重要
Horovod 和 HorovodRunner 现已弃用。 15.4 LTS ML 之后的版本不会预安装此包。 对于分布式深度学习,Databricks 建议使用 TorchDistributor 通过 PyTorch 进行分布式训练,或使用 tf.distribute.Strategy API 通过 TensorFlow 进行分布式训练。
了解如何使用 HorovodRunner 在 Azure Databricks 上将 Horovod 训练作业作为 Spark 作业启动,以对机器学习模型执行分布式训练。
什么是 HorovodRunner?
HorovodRunner 是一个常规 API,用于通过 Horovod 框架在 Azure Databricks 上运行分布式深度学习工作负载。 通过将 Horovod 与 Spark 的屏障模式集成,Azure Databricks 可为 Spark 上长期运行的深度学习训练作业提供更高的稳定性。 HorovodRunner 采用一个 Python 方法,该方法包含带 Horovod 挂钩的深度学习训练代码。 HorovodRunner 在驱动程序上对该方法执行 pickle 操作,然后将其分发到 Spark 辅助角色。 使用屏障执行模式将 Horovod MPI 作业以 Spark 作业的形式嵌入。 第一个执行程序使用 BarrierTaskContext 收集所有任务执行程序的 IP 地址,并使用 mpirun 触发 Horovod 作业。 每个 Python MPI 进程加载执行过 pickle 操作的用户程序,然后将其反序列化并运行。
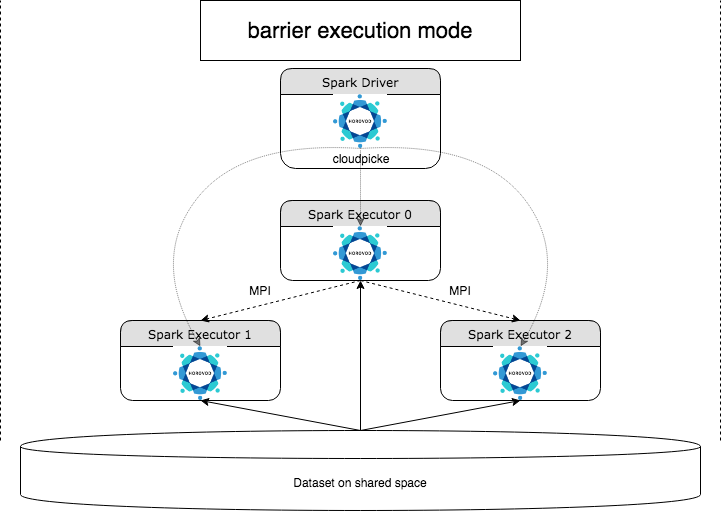
使用 HorovodRunner 进行分布式训练
HorovodRunner 可让你将 Horovod 训练作业作为 Spark 作业启动。 HorovodRunner API 支持表中显示的方法。 有关详细信息,请参阅 HorovodRunner API 文档。
| 方法和签名 | 说明 |
|---|---|
init(self, np) |
创建 HorovodRunner 的实例。 |
**run(self, main, **kwargs)** |
运行调用 main(**kwargs) 的 Horovod 训练作业。 使用 cloudpickle 对 main 函数和关键字参数进行序列化,并将其分发到群集工作器。 |
使用 HorovodRunner 开发分布式训练程序的一般方法如下:
创建
HorovodRunner实例,并使用节点数将其初始化。根据 Horovod 用法中所述的方法定义 Horovod 训练方法,确保可在该方法中添加任何 import 语句。
将训练方法传递到
HorovodRunner实例。
例如:
hr = HorovodRunner(np=2)
def train():
import tensorflow as tf
hvd.init()
hr.run(train)
若要仅使用 n 子进程在驱动程序上运行 HorovodRunner,请使用 hr = HorovodRunner(np=-n)。 例如,如果驱动程序节点上有 4 个 GPU,则 n 最多可选为 4。 有关参数 np 的详细信息,请参阅 HorovodRunner API 文档。 有关如何为每个子进程固定一个 GPU 的详细信息,请参阅 Horovod 使用指南。
常见错误如下:找不到 TensorFlow 对象,或无法对该对象执行 pickle 操作。 当库 import 语句未分发给其他执行器时,就会发生这种情况。 为避免此问题,请在 Horovod 训练方法的顶部以及 Horovod 训练方法中调用的其他任何用户定义函数内部包含所有 import 语句(例如 import tensorflow as tf)。
使用 Horovod 时间线记录 Horovod 训练
Horovod 可记录其活动的时间线,称为 Horovod 时间线。
重要
Horovod 时间线会对性能造成重大影响。 启用 Horovod 时间线后,Inception3 吞吐量可能会降低约 40%。 若要加速 HorovodRunner 作业,请勿使用 Horovod 时间线。
训练进行时,无法查看 Horovod 时间线。
若要记录 Horovod 时间线,请将 HOROVOD_TIMELINE 环境变量设置为时间线文件的保存位置。 Databricks 建议使用共享存储上的位置,以便可以轻松检索时间线文件。 例如,可按如下所示使用 DBFS 本地文件 API:
timeline_dir = "/dbfs/ml/horovod-timeline/%s" % uuid.uuid4()
os.makedirs(timeline_dir)
os.environ['HOROVOD_TIMELINE'] = timeline_dir + "/horovod_timeline.json"
hr = HorovodRunner(np=4)
hr.run(run_training_horovod, params=params)
然后,将时间线特定的代码添加到训练函数的开头和末尾。 以下示例笔记本包含示例代码,该代码可用作查看训练进度的临时解决方法。
Horovod 时间线示例笔记本
若要下载时间线文件,请使用 Databricks CLI,然后使用 Chrome 浏览器的 chrome://tracing 工具查看该文件。 例如:
开发工作流
下面是将单节点深度学习代码迁移到分布式训练的一般步骤。 本部分中的示例:使用 HorovodRunner 迁移到分布式深度学习演示了这些步骤。
准备单节点代码:使用 TensorFlow、Keras 或 PyTorch 准备并测试单节点代码。
迁移到 Horovod: 按照 Horovod 用法中的说明使用 Horovod 迁移代码,并在驱动程序上对其进行测试:
- 添加
hvd.init()以初始化 Horovod。 - 使用
config.gpu_options.visible_device_list固定服务器 GPU,以供此进程使用。 典型设置是每个进程使用一个 GPU,这样可以将设置为“本地等级”。 这样的话,将向服务器上的第一个进程分配第一个 GPU,向第二个进程分配第二个 GPU,依此类推。 - 包含数据集的分片。 运行分布式训练时,该数据集运算符非常有用,因为它允许每个辅助角色读取唯一的子集。
- 按辅助角色数缩放学习速率。 按工作器数缩放同步分布式训练中的有效批大小。 提高学习速率可以补偿批大小的增大。
- 在
hvd.DistributedOptimizer中包装优化器。 分布式优化器将梯度计算委派给初始优化器,使用 allreduce 或 allgather 对梯度求平均,然后应用平均后的梯度。 - 添加
hvd.BroadcastGlobalVariablesHook(0),将初始变量状态从等级 0 广播到其他所有进程。 使用随机权重开始训练或从检查点还原训练时,必须这样操作以确保所有辅助角色实现一致的初始化。 另外,如果你不使用MonitoredTrainingSession,则可在初始化全局变量后执行hvd.broadcast_global_variables操作。 - 将代码修改为仅在工作节点 0 上保存检查点,以防止其他工作节点损坏检查点。
- 添加
迁移到 HorovodRunner:HorovodRunner 通过调用 Python 函数来运行 Horovod 训练作业。 必须将主要训练过程包装到单个 Python 函数中。 然后,可在本地模式和分布式模式下测试 HorovodRunner。
更新深度学习库
如果要升级或降级 TensorFlow、Keras 或 PyTorch,必须重新安装 Horovod,以便根据新安装的库对其进行编译。 例如,如果要升级 TensorFlow,Databricks 建议使用 TensorFlow 安装说明中的 init 脚本,并在该脚本末尾追加以下特定于 TensorFlow 的 Horovod 安装代码。 请参阅 Horovod 安装说明以使用不同的组合,例如升级或降级 PyTorch 和其他库。
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt update
# Using the same compiler that TensorFlow was built to compile Horovod
apt install g++-7 -y
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60
HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
示例:使用 HorovodRunner 迁移到分布式深度学习
以下示例基于 MNIST 数据集,演示如何使用 HorovodRunner 将单节点深度学习程序迁移到分布式深度学习。
限制
使用工作区文件时,如果
np设置为大于 1 并且笔记本从其他相关文件导入,则 HorovodRunner 将不起作用。 请考虑使用 horovod.spark 而不使用HorovodRunner。如果遇到类似
WARNING: Open MPI accepted a TCP connection from what appears to be a another Open MPI process but cannot find a corresponding process entry for that peer的错误,这表示群集中节点之间的网络通信出现了问题。 若要解决此错误,请在训练代码中添加以下代码片段,以使用主网络接口。import os os.environ["OMPI_MCA_btl_tcp_if_include"]="eth0" os.environ["NCCL_SOCKET_IFNAME"]="eth0"