本文介绍批处理和流式处理之间的主要差异、用于数据工程工作负荷的两种不同的数据处理语义,包括引入、转换和实时处理。
流式处理通常与消息总线(如 Apache Kafka)的低延迟和连续处理相关联。
但是,在 Azure Databricks 中,它具有更广阔的定义。 Lakeflow Spark 声明性管道(Apache Spark 和结构化流式处理)的基础引擎具有用于批处理和流式处理的统一体系结构:
- 引擎可以将 云对象存储和Delta Lake 等源视为流式处理源,以便进行高效的增量处理。
- 流式处理可以同时以触发和连续的方式运行,从而灵活地控制流式处理工作负载的成本和性能权衡。
下面是区分批处理和流式处理的基本语义差异,包括它们的优缺点,以及为工作负荷选择它们的注意事项。
批处理语义
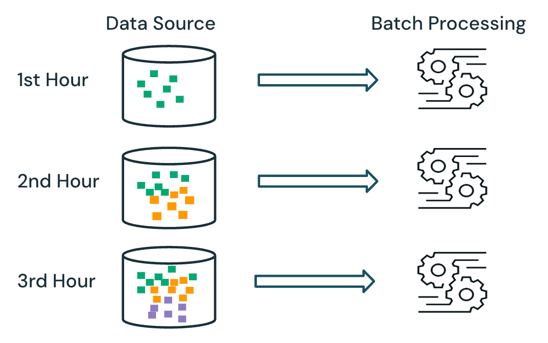
通过批处理,引擎不会跟踪源中已处理的数据。 处理时会处理源中当前可用的所有数据。 实际上,批处理数据源通常按逻辑进行分区,例如按天或区域来限制数据重新处理。
例如,计算按每小时粒度聚合的平均商品销售价格,以按小时粒度计算电子商务公司运行的销售事件,可以计划为批处理来计算每小时的平均销售价格。 使用批处理时,每小时重新处理前几小时的数据,并覆盖以前计算的结果以反映最新结果。
流式处理语义
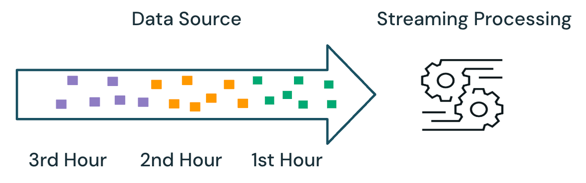
通过流处理,引擎会跟踪正在处理的数据,并且只会在后续运行中处理新数据。 在上面的示例中,可以计划流式处理而不是批处理,以计算每小时的平均销售价格。 使用流式处理时,仅处理自上次运行以来添加到源的新数据。 新计算的结果必须追加到之前计算的结果,才能检查完整的结果。
批处理与流式处理
在上面的示例中,流式处理优于批处理,因为它不会处理在以前的运行中处理的相同数据。 但是,流式处理在源中无序和延迟到达数据等方案中会变得更加复杂。
延迟到达数据的一个示例是,如果第一小时的一些销售数据直到第二小时才到达源:
- 在批处理中,第一小时的延迟到达数据将与第二小时的数据以及第一小时的现有数据一起处理。 将使用延迟到达数据覆盖和更正前一小时内的上一个结果。
- 在流处理中,将从第一小时到达的延迟数据进行处理,而不会处理任何其他已处理的第一小时数据。 处理逻辑必须存储第一小时的平均计算中的总和和和信息,才能正确更新以前的结果。
当处理有状态(例如 联接、 聚合和 重复数据删除)时,通常会引入这些流式处理复杂性。
对于无状态流处理(例如从源追加新数据),处理无序和延迟到达数据不太复杂,因为延迟到达的数据可以追加到以前的结果中,因为数据到达源。
下表概述了批处理和流式处理的优点和缺点,以及支持 Databricks Lakeflow 中这两种处理语义的不同产品功能。
| 处理语义 | Pros | Cons | 数据工程产品 |
|---|---|---|---|
| Batch |
|
|
|
| 流媒体 |
|
|
|
Recommendations
下表概述了基于 奖牌体系结构各层数据处理工作负载的特征的建议处理语义。
| 奖牌层 | 工作负荷特征 | 建议 |
|---|---|---|
| 青铜 |
|
|
| 银 |
|
|
| 金 |
|
|