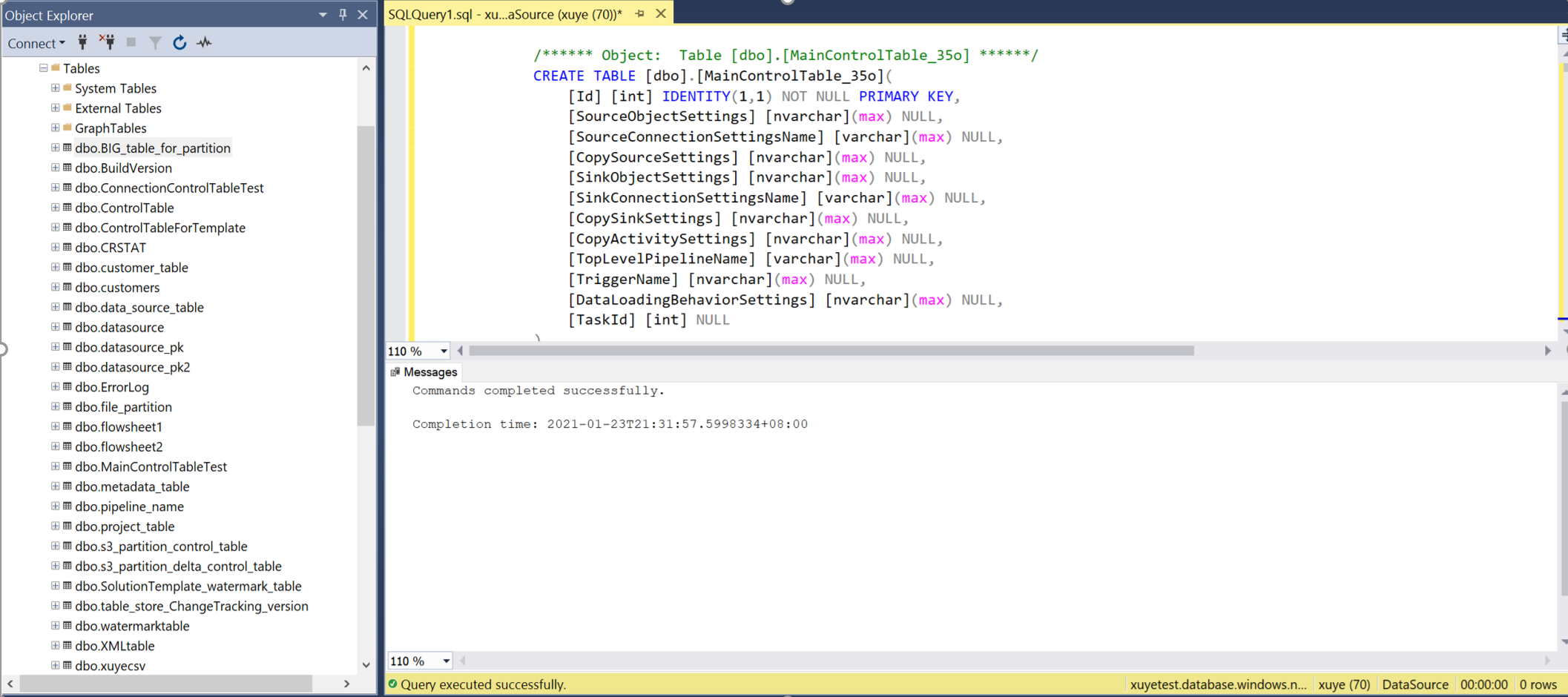
查询主控制表和连接控制表,以查看其中的元数据。
主控制表
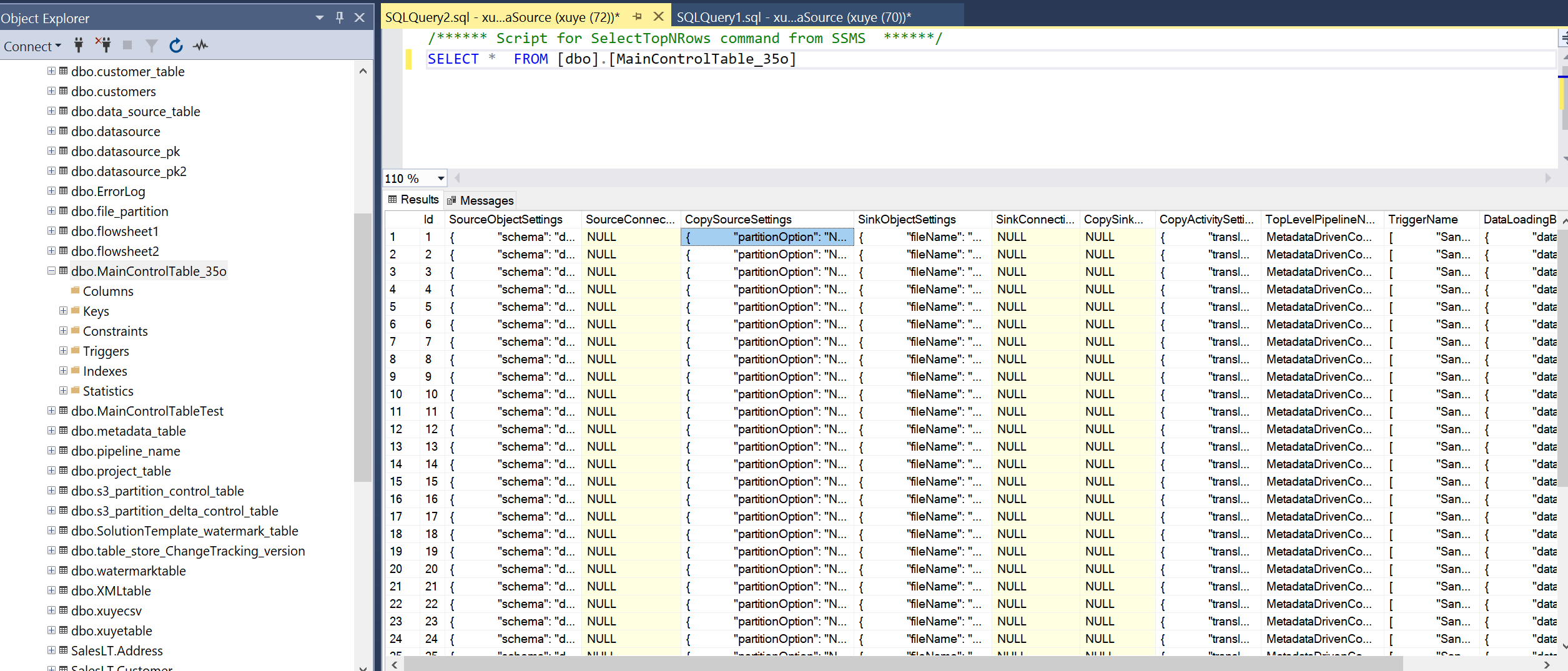
连接控制表

返回 ADF 门户以查看和调试管道。 你将看到已创建一个名为“MetadataDrivenCopyTask_###
######”的文件夹。 单击 名为“MetadataDrivenCopyTask_###_TopLevel”的管道,然后单击调试运行 。需要输入以下参数:
参数名称 说明 并发任务最大数量 (MaxNumberOfConcurrentTasks) 在管道运行之前,始终可以更改最大并发复制活动运行数。 默认值是你在复制数据工具中输入的值。 主控制表名称 在运行之前,始终可以更改主控制表名称,使管道从该表中获取元数据。 连接控制表名称 在运行之前,始终可以更改连接控制表名称(可选),使管道获取与数据存储连接相关的元数据。 从查找活动返回对象的最大数量 为了避免达到输出查找活动的限制,可使用该参数来定义查找活动返回的最大对象数。 在大多数情况下,无需更改默认值。 windowStart 输入动态值(例如 yyyyy/mm/dd)作为文件夹路径时,会使用该参数将当前触发器时间传递给管道,以填充动态文件夹路径。 当管道由计划触发器或翻转窗口触发器触发时,用户无需输入此参数的值。 示例值:2021-01-25T01:49:28Z 启用触发器以使管道可运行。
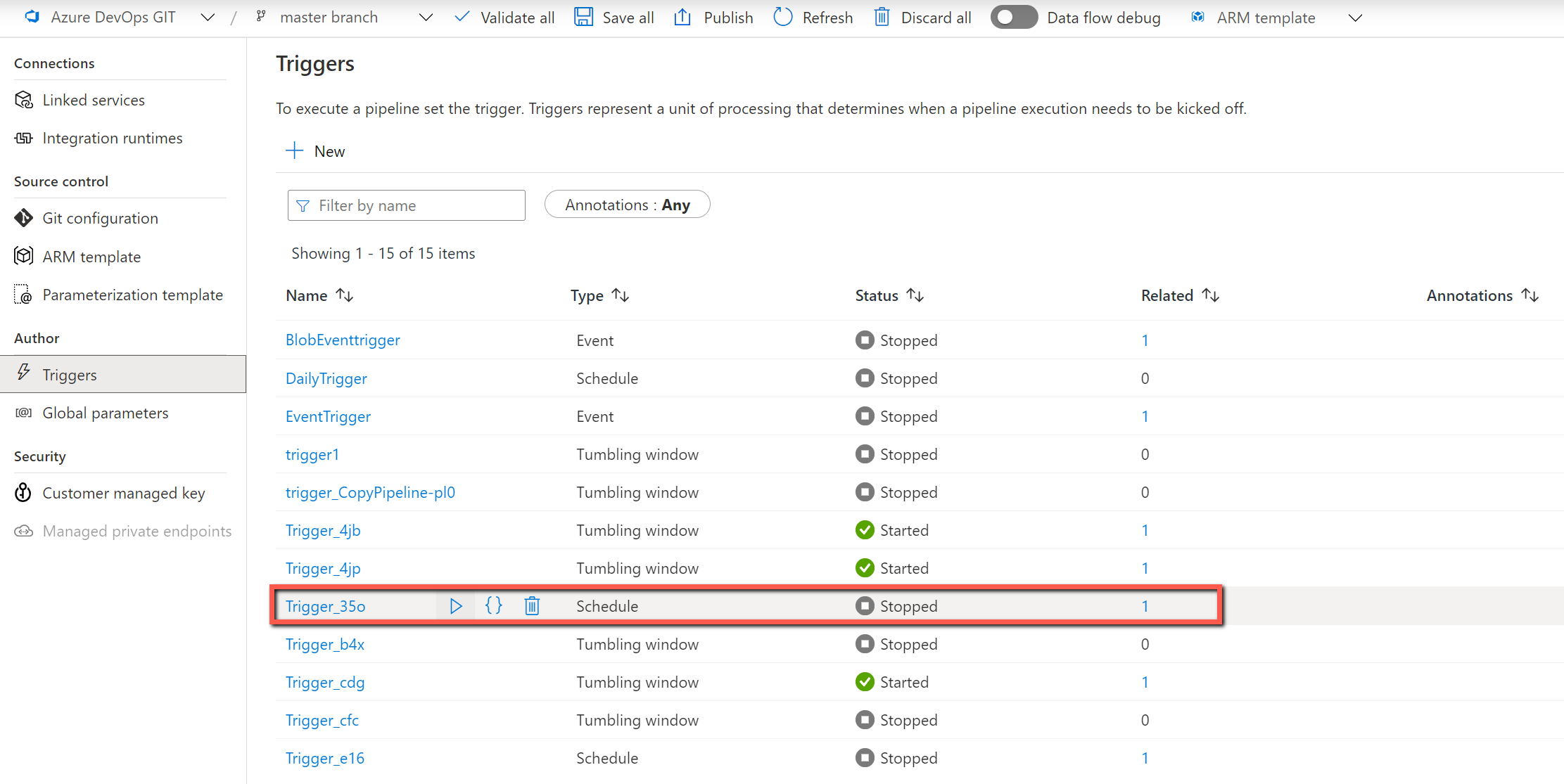
通过复制数据工具更新控制表
始终可以通过添加或删除要复制的对象或者更改每个表的复制行为,来直接更新控制表。 我们还在复制数据工具中创建了 UI 体验,以简化控制表编辑过程。
右键单击顶级管道“MetadataDrivenCopyTask_xxx_TopLevel”并选择“编辑控制表” 。
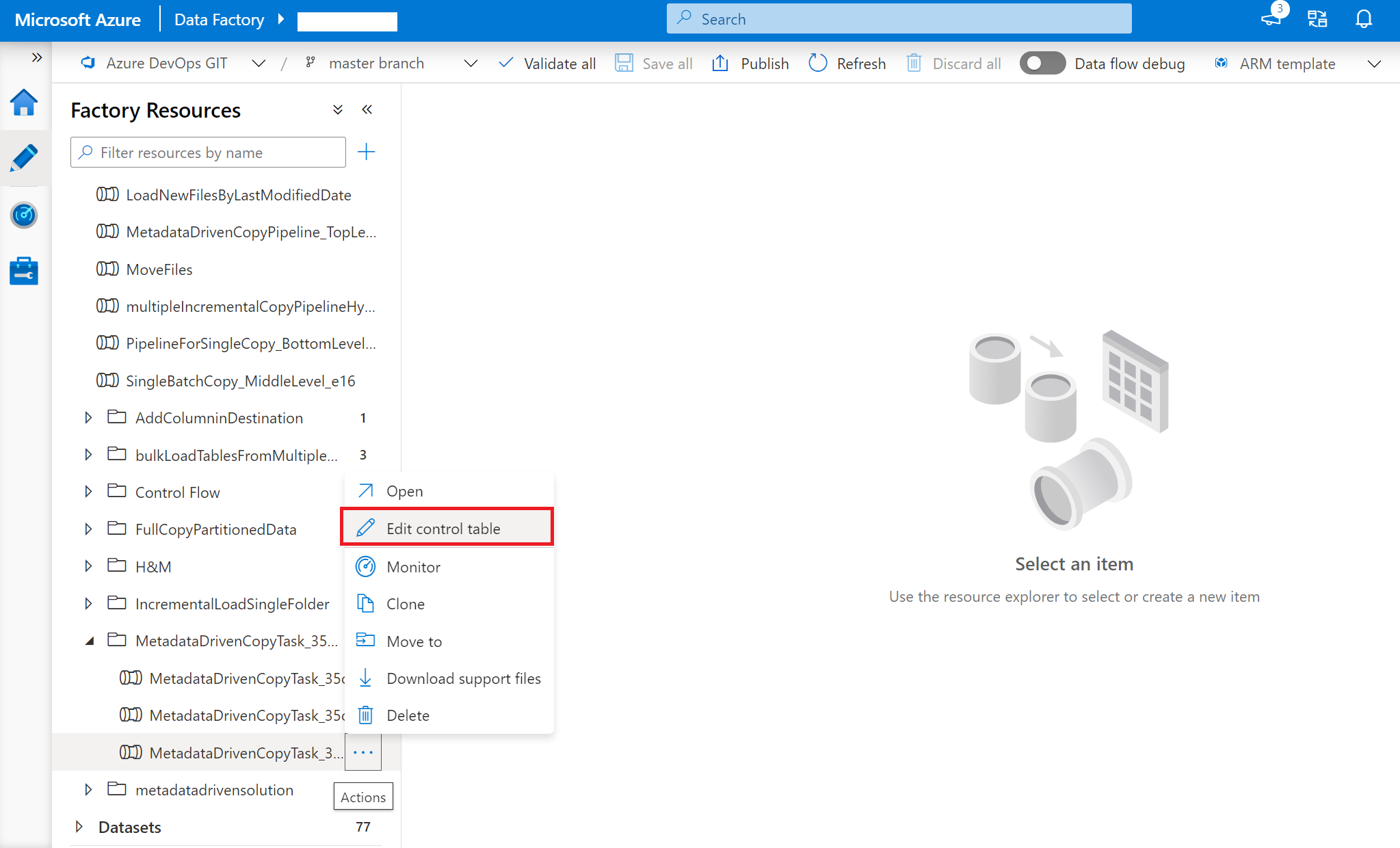
在控制表中选择要编辑的行。
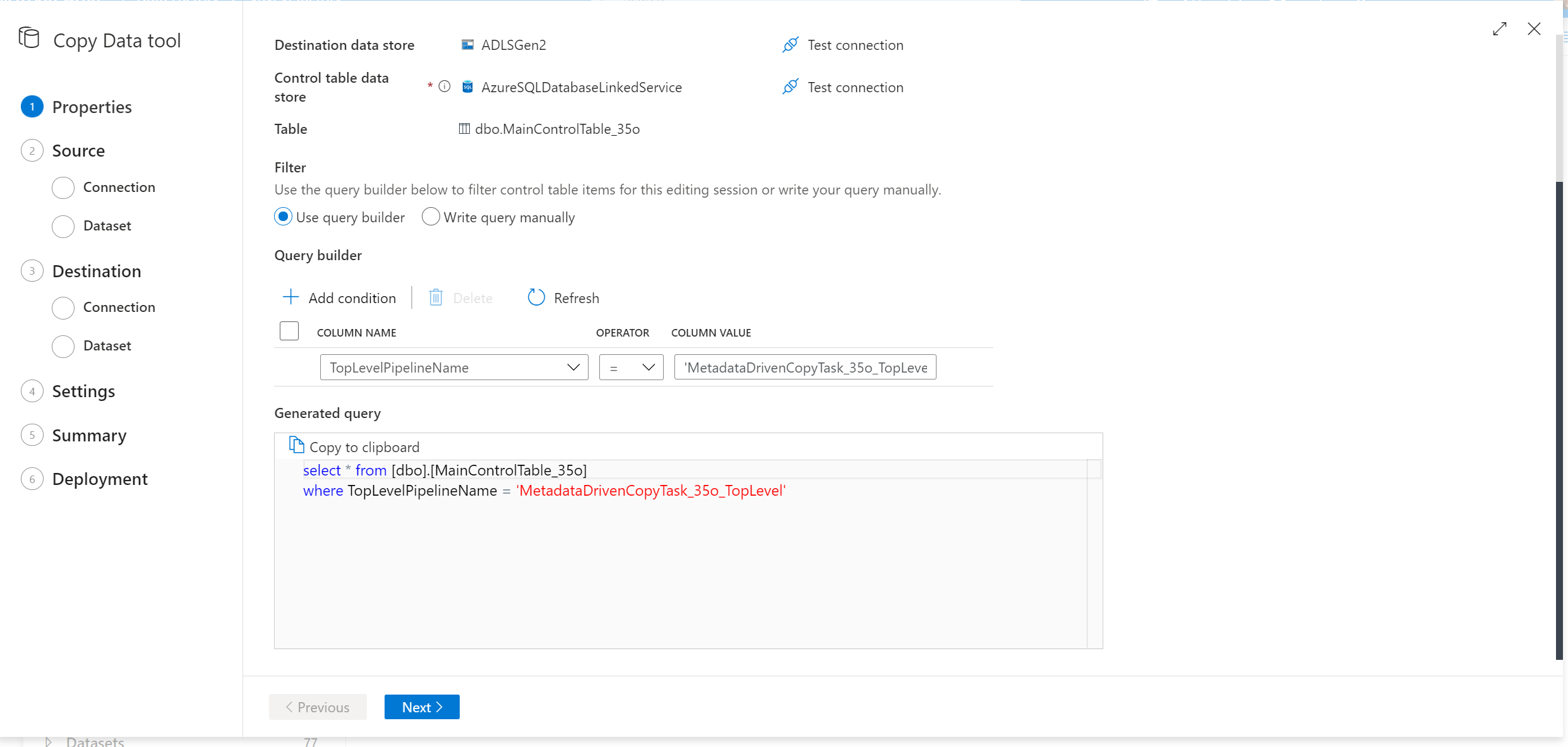
完成复制数据工具中的每个步骤,最终它会为你创建一个新的 SQL 脚本。 重新运行 SQL 脚本以更新控制表。
注意
不会重新部署管道。 新建的 SQL 脚本只能帮助你更新控制表。
控制表
主控制表
控制表中的每一行包含一个要复制的对象(例如一个表)的元数据。
| 列名称 | 说明 |
|---|---|
| ID | 要复制的对象的唯一 ID。 |
| 源对象设置 | 源数据集的元数据。 可以是架构名称、表名称等。此处提供了示例。 |
| SourceConnectionSettingsName(源连接设置名称) | 连接控制表中源连接设置的名称。 它是可选的。 |
| 复制源设置 | 复制操作中源属性的元数据。 可以是查询、分区等。此处提供了示例。 |
| SinkObjectSettings | 目标数据集的元数据。 可以是文件名、文件夹路径、表名称等。此处提供了示例。 如果指定了动态文件夹路径,则变量值不会写入到控制表中的此列。 |
| SinkConnectionSettingsName | 连接控制表中目标连接设置的名称。 它是可选的。 |
| CopySinkSettings | 复制活动中接收器属性的元数据。 可以是 preCopyScript、tableOption 等。此处提供了示例。 |
| 复制活动设置 | 复制活动中翻译器属性的元数据。 用于定义列映射。 |
| TopLevelPipelineName | 可以复制此对象的顶级管道名称。 |
| 触发器名称 | 触发器名称,它可以触发管道来复制此对象。 如果是调试运行,名称为“沙盒”。 如果手动执行,则名称为“手动”。 如果计划内运行,则名称为关联的触发器名称。 它可以输入多个名称。 |
| DataLoadingBehaviorSettings | 完全加载与增量加载。 |
| 任务ID | 按控制表中的 TaskId 确定复制对象的顺序 (ORDER BY [TaskId] DESC)。 如果你要复制巨量的对象,但允许的并发复制数有限,则你可以更改每个对象的 TaskId,以确定哪些对象可以先复制。 默认值为 0。 |
| 复制已启用 | 指定是否在数据引入过程中启用了该项。 允许的值:1(已启用)、0(已禁用)。 默认值为 1。 |
连接控制表
控制表中的每一行包含该数据存储的一个连接设置。
| 列名称 | 说明 |
|---|---|
| 名称 | 主控制表中参数化连接的名称。 |
| 连接设置 | 连接设置。 可以是数据库名称、服务器名称等。 |
Pipelines
你将看到复制数据工具生成了三个级别的管道。
MetadataDrivenCopyTask_xxx_TopLevel
此管道将计算需要在此运行中复制的对象(表等)总数,根据允许的最大并发复制任务数提供顺序批数,然后执行另一个管道来按顺序复制不同的批。
参数
| 参数名称 | 说明 |
|---|---|
| 并发任务最大数量 (MaxNumberOfConcurrentTasks) | 在管道运行之前,始终可以更改最大并发复制活动运行数。 默认值是你在复制数据工具中输入的值。 |
| 主控制表名称 | 主控制表的表名称。 在运行之前,管道将从此表中获取元数据 |
| 连接控制表名称 | 连接控制表的表名称(可选)。 在运行之前,管道将获取与数据存储连接相关的元数据 |
| 从查找活动返回对象的最大数量 | 为了避免达到输出查找活动的限制,可使用该参数来定义查找活动返回的最大对象数。 在大多数情况下,无需更改默认值。 |
| windowStart | 输入动态值(例如 yyyyy/mm/dd)作为文件夹路径时,会使用该参数将当前触发器时间传递给管道,以填充动态文件夹路径。 当管道由计划触发器或翻转窗口触发器触发时,用户无需输入此参数的值。 示例值:2021-01-25T01:49:28Z |
活动
| 活动名称 | 活动类型 | 说明 |
|---|---|---|
| GetSumOfObjectsToCopy(获取要复制的对象总和) | 查找 | 计算需要在此运行中复制的对象(表等)总数。 |
| 顺序复制对象批次 | ForEach | 根据允许的最大并发复制任务数提供顺序批数,然后执行另一个管道来按顺序复制不同的批。 |
| 在一个批次中复制对象 | 执行流水线 | 执行另一个管道来复制一批对象。 属于此批的对象将会并行复制。 |
MetadataDrivenCopyTask_xxx_中间层级
此管道将复制一批对象。 属于此批的对象将会并行复制。
参数
| 参数名称 | 说明 |
|---|---|
| 从查找活动返回对象的最大数量 | 为了避免达到输出查找活动的限制,可使用该参数来定义查找活动返回的最大对象数。 在大多数情况下,无需更改默认值。 |
| TopLevelPipelineName | 顶层管道的名称。 |
| 触发器名称 | 触发器的名称。 |
| 当前批次的顺序编号 | 顺序批的 ID。 |
| 复制对象总数 | 要复制的对象总数。 |
| 当前批次复制对象总和 | 当前批中要复制的对象数。 |
| 主控制表名称 | 主控制表的名称。 |
| 连接控制表名称 | 连接控制表的名称。 |
活动
| 活动名称 | 活动类型 | 说明 |
|---|---|---|
| 将一批划分为多个组 | ForEach | 将单个批中的对象划分为多个并行组,以避免达到查找活动的输出限制。 |
| 每组对象获取以复制 | 查找 | 从控制表中获取需要在此组中复制的对象(表等)。 按控制表中的 TaskId 确定复制对象的顺序 (ORDER BY [TaskId] DESC)。 |
| 复制同组中的对象 | 执行流水线 | 执行另一个管道以从一个组复制对象。 属于此组的对象将会并行复制。 |
MetadataDrivenCopyTask_xxx_BottomLevel
此数据管道将从一个分组中复制对象。 属于此组的对象将会并行复制。
参数
| 参数名称 | 说明 |
|---|---|
| 每组对象复制 | 当前组中要复制的对象数。 |
| 连接控制表名称 | 连接控制表的名称。 |
| windowStart | 用于将当前触发器时间传递给管道,以填充动态文件夹路径(如果已由用户配置)。 |
活动
| 活动名称 | 活动类型 | 说明 |
|---|---|---|
| ListObjectsFromOneGroup | ForEach | 列出一个组中的对象,并将其中的每个对象迭代到下游活动。 |
| 根据加载行为分配任务 | 交换机 | 检查每个对象的加载行为。 如果模式是默认或“FullLoad”,则执行完全加载。 如果是 DeltaLoad 情况,则通过水印列进行增量加载,以便识别更改。 |
| FullLoadOneObject | 复制 | 获取此对象的完整快照并将其复制到目标。 |
| DeltaLoadOneObject | 复制 | 仅复制自上次以来已更改的数据,通过比较水印列中的值来识别这些更改。 |
| GetMaxWatermarkValue | 查找 | 查询源对象以获取水印列中的最大值。 |
| UpdateWatermarkColumnValue | 存储过程 | 将新的水印值写回到控制表供下次使用。 |
已知的限制
- 无法在 ADF 中参数化 IR 名称、数据库类型和文件格式类型。 例如,如果要从 Oracle Server 和 SQL Server 引入数据,则需要两个不同的参数化管道。 但是,一个控制表可由两组管道共享。
- OPENJSON 用于通过复制数据工具生成 SQL 脚本。 如果使用SQL Server托管控制表,则必须SQL Server 2016(13.x)及更高版本才能支持 OPENJSON 函数。
相关内容
请尝试以下使用“复制数据”工具的教程: