适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
数据流可在Azure 数据工厂管道和Azure Synapse Analytics管道中使用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
借助透视转换,可根据单个列的唯一行值创建多个列。 透视是一种聚合转换,其中您需要选择分组依据列,并使用聚合函数生成透视列。
配置
透视转换需要三种不同的输入:分组依据列、透视关键字以及如何生成旋转后的列
分组依据
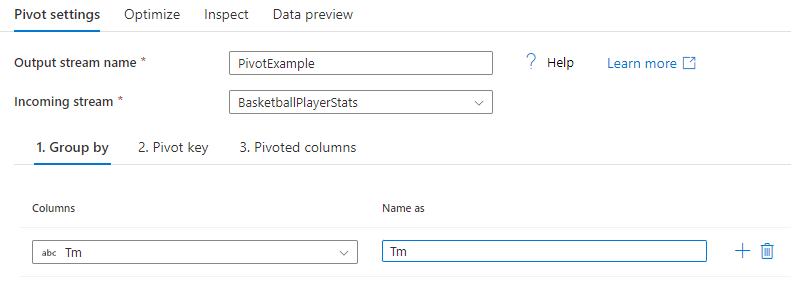
选择用于对已透视列进行聚合的那些列。 输出数据将具有相同“分组依据”值的所有行归并为一行。 在透视列中完成的聚合发生在每个组中。
本部分为可选。 如果未选择按列分组,则聚合整个数据流,并且仅输出一行。
枢轴键
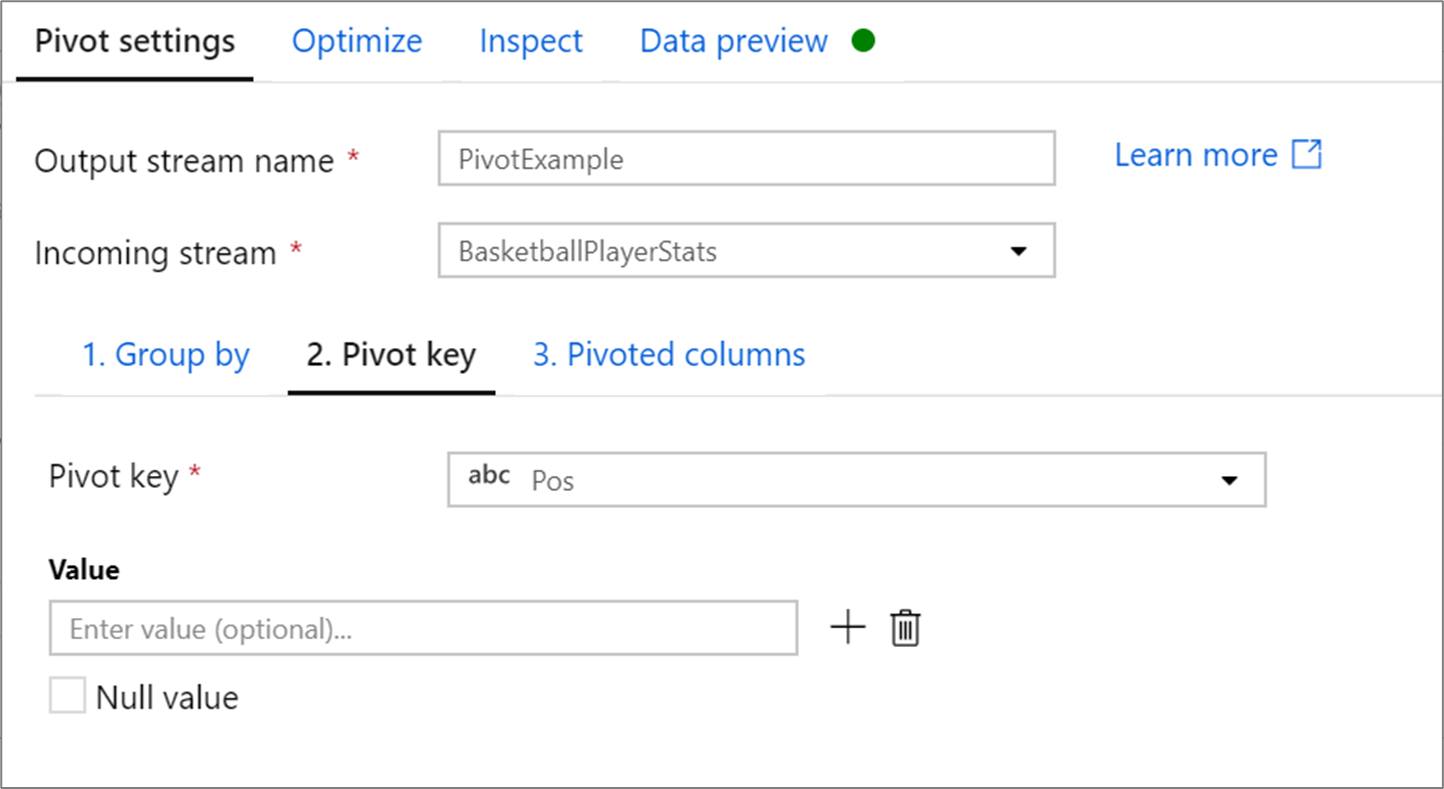
透视键是将其行值透视到新列的列。 默认情况下,数据透视表转换会为每个唯一的行值创建一个新列。
在标有“Value”的部分中,可以输入要数据透视的特定行值。 仅对本部分中输入的行值进行数据透视。 启用 Null 值 将为列中的 null 值创建一个透视字段。
旋转列
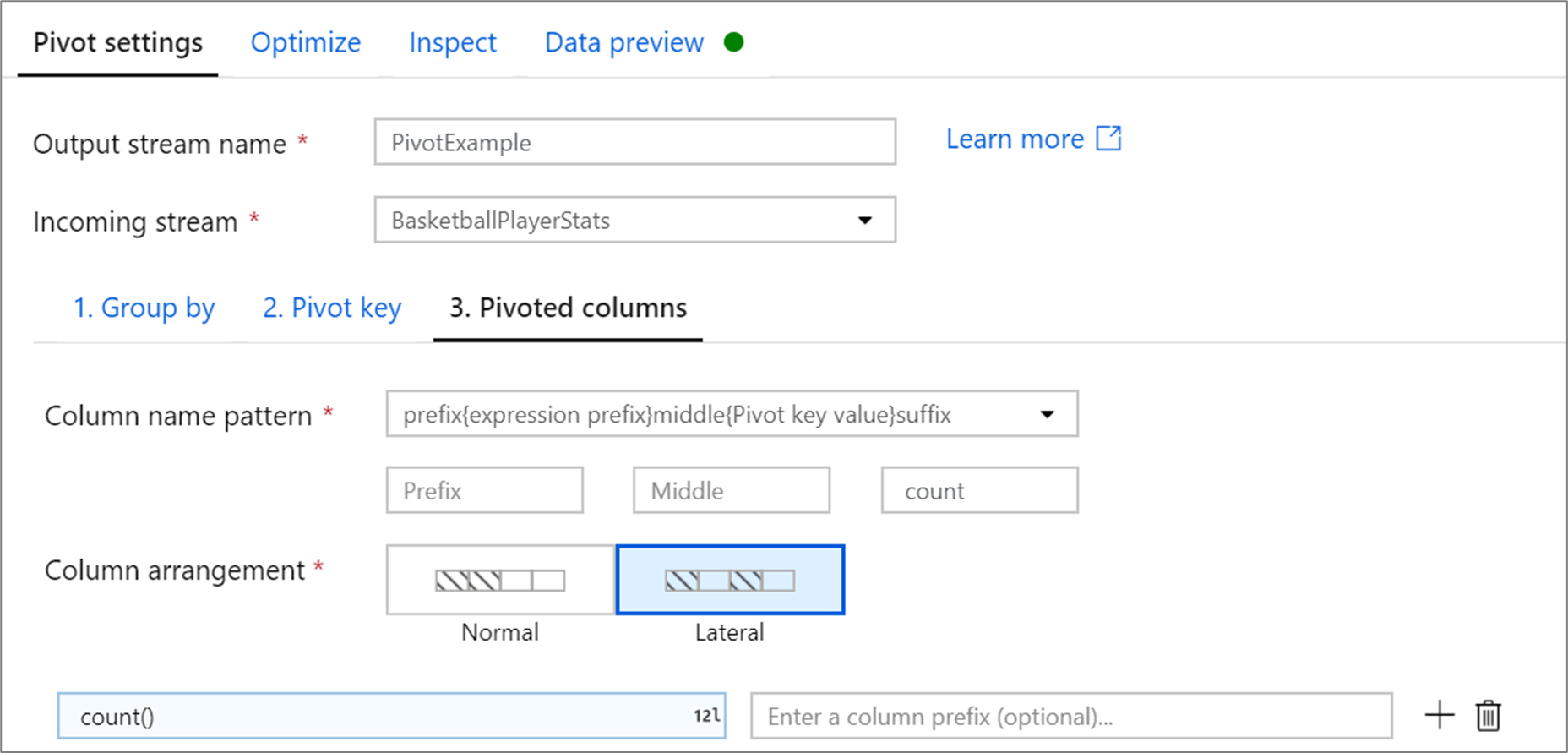
对于变成列的每个唯一透视键值,将为每个组生成一个聚合的行值。 你可以为每个透视键创建多个列。 每个透视列必须至少包含一个聚合函数。
列名称模式: 选择如何格式化每个透视列的列名称。 输出的列名称是透视键值、列前缀和可选前缀、后缀、中间字符的组合。
列排列方式: 如果为每个透视键生成多个透视列,请选择所需的列排序方式。
列前缀: 如果为每个透视键生成多个透视列,请为每一列输入一个列前缀。 如果您只有一个已透视的列,则此设置是可选的。
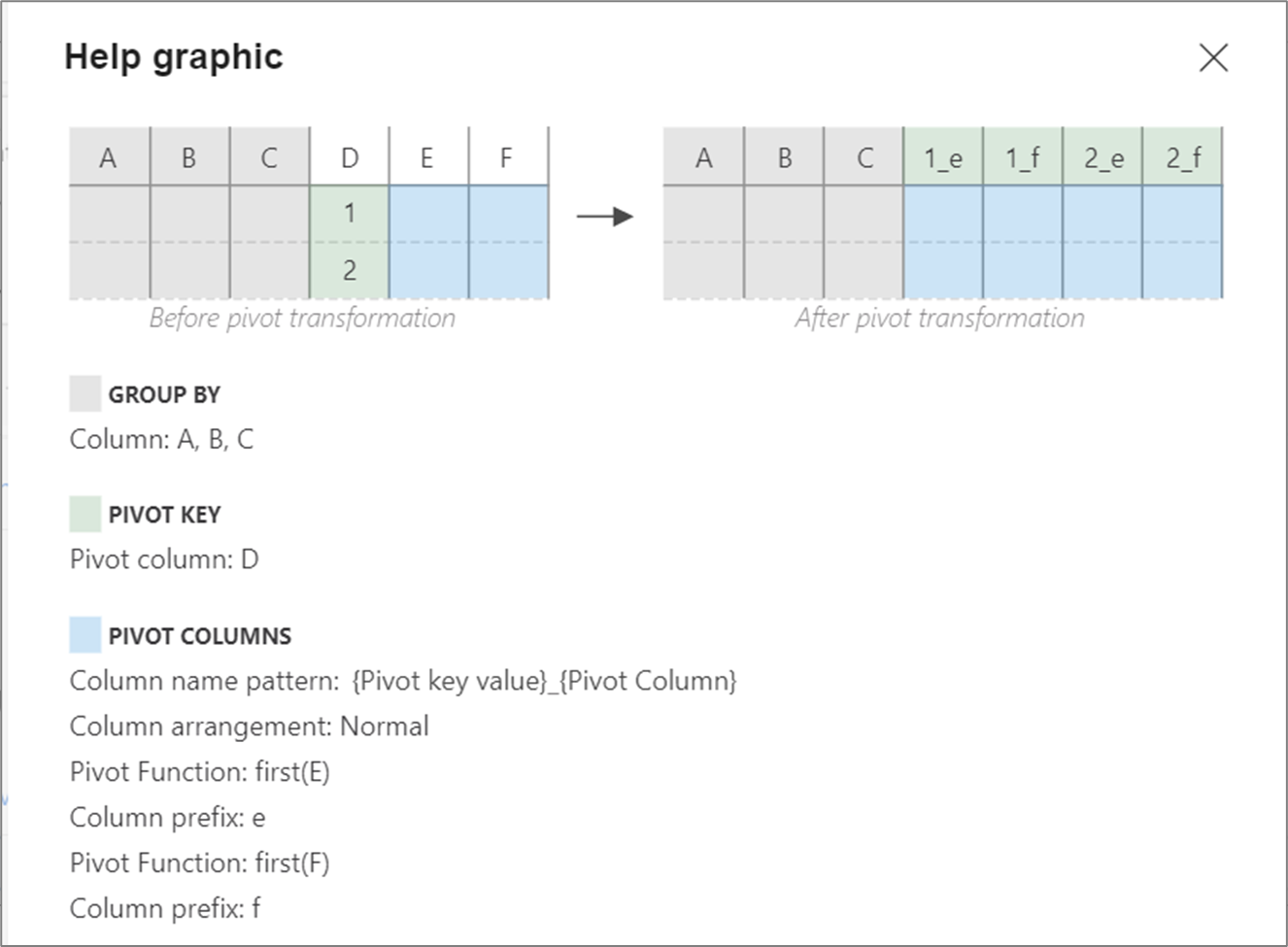
帮助图形
帮助图示展示了不同的枢轴组件如何相互交互。
透视元数据
如果未在透视键配置中指定任何值,则透视列会在运行时动态生成。 旋转列的数量等于唯一旋转键值的数量乘以旋转列的数量。 由于这个数字会不断变化,因此UX不会在Inspect选项卡中显示列元数据,也没有进行列传播。 若要转换这些列,请使用映射数据流的列模式功能。
如果设置了特定的透视键值,则透视列将显示在元数据中。 在“检查”和“接收器”映射中,列名可供你使用。
根据漂移列生成元数据
透视基于行值动态生成新的列名称。 可以将这些新列添加到元数据中,以便稍后在数据流中引用。 为此,请使用数据预览中的映射偏移快速操作。
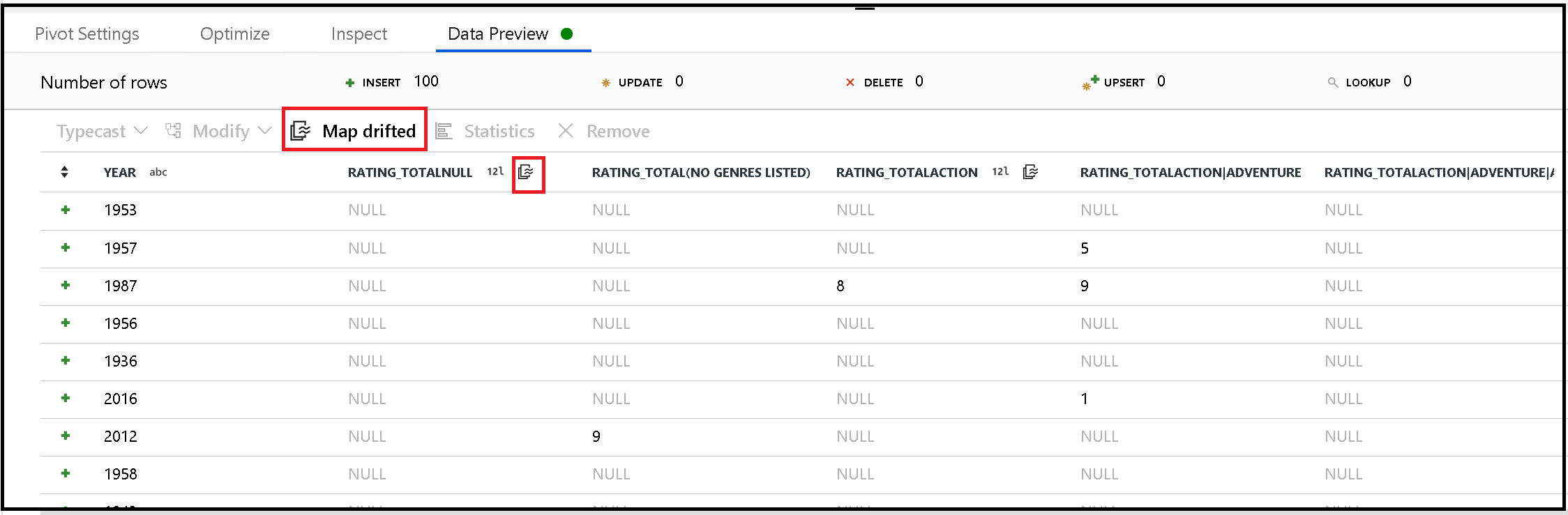
下沉透视列
尽管旋转列是动态的,但仍可以将它们写入目标数据存储。 在汇集设置中启用“允许架构漂移”。 这样,就可以编写元数据中不包含的列。 列元数据中不会显示新的动态名称,但架构漂移选项允许你将数据存储。
重连原始字段
透视转换仅将分组和透视后的列进行投影。 如果希望输出数据包含其他输入列,请使用自联接模式。
数据流脚本
语法
<incomingStreamName>
pivot(groupBy(Tm),
pivotBy(<pivotKeyColumn, [<specifiedColumnName1>,...,<specifiedColumnNameN>]),
<pivotColumnPrefix> = <pivotedColumnValue>,
columnNaming: '< prefix >< $N | $V ><middle >< $N | $V >< suffix >',
lateral: { 'true' | 'false'}
) ~> <pivotTransformationName
示例
配置部分中显示的屏幕具有以下数据流脚本:
BasketballPlayerStats pivot(groupBy(Tm),
pivotBy(Pos),
{} = count(),
columnNaming: '$V$N count',
lateral: true) ~> PivotExample
相关内容
尝试使用逆透视转换将列值转换为行值。