本页介绍 Databricks Lakeflow Connect 中的标准连接器,与托管连接器相比,该连接器提供更高级别的引入管道自定义。
ETL 堆栈各层
某些连接器在 ETL 堆栈的一个级别运行。 例如,Databricks 为 Salesforce 等企业应用程序提供完全托管的连接器,以及 SQL Server 等数据库。 其他连接器在 ETL 堆栈的多层上运行。 例如,你可以在结构化流中使用标准连接器以实现完全自定义,或者使用 Lakeflow Spark 声明性管道来获得更便捷的托管体验。
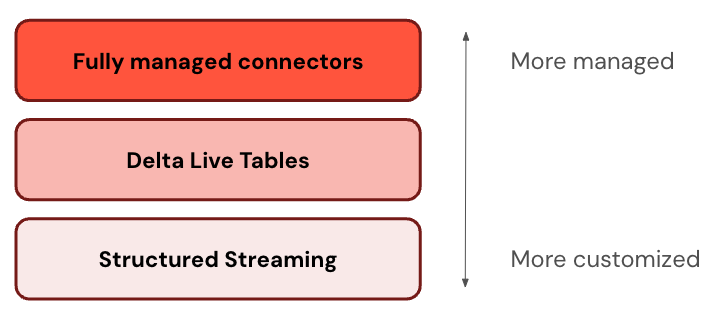
Databricks 建议从最托管层开始。 如果它不满足你的要求(例如,如果它不支持数据源),请下拉到下一层。
下表描述了从最可自定义到最托管的引入产品的三个层:
| 层 | Description |
|---|---|
| 结构化数据流 | Apache Spark 结构化流式处理是一个流式处理引擎,它使用 Spark API 提供端到端容错和“恰好一次”处理保证。 |
| Lakeflow Spark 声明式管道 | Lakeflow Spark 声明性管道基于结构化流式处理构建,提供用于创建数据管道的声明性框架。 可以定义要对数据执行的转换,Lakeflow Spark 声明性管道管理业务流程、监视、数据质量、错误等。 因此,它提供比结构化流式处理更多的自动化和更少的开销。 |
选择连接器
下表列出了数据源和管道自定义级别的标准引入连接器。
从云对象存储进行增量引入的 SQL 示例使用 CREATE STREAMING TABLE 语法。 它为 SQL 用户提供了一种可扩展且可靠的引入体验,因此建议使用 COPY INTO 作为替代方案。
| 来源 | 更多自定义 | 部分个性化设置 | 更多自动化 |
|---|---|---|---|
| 云对象存储 |
自动加载程序结合结构化流式处理 (Python、Scala) |
与 Lakeflow Spark 声明性管道一起使用的自动加载器 (Python、SQL) |
使用 Databricks SQL 的自动加载器 (SQL) |
| SFTP 服务器 |
从 SFTP 服务器引入文件 (Python、SQL) |
N/A | N/A |
| Apache Kafka |
采用 Kafka 源的结构化流式处理 (Python、Scala) |
使用 Kafka 源的 Lakeflow Spark 声明性管道 (Python、SQL) |
采用 Kafka 源的 Databricks SQL (SQL) |
| Apache Pulsar |
使用 Pulsar 源的结构化流式处理 (Python、Scala) |
Lakeflow Spark 使用 Pulsar 源的声明式管道 (Python、SQL) |
采用 Pulsar 源的 Databricks SQL (SQL) |
引入计划
可以将引入管道配置为按定期计划运行或持续运行。
| 用例 | 管道模式 |
|---|---|
| 批量摄取 | 触发:按计划或手动触发时处理新数据。 |
| 流式引入 | 连续:在到达源时处理新数据。 |