本页介绍如何使用 Unity 目录中的 Databricks 数据分类自动对目录中的敏感数据进行分类和标记。
数据目录可以包含大量数据,通常包含已知和未知的敏感数据。 数据团队必须了解每个表中存在的敏感数据类型,以便他们既可以管理对此数据的访问,也能实现访问的民主化。
为了解决此问题,Databricks 数据分类使用 AI 代理自动对目录中的表进行分类和标记。 这样,就可以使用 Unity 目录中的基于属性的访问控制等工具发现敏感数据并应用对结果的治理控制。
使用此功能,可以:
- 对数据进行分类:引擎使用代理 AI 系统自动对 Unity 目录中的任何表进行分类和标记。
- 通过智能扫描优化成本:系统利用 Unity 目录和数据智能引擎智能确定何时扫描数据。 这意味着扫描是增量扫描并经过优化,以确保所有新数据都分类,而无需手动配置。
- 查看和保护敏感数据:结果显示有助于查看分类结果,并通过标记和创建每个类的访问控制策略来保护敏感数据。
重要
Databricks 数据分类使用默认存储来存储分类结果。 不会为存储付费。
Databricks 数据分类使用大型语言模型(LLM)来帮助分类。
要求
- 工作区必须具有 可用的无服务器计算 (在具有 Unity 目录的工作区中默认启用)。
- 若要启用数据分类,必须拥有目录或对其拥有
USE CATALOG和MANAGE特权。 - 若要为目录启用自动标记,必须在目录上拥有
USE CATALOG,目录上拥有APPLY TAG,以及要应用的标记上拥有ASSIGN。 - 若要在 UI 中查看分类结果,必须在目录中具有
USE CATALOG或MANAGE(SELECT+USE SCHEMA)。 若要查看与检测关联的示例值,必须在SELECT具有这些值。
注释
默认情况下,只有帐户管理员对数据分类系统受管理标记拥有 MANAGE 和 ASSIGN 权限。 帐户管理员可以将对单个受管理标记的MANAGE和ASSIGN授予给其他用户、服务主体或组。 请参阅 管理受治理标记的权限。
使用数据分类
可以从结果页一次性为多个目录启用数据分类,或者使用更精细的架构级控制配置单个目录。
启用多个目录
- 在“数据分类结果”页上,单击“ 配置”。
- 选择要启用的目录,或选择工作区中的所有可用目录。
- 单击 “启用” 。
启用所有可用目录不会自动启用将来的目录。 若要对新目录进行分类,请返回到 “配置 ”对话框并启用它。
启用具有架构选择的单个目录表
若要在目录中选择特定架构,请执行以下操作:
导航到目录,然后单击“ 详细信息 ”选项卡。

在 数据分类旁边,单击“ 启用 ”按钮。
此时会显示 “数据分类 ”对话框。 默认情况下,包括所有架构。 要仅包含某些架构,请在“要包含的架构”下拉菜单中选择它们。 还可以选择 使用情况策略
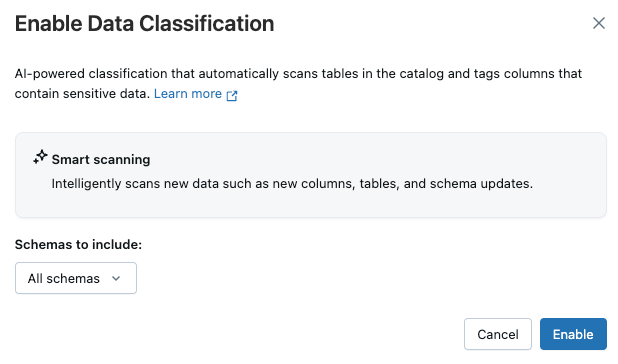
单击“ 保存”。
这会创建一个后台作业,该作业以增量方式扫描目录或所选架构中的所有表。
分类引擎依赖于智能扫描来确定何时扫描表。 目录中的新表和列通常在创建后的 24 小时内扫描。
查看分类结果
若要查看分类结果,请单击“数据分类”设置旁边的“查看结果”。

这将打开目录的数据分类用户界面。 若要查看分类结果,需要无服务器 SQL 仓库。
还可以使用左上角的目录选择器查看元存储中所有分类目录的聚合结果。 从下拉菜单中选择 “所有目录 ”。
对于每个分类类型,表显示:
- 检测到的列:检测到分类的列数。
- 自动标记:该分类的标记状态 - 活动 或 非活动状态。 在元存储视图中, “部分活动 ”状态指示某些目录(而不是所有目录)中启用了标记。
- 用户访问(过去 7 天):在过去 7 天内访问该分类中未掩码数据与掩码数据的不同用户数。 使用此工具评估整个组织中敏感数据的暴露情况。

审查检测
若要查看特定分类类型的结果,请单击最右侧列中的 “审阅 ”。 此时会显示一个面板,其中包含两个选项卡:
- 检测到的列:显示分类标记以高置信度检测到的列,先按最新检测进行排序。 还包括检测随时间变化的图表和一个包含样本值的检测列列表。 单击图表中的任意条形以查看该日期的具体检测结果。 仅当具有查看分类结果所需的权限时,才会显示示例值。
- 用户访问:列出使用此分类标记访问列的所有用户,并显示其电子邮件和用户名以及他们是否已屏蔽或未屏蔽访问权限。
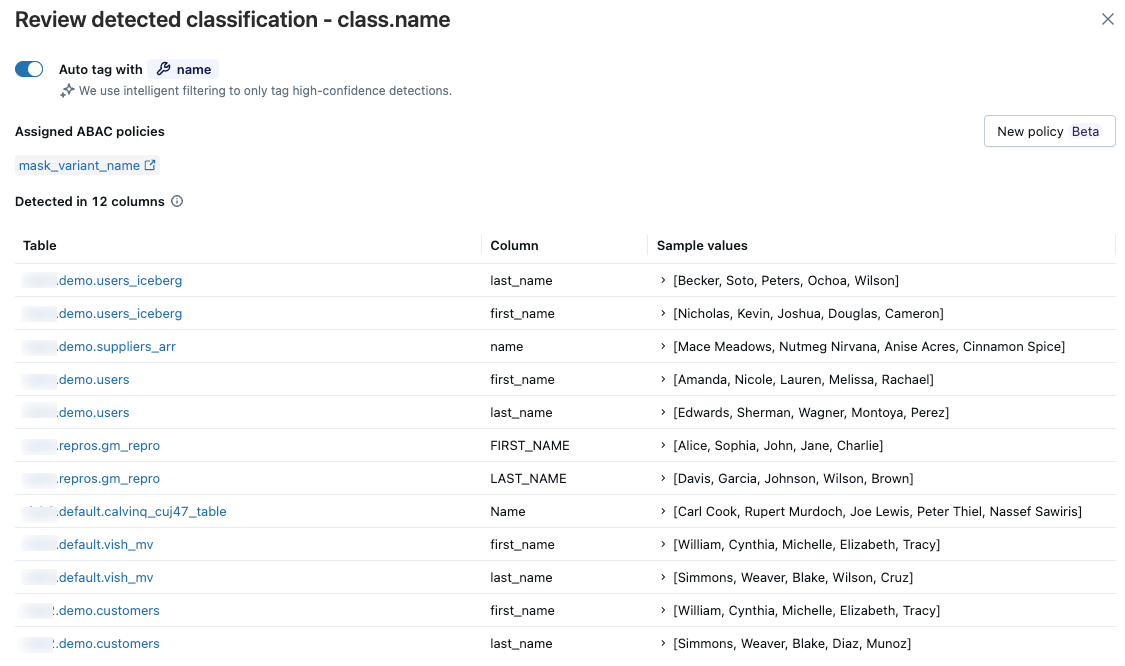
如果检测到的任何列不正确,则可以单击条目右侧的 “排除 ”图标。 请参阅 “排除检测”。
启用自动标记
如果标识的列符合预期,则可以为分类标记启用自动标记。 启用自动标记后,此分类的所有现有和未来检测项目都会被标记。
可以在两个级别配置自动标记:
- Metastore 级别:一次性启用或禁用所有分类目录。 必须是元数据存储管理员,并且需要对正在应用的标记有权限。
-
目录级别:仅对当前目录启用或禁用。 目录级设置优先于元存储级别设置。 必须在目录中具有
USE CATALOG和APPLY TAG,并在被应用的标记中具有ASSIGN。
在目录级别,自动标记有三种状态:
- 默认值(继承):目录从元存储级别继承标签设置。
- 活动:无论元存储级别设置如何,都会为此目录显式启用标记。
- 禁用:无论元存储级别设置如何,此目录的标记功能均已显式禁用。
禁用标记时,不会应用将来的标记,但不会删除现有标记。
注释
启用自动标记功能时,标签不会被立即回填。 它们将在下一次扫描中被生成,并应在24小时内生效。 后续的分类将会被立即标记。
排除检测结果
重要
用于提高未来分类准确性的检测排除项及其应用目前处于 Beta 版。
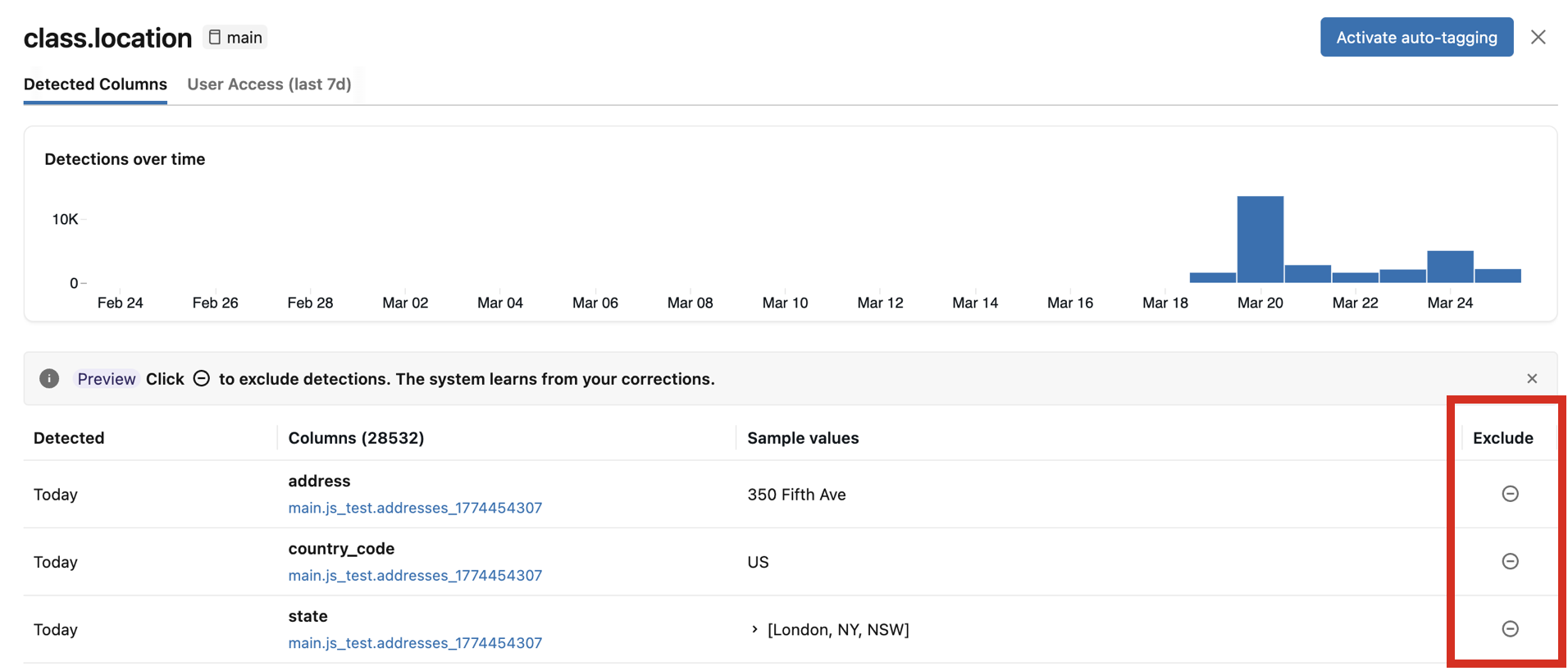
在审阅面板中,可以排除单个列检测。 排除检测:
- 从该列中删除任何现有分类标记。
- 防止将来的扫描将标记重新应用到该列。
- 提供反馈,以提高未来分类结果的准确性。
若要排除检测,请单击审阅面板中相应列的 “排除 ”图标。 若要重新包含检测,请再次单击该图标。
结果系统表
数据分类创建一个名为存储结果的系统表 system.data_classification.results ,默认情况下只能由帐户管理员访问。帐户管理员可以共享此表。 仅当使用无服务器计算时,才能访问该表。 有关此表的详细信息,请参阅 数据分类系统表参考。
重要
结果表 system.data_classification.results 包含整个元存储中的所有分类结果,并包括每个目录中表的示例值。 应仅与有权查看元存储范围的分类结果(包括示例值)的用户共享此表。
有权 SELECT 访问此表的用户还可以在“数据分类结果”页上查看与检测关联的示例值。
如何处理错误的标记
如果分类不正确,请从审核面板中排除检测结果。 排除某次检测会去除标记,防止其被重新应用,并提高未来扫描的准确性。 请参阅 “排除检测”。
扫描错误
如果在扫描期间发生任何错误,结果表右上角会显示“ 错误” 按钮。

单击该按钮可显示扫描失败的表和关联的错误消息。

默认情况下,将跳过单个表发生的失败,并在第二天重试。
查看数据分类费用
若要了解如何对数据分类计费,请参阅 定价页。 可以通过运行查询或查看使用情况仪表板来查看与数据分类相关的费用。
注释
初始扫描的成本高于同一目录中的后续扫描,因为这些扫描是增量扫描,通常会产生更低的成本。
查看系统表 system.billing.usage 的使用情况
可以从中查询数据分类费用 system.billing.usage。 字段 created_by 和 catalog_id 可用于分解成本的可选方法:
-
created_by:包括查看触发使用情况的用户的成本。 -
catalog_id:包括按目录查看成本。system.data_classification.results目录 ID 显示在表中。
过去 30 天的示例查询:
SELECT
usage_date,
identity_metadata.created_by,
usage_metadata.catalog_id,
SUM(usage_quantity) AS dbus
FROM
system.billing.usage
WHERE
usage_date >= DATE_SUB(CURRENT_DATE(), 30)
AND billing_origin_product = 'DATA_CLASSIFICATION'
GROUP BY
usage_date,
created_by,
catalog_id
ORDER BY
usage_date DESC,
created_by;
若要计算总美元成本,请使用system.billing.list_prices。 以下示例查询使用命名参数 :add_on_rate 作为标价上的乘数。 将其设置为 1 以直接使用标价,或设置为小于 1 的值以反映协商折扣(例如,0.9 的 10% 折扣)。
过去 30 天内总美元成本的示例查询:
SELECT
u.usage_date,
SUM(u.usage_quantity * lp.pricing.effective_list.default) * :add_on_rate
AS `Data Classification Dollar Cost`
FROM system.billing.usage AS u
JOIN system.billing.list_prices AS lp
ON lp.sku_name = u.sku_name
WHERE
u.billing_origin_product = 'DATA_CLASSIFICATION'
AND u.usage_end_time >= lp.price_start_time
AND (lp.price_end_time IS NULL OR u.usage_end_time < lp.price_end_time)
AND u.usage_date >= DATE_ADD(CURRENT_DATE(), -30)
GROUP BY
u.usage_date
ORDER BY
u.usage_date DESC;
从使用情况仪表板查看使用情况
如果工作区中已配置了使用情况仪表板,则可以通过选择标记为“数据分类”的计费源项目来筛选使用情况。 如果未配置使用情况仪表板,可以导入一个仪表板并应用相同的筛选。 有关详细信息,请参阅 使用情况仪表板。
局限性
- 不支持视图和 指标视图 。 如果视图基于现有表,Databricks 建议对基础表进行分类,以查看它们是否包含敏感数据。